史上最简单的spark教程第二章-快速开发部署你的第一个Java+spark程序
spark的核心概念
史上最简单的spark教程
所有代码示例地址:https://github.com/Mydreamandreality/sparkResearch
(提前声明:文章由作者:张耀峰 结合自己生产中的使用经验整理,最终形成简单易懂的文章,写作不易,转载请注明)
(文章参考:Elasticsearch权威指南,Spark快速大数据分析文档,Elasticsearch官方文档,实际项目中的应用场景)
(帮到到您请点点关注,文章持续更新中!)
Git主页 https://github.com/Mydreamandreality
第一章的shell程序是如何运行的?下面给大家解释一波
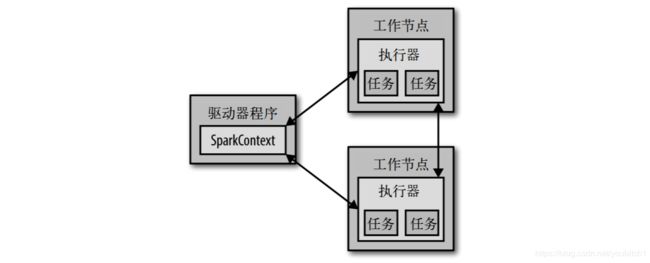
- 从上层看,每个spark应用都由一个驱动器程序(driver program)发起集群上的并行操作
- 驱动器程序包含了应用的main函数,并且定义了集群上的分布式数据集,并对这些数据集进行相关的操作
- 之前运行的那个shell栗子,驱动器程序就是spark.shell本身.所以我们只需要输入我们需要做的操作就可以了
- 驱动器程序通过SparkContext对象访问spark,sparkContext代表对计算集群连接的一个连接,shell启动的时候会自动创建,就是我们操作的sc变量,在控制台输入
sc可以查看它的类型 - 只要有了sparkContext我们就可以创建RDD,然后进行我们的操作,要执行这些操作,sc一般要管理多个执行器节点,如果我们刚才的count()是在集群中运行,那么不同的节点就会计算文件不同的行数,我们刚才的运行模式是单机模式
- 集群运行模式如下:
扩展我们的SparkShell程序
- 第一章我们运行的count()或者first()都是内置好的函数,无需我们控制任何参数,我就找了些可以传递参数的Api,运行到我们的节点上
- 事例:从README.md RDD中筛选特定的单词
- 代码示例
val lines = sc.textFile("你的README文件路径") // 创建一个叫lines的RDD lines:
val pythonLines = lines.filter(line => line.contains("Python")) //lambda语法糖
pythonLines.first() //输出第一行包含python的文本
- 其实 Spark API 最神奇的地方就在于像 filter 这样基于函数的操作也会在集群上并行执行,也就是说,Spark 会自动将 函数(比如 line.contains(“Python”))发到各个执行器节点上,这样就可以在单一的驱动器程序中编码,并且让代码自动运行在多个节点上
java运行第一个spark程序
之前我们一直都是以交互式案例了解spark的运行机制,除了交互式运行之外,spark也可以在Java,scala,Python的独立程序中被连接使用,独立程序中运行就是需要自行初始化SparkContext,其他的都是一样的概念
- 在Java中运行Spark需要添加spark-core的maven依赖. 个人使用的版本为:2.2.3
- Maven就不解释了,Java开发中比较流行的包管理工具,直接开始创建我们的项目吧
开发工具:Intellij IDEA
Java版本:JDK1.8以上
首先创建Maven工程
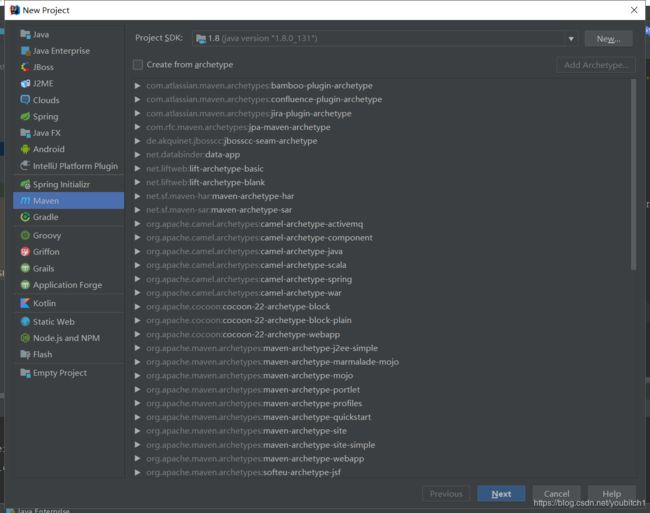
创建好之后在pom.xml文件中添加我们需要的jar包:spark-core
2.2.3
org.apache.spark
spark-core_2.11
${spark.version}
provided
接着我们就可以开始编写我们的Spark代码
开始的时候我写了在java或者scala中编写spark程序需要我们手动创建sparkcontext
第一步先初始化我们的SparkContext,初始化需要两个基本参数:[集群URL,应用名]
- 集群URL:告诉 Spark 如何连接到集群上,我们现在先使用local的模式,这个模式可以让Spark运行在单机单线程上而无需连接到集群
- 应用名:我使用的是sparkBoot,当连接到一个集群时.这个值可以帮助你在集群管理器的用户界面中找到你的应用
SparkConf sparkConf = new SparkConf().setAppName("sparkBoot").setMaster("local");
JavaSparkContext sparkContext = new JavaSparkContext(sparkConf);
在初始化 SparkContext 之后,我们可以使用前面展示的所有方法(比如利用文本文件)来创建 RDD 并操控它们
package web;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.*;
import java.util.regex.Pattern;
/**
* Created by 張燿峰
* wordcount案例测试
* @author 孤
* @date 2019/3/11
* @Varsion 1.0
*/
public class SparkApplication {
private static final Pattern SPACE = Pattern.compile(" ");
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf().setAppName("sparkBoot").setMaster("local");
JavaSparkContext sparkContext = new JavaSparkContext(sparkConf);
JavaRDD lines = sparkContext.textFile("/usr/local/data").cache();
lines.map(new Function() {
@Override
public Object call(String s) {
return s;
}
});
JavaRDD words = lines.flatMap(new FlatMapFunction() {
@Override
public Iterator call(String s) {
return Arrays.asList(SPACE.split(s)).iterator();
}
});
JavaPairRDD wordsOnes = words.mapToPair(new PairFunction() {
@Override
public Tuple2 call(String s) {
return new Tuple2(s, 1);
}
});
JavaPairRDD wordsCounts = wordsOnes.reduceByKey(new Function2() {
@Override
public Integer call(Integer value, Integer toValue) {
return value + toValue;
}
});
wordsCounts.saveAsTextFile("/usr/local/data1");
}
}
然后在这说一下这个代码的运行过程
- 首先我们创建一个名叫lines的RDD,文件路径为/usr/local/data PS{这是我服务器存放数据文件的位置,首先需要保证这个文件存在}
- lines.map函数将原数据的每个元素传给函数func进行格式化,返回一个新的分布式数据集
- lines.flatMap函数将所有的原始元素传给函数func进行格式化
- SPACE.split(s)将每个元素用空格分割,返回类型为iterator
- words.mapToPair函数在单词拆分基础上对每个单词实例计数为1
- reduceByKey函数把key相同的键值对通过value进行累加
- wordsCounts.saveAsTextFile("/usr/local/data1"); 把最后的统计结果写到新的文件中
- OK,到这里就实现了wordcount的功能
打包运行我们的程序
程序写好了,我们需要把spark运行起来
打包我们的代码:
在idea的控制台输入:mvn clean && mvn compile && mvn package
打包完之后会生成taregt目录,找到我们打包完的jar文件
把jar上传到linux服务器,在当前上传的目录执行以下命令:

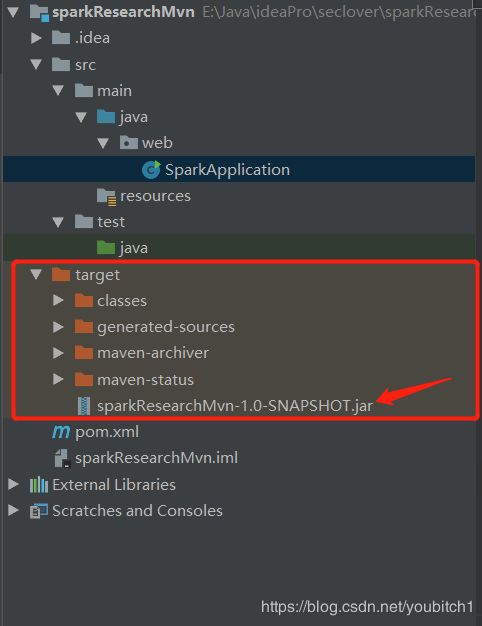
/usr/local/spark/spark-2.2.3-bin-hadoop2.7/bin/spark-submit --master local[3] --executor-memory 512m --class web.SparkApplication sparkResearchMvn-1.0-SNAPSHOT.jar
/usr/local/spark/spark-2.2.3-bin-hadoop2.7/bin/spark-submit 该路径为你安装spark的路径
–master local[3] 代表我们当前的执行环境是local
–executor-memory 512m 分配内存空间
–class web.SparkApplication 代码文件的路径
sparkResearchMvn-1.0-SNAPSHOT.jar 当前目录的jar程序名称
那么到此时我们的程序就应该运行成功了
然后进入到我设置的统计结果生成路径:cd /usr/local/data1 查看我的统计结果:cat part-00000
我的统计结果
(axasaklsfdhjiewjhfoklewnlfhwrklfrelkwsfjlsdjnglkjsdlkfmlkdsjfglkdsjlgkxxxxxcccWQEWQEWQE,22)
(3213321321321321,22)
(axasaklsfdhjiewjhfoklewnlfhwrklfrelkwsfjlsdjnglkjsdlkfmlkdsjfglkdsjlgkxxxxxccc123WERFEWR,22)
(axasaklsfdhjiewjhfoklewnlfhwrklfrelkwsfjlsdjnglkjsdlkfmlkdsjfglkdsjlgkxxxxxcccEWREWR,22)
(axasaklsfdhjiewjhfoklewnlfhwrklfrelkwsfjlsdjnglkjsdlkfmlkdsjfglkdsjlgkxxxxxccc21321321,2)
(axasaklsfdhjiewjhfoklewnlfhwrklfrelkwsfjlsdjnglkjsdlkfmlkdsjfglkdsjlgk,27307)
(axasaklsfdhjiewjhfoklewnlfhwrklfrelkwsfjlsdjnglkjsdlkfmlkdsjfglkdsjlgkxxxxxccc,37228)
(,6)
(3213213213,22)
(axasaklsfdhjiewjhfoklewnlfhwrklfrelkwsfjlsdjnglkjsdlkfmlkdsjfglkdsjlgkxxxxxccc14213,22)
(axasaklsfdhjiewjhfoklewnlfhwrklfrelkwsfjlsdjnglkjsdlkfmlkdsjfglkdsjlgkxxxxxcccPPP1231,1855)
(axasaklsfdhjiewjhfoklewnlfhwrklfrelkwsfjlsdjnglkjsdlkfmlkdsjfglkdsjlgkxxxxxccc213213,48)
(axasaklsfdhjiewjhfoklewnlfhwrklfrelkwsfjlsdjnglkjsdlkfmlkdsjfglkdsjlgkxxxxxccc3213,22)
(axasaklsfdhjiewjhfoklewnlfhwrklfrelkwsfjlsdjnglkjsdlkfmlkdsjfglkdsjlgkxxxxxcccQWEWQE,44)
(axasaklsfdhjiewjhfoklewnlfhwrklfrelkwsfjlsdjnglkjsdlkfmlkdsjfglkdsjlgkxxxxxccc123213,22)
OK,到这里你的第一个java的spark程序就已经成功运行部署了,
后续还会继续更新spark和elasticsearch的一些教程和学习过程
不懂的或者采坑的地方可以留言一起交流学习!
后续补充
刚才拿java8的lambda表达式重新优化了下代码,感觉更简洁了,可读性的话只要懂lambda就能看懂:
