Adventure Works Cycles公司月度销售情况分析报告总结
目录
一、背景介绍
二、数据源
三、分析流程
四、分析框架
五、知识点总结
1、python连接mysql的方法
2、查看数据类型的几种方式
3、时间转字符串类型等,延伸时间函数总结
4、DataFrame中存在科学计数法
5、计算上下两行之间相除或相乘等一系列方法的函数使用方法罗列
6、总结DataFrame与Series类型区别
7、总结DataFrame专用的排序函数和列表的排序函数
8、总结存储到mysql的几种形式(覆盖、追加等)
9、总结DataFrame的去重方法
10、总结Series转化为列表的方式
11、总结Series与List的区别
12、总结append\extend等列表追加元素的区别及适用范围
13、函数agg的用法及适用范围
14、DataFrame中的loc,iloc,at,iat,ix的用法和区别
**15、利用pct_change()函数实现环比效果
16、多个DataFrame存在时,如何合并,有哪些方法,主键名字不同时如何处理
17、DataFrame修改列名、索引的用法总结
一、背景介绍
Adventure Works Cycles是基于微软AdventureWorks示例数据库的虚拟公司,是一家大型跨国制造公司。该公司向北美,欧洲和亚洲商业市场生产和销售金属和复合材料自行车。2019年12月业务部门需要向上级汇报11月份的自行车销售情况,为精细化运营提供数据支持,精准定位目标客户群体。
二、数据源
报告用到的3个表格及字段解释:
- ods_sales_orders:订单明细表(一个订单表示销售一个产品)

- dw_customer_order:产品销售信息事实表
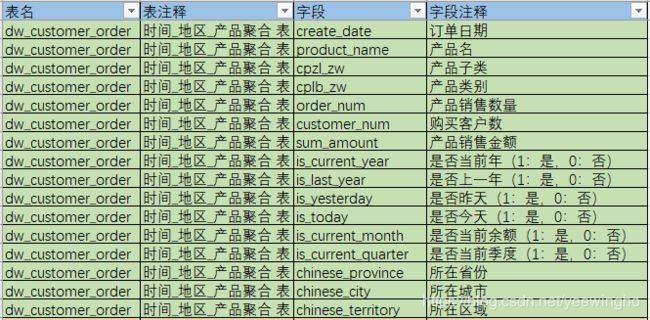
- ods_customer:用户信息表

三、分析流程
1. 探索数据库,罗列分析指标
2. 使用jupyter notebook提取数据库数据,进行数据处理
3. 将处理好的数据存入数据库中方便可视化
4. Power BI连接数据库,将处理好的数据表可视化
5. 制作ppt
四、分析框架
零售行业的月度销售情况分析可以按照人、货、场的框架,分别从整体销售情况、用户角度、产品角度和地域角度,分析几个重要主指标的环比及变化趋势。由于细分维度多,搭配形成的分析指标太多,需要针对汇报对象调整侧重点,向上级汇报不需要展示过多子指标,主要关注销售额和销售量这类主指标,适当加入维度;向业务部门提供数据时,可以拆分多一些维度,给运营提供更多角度的信息。
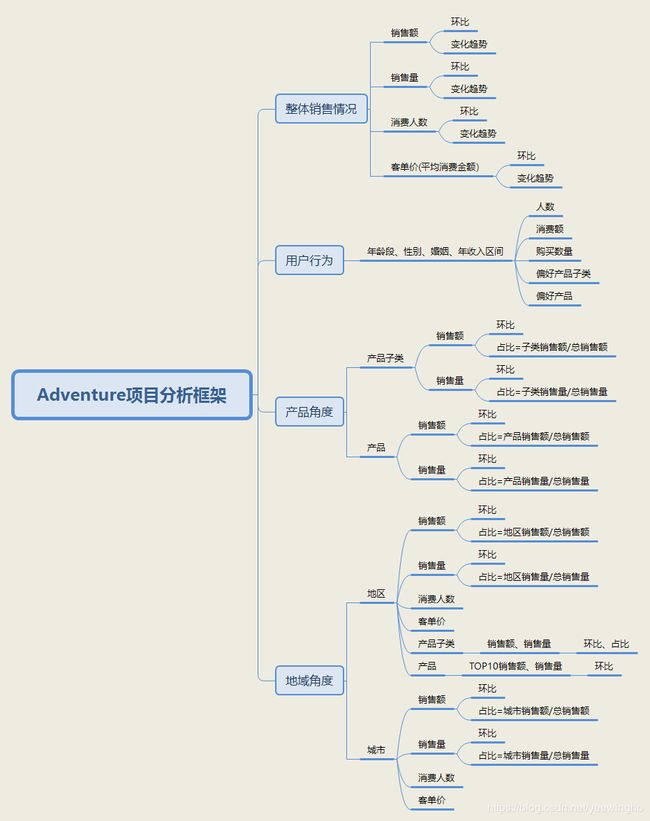 项目分析框架
项目分析框架
五、知识点总结
1、python连接mysql的方法
python连接mysql的简单方法(sqlalchemy+pymysql)
2、查看数据类型的几种方式
-
df.info()
-
df.dtypes
-
df['A'].dtypes
-
type(df.iloc[0,0])
3、时间转字符串类型等,延伸时间函数总结
(1)首先查看数据格式,是datetime,还是str

(2)时间转字符串:strftime()函数
字符串转时间:strptime()函数

4、DataFrame中存在科学计数法
#取消科学计数法显示
import numpy as np
np.set_printoptions(suppress=True, threshold=np.nan)
#对于dataframe
pd.set_option('display.float_format', lambda x: '%.3f' % x) #保留三位小数https://blog.csdn.net/weixin_40309268/article/details/83579381
5、计算上下两行之间相除或相乘等一系列方法的函数使用方法罗列
- diff() 函数,两行之间做差
pandas常用函数之diff
- 通用方法:shift() 函数,相邻两行进行加减乘除
先shift(),将一列所有数据向上或向下平移,再进行加减乘除
6、总结DataFrame与Series类型区别
- 区别:
series,只是一个一维数据结构,它由index和value组成。
dataframe,是一个二维结构,除了拥有index和value之外,还拥有column。
- 联系:
dataframe由多个series组成,无论是行还是列,单独拆分出来都是一个series。
参考文章:https://blog.csdn.net/missyougoon/article/details/83301712
7、总结DataFrame专用的排序函数和列表的排序函数
dataframe专用:.sort_index()、.sort_values()
list和dataframe均可:.sort()
8、总结存储到mysql的几种形式(覆盖、追加等)
dataframe.to_sql ( 表名, engine, if_exists = , index = False )
如果表格已经存在的情况下,有三种处理方法:
if_exists : {'fail', 'replace', 'append'}, default 'fail'
How to behave if the table already exists.
- * fail: Raise a ValueError.
- * replace: Drop the table before inserting new values.
- * append: Insert new values to the existing table.
9、总结DataFrame的去重方法
.drop_duplicates和duplicated()如果不指定列,会判断整行是否相同
-
data.drop_duplicates(subset='列名',keep='first',inplace=True)
-
data.duplicated() 返回一个布尔型的series,显示各行是否有重复行,没有重复行显示为FALSE,有重复行显示为TRUE
-
unique()
10、总结Series转化为列表的方式
-
Series.tolist()
-
list(Series)
参考文章:tolist()和list()的区别
11、总结Series与List的区别
Series可以看成是有索引的list
有关python常见的数据结构之间的差异,参考文章:【python】list、tuple、dict、set、dataframe、narray、series之间的区别
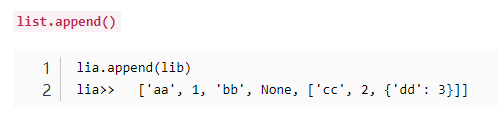
12、总结append\extend等列表追加元素的区别及适用范围
-
list.extend() 把一个序列seq的内容添加到列表中:
extend若为列表将列表元素,在尾部逐一加入,若为字典是将字典key值,在尾部逐一加入


-
list.append() 向列表中添加一个对象:
append是将整个对象在末尾加入
13、函数agg的用法及适用范围
一般跟groupby联合使用,与apply的最大区别是,agg可以对同一列进行多个聚合函数操作,也可以对不同列使用不同的聚合函数操作
14、DataFrame中的loc,iloc,at,iat,ix的用法和区别
总结:ix已经弃用
-
1、 loc和iloc函数都是用来选择某行的,iloc与loc的不同是:iloc是按照行索引所在的位置来选取数据,参数只能是整数。而loc是按照索引名称来选取数据,参数类型依索引类型而定;
-
2、 at和iat函数是只能选择某个位置的值,iat是按照行索引和列索引的位置来选取数据的。而at是按照行索引和列索引来选取数据;
-
3、 loc和iloc函数的功能包含at和iat函数的功能。
参考文章: pandas DataFrame的查询方法(loc,iloc,at,iat,ix的用法和区别)
**15、利用pct_change()函数实现环比效果
pandas 中的pct_change的用法
16、多个DataFrame存在时,如何合并,有哪些方法,主键名字不同时如何处理
-
pd.merge()
-
pd.concat()
-
df1.append([df2,df3]) 不会修改df1,而是生成copy
参考文章:python DataFrame的合并方法总结
官方文档:Merge, join, and concatenate
17、DataFrame修改列名、索引的用法总结
一般常用的有两个方法:
1、使用DataFrame.index = [newName],DataFrame.columns = [newName],这两种方法可以轻松实现。
2、使用rename方法(推荐):
DataFrame.rename(mapper = None,index = None,columns = None,axis = None,copy = True,inplace = False,level = None )
参数介绍:
mapper,index,columns:可以任选其一使用,可以是将index和columns结合使用。index和column直接传入mapper或
字典的形式。
axis:int或str,与mapper配合使用。可以是轴名称(‘index’,‘columns’)或数字(0,1)。默认为’index’。
copy:boolean,默认为True,是否复制基础数据。
inplace:布尔值,默认为False,是否返回新的DataFrame。如果为True,则忽略复制值。
参考文章:pandas中DataFrame修改index、columns名的方法