AI、Big Data、Cloud学习路线之百度智能云ABC初级认证(百度云智学院学习笔记)
2020年4月30日前可免费在线学习考取百度智能云ABC(初级)认证,下面是我在准备时的学习笔记,供大家参考学习,希望大家能取得好成绩!
本课程中,您将学习到: 人工智能发展历史 | 人工智能产业结构和场景应用 | 人工智能关键技术 | 大数据技术介绍 | 百度智能云BOS核心概念 | 百度智能云LSS基础概念 | CND | BCC | VPC | 区块链发展现状及应用 | 智能客服

课程链接:
http://abcxueyuan.cloud.baidu.com/#/news_page?id=76
- 人工智能
人工智能发展历史
人工智能产业结构和场景应用
人工智能关键技术体系 - 大数据
大数据基础
大数据处理技术 - 云计算
百度智能云BOS核心概念
百度智能云LSS基础概念
云原生概念解析及实践应用解析
CDN
BCC
EIP
VPC - 区块链
区块链发展现状及应用
ABC 技术垂直应用之智能客服 - 动手实验
人工智能实验入门
智慧卫生-智能垃圾分类实验

人工智能
人工智能发展历史
智能的理解:
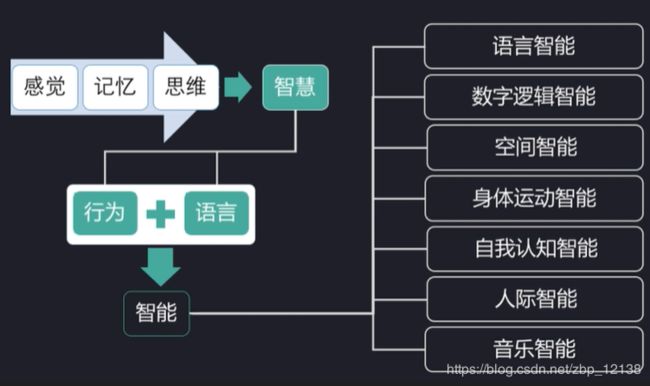
人工智能的理解:
图灵测试:即一个人在不接触对方的情况下,通过一种特殊的方式,和对方进一系列的问答,如果在相当长时间内,他无法根据这些问题判断对方是人还是计算机,那么,就可以认为这个计算机具有同人相当的智力,即这台计算机是能思维的。

我们要尽可能避免做这些"进水”的工作,以免被日后所淘汰掉:

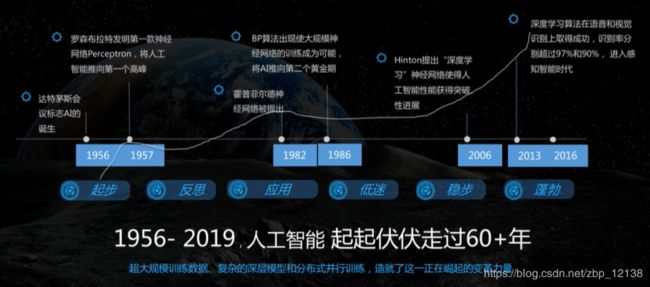
人工智能发展曲线:
人工智能产业结构和场景应用
人工智能高速发展的原因:

百度人工智能发展:

ABC3.0:
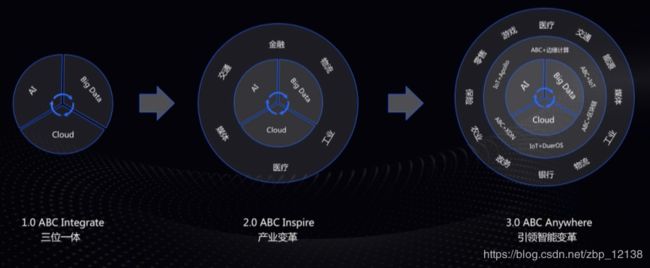
人工智能引领产业智能变革:

划重点!这是考点!
人工智能关键技术体系
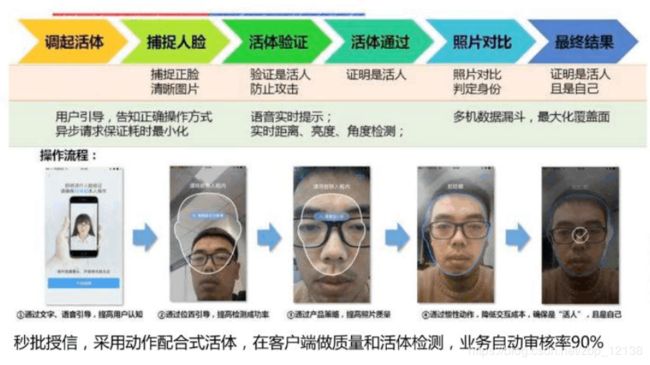
人脸识别:

1:1的问题:

1:N的问题:

人证对比:

互联网金融:
安防交通:

公安交警:

大数据
大数据基础
国家层面:
- 大数据是信息化发展的新阶段。
- 要推动大数据技术产业创新发展。
- 要构建以数据为关键要素的数字经济。
- 要运用大数据提升国家治理现代化水平。
- 要运用大数据促进保障和改善民生。
天文大数据:
LIGO每天运行产生的数据都在TB量级,每天收集的数据都会被及时传输到超级计算机中进行存储和处理。
目前LIGO获得的数据已经超过4.5PB(1PB=1024TB)。且以每年0.8PB的速度递增。
LIGO2015年全年的数据如果使用普通的四核计算机进行运算需要超过1000年。
LIGO (借助于激光干涉仪来聆听来自宇宙深处引力波的大型研究仪器)
大数据透视社会历史:
大数据在认识人类语言、历史、名望、记忆和文化等方面的透视作用,在宏大的人文视角下,用“冰冷”的数据将人类文化“鲜活”地呈现在我们面前。
大数据的历史渊源:

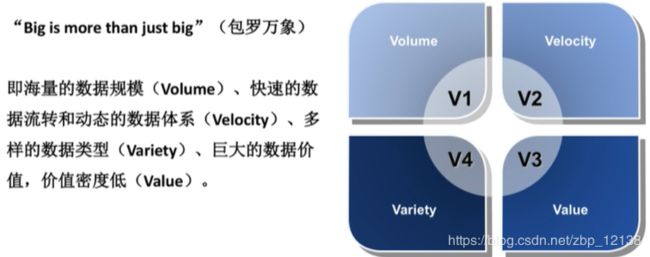
大数据的多版本概念:
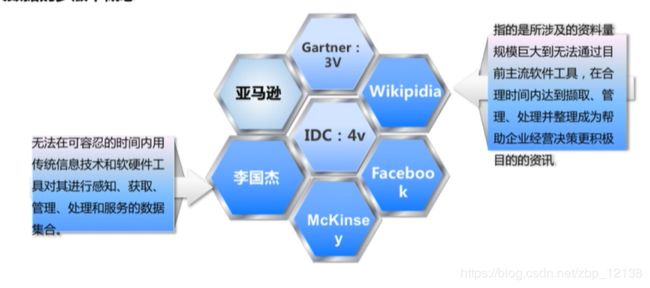
大数据的内涵:
数据的分类:

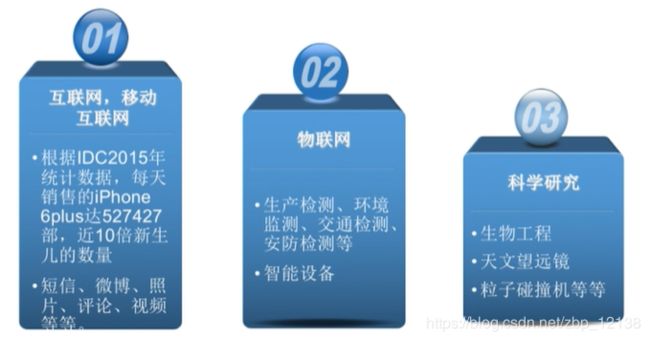
大数据从哪里来:

大数据处理技术
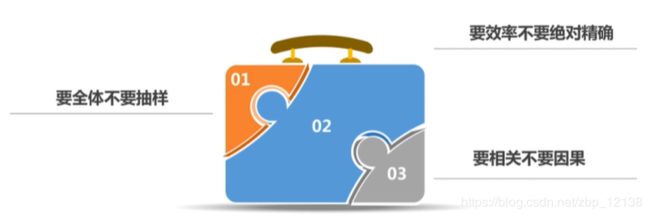
大数据时代的数据处理理念:
大数据的利用过程:

大数据处理技术:
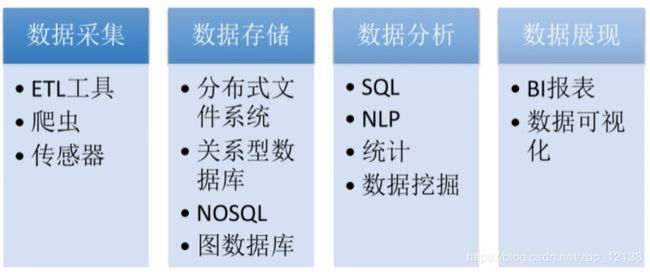
数据采集:

数据存储:




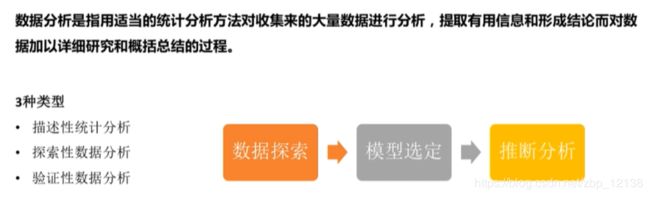
数据分析:
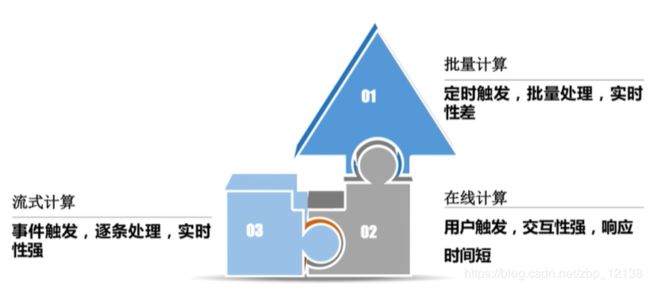
大数据计算场景:
Lambda:
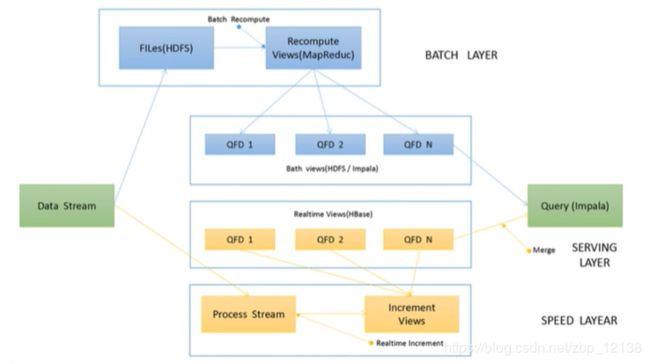
Kappa架构:
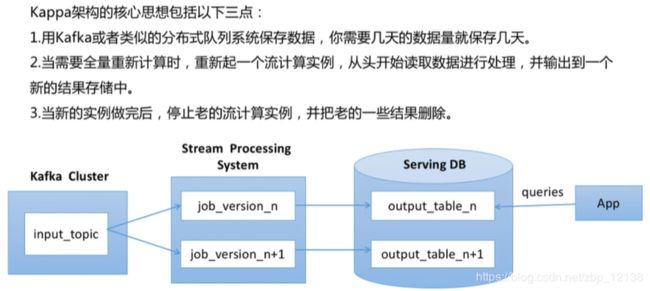
对比:

Summingbird混合架构:

云计算
百度智能云BOS核心概念
在BOS中,用户操作的基本数据单元是Object。每个Object包含Key、Meta和Data。其中,Key是Object的名字;Meta是用户对该Object的描述,由一系列Name-Value对组成;Data是Object的数据。
Bucket是存放数据的容器,可以当成是存储桶。Bucket具有区域属性,只能位于一个区域。因为Bucket名称创建后不能修改名称和所属区域,所以建议根据业务情况就近存储,方便上传和下载以提高访问速度。Bucket名称具有全局唯一性。每个Object必须都包含在某个Bucket中。一个用户最多可创建100个Bucket,但每个Bucket中存放的Object的数量和大小总和没有限制,用户不需要考虑数据的可扩展性。
Referer白名单即准入列表,是一种基于HTTP header referer字段的防盗链方法,目的是防止用户存储在BOS上的数据被其他人盗链。用户可以通过BOS控制台设置Referer字段的白名单。设置白名单后,只有Referer字段在白名单内的用户才可以访问Bucket中存储的数据,不在白名单内的请求会被拒绝。但如果用户的Referer为空,默认可以访问,不受白名单限制。
Region代表一个独立地域。百度智能云中的服务除了极少数如账号服务全局有效之外,绝大部分服务都是区域间隔离的。每个区域的服务独立部署互不影响。服务间共享数据需要通过显式拷贝完成。
百度智能云目前开放了多区域支持,请参考区域选择说明:
在API中引用区域必须使用其对应区域的服务域名
区域 服务域名
北京 bj.bcebos.com
保定 bd.bcebos.com
苏州 su.bcebos.com
广州 gz.bcebos.com
香港 hkg.bcebos.com
金融云武汉专区 fwh.bcebos.com
金融云上海专区 fsh.bcebos.com
用户在访问的BOS服务的时候,可以通过URL指定请求落到哪个Region,例如:http(s)/bj.bcebos.com将会把请求落到北京。
用户开通BOS服务后,系统会自动分配一对 Access Key ID (AK)/ Secret Access Key(SK),该密钥对将在用户向BOS发起请求时用做签名验证。
Access Key ID用于标示用户,Secret Access Key 是用户用于加密签名字符串和 BOS 服务用来验证签名字符串的密钥。
除系统分配的密钥对外,用户还可自行申请多对AK/SK,总量最多为20对。
BOS提供用户签名验证、访问控制列表ACL和对象限时访问相结合的权限控制方式,为用户提供安全可靠的数据保护。其中用户签名验证采用AK/SK非对称加密的方法对URL进行签名来实现用户身份验证;ACL根据签名识别用户身份后,提出请求Bucket的访问权限信息,并根据相应的权限信息对请求做出响应;对象限时访问让用户可以提供自定义时间内有效的URL用于下载等应用场景。
CDN不仅能为包括地图、图片、文档在内的静态网页加载进行加速,也可为音频、下载、游戏等业务提供加速服务,使网站可被高速访问,有效提升网站的用户体验。
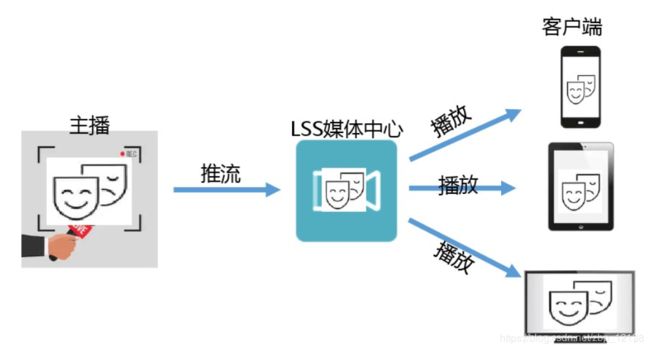
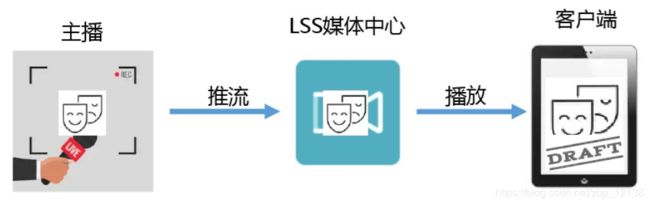
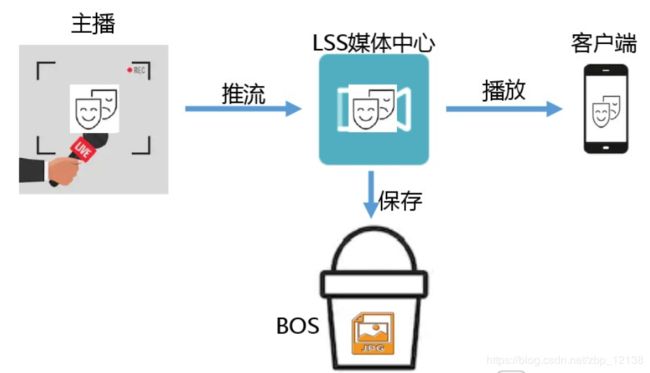
百度智能云LSS基础概念
音视频直播LSS(Live Streaming Service)是一个直播PaaS服务平台,为用户提供快速接入、稳定流畅、低延迟、高并发的音视频直播服务,旨在帮助企业及个人开发者快速搭建自己的直播平台及应用。
LSS提供直播“采集端-服务端-播放端”全套定制开发能力,采集端从直播源获取直播推流送到LSS服务端,LSS服务端完成直播流的处理(包括转码、录制、添加水印、生成缩略图等),播放端进行播放。
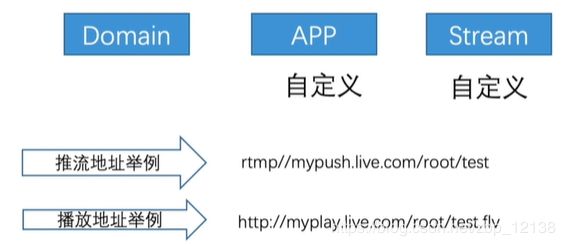
域名:
推流或者播放之前需要创建的域名,域名使用之前请确保已经备案。
流:
流是指音视频数据的载体,例如直播场景中给对方发送通过摄像头采集的音视频数据。
推流:
直播推流,是指将直播场景实况信息实时编码压缩后,推送到 LSS 云端的过程。
播放:
播放是指将推流端推过来的流进行播放的过程。LSS 支持播放推到LSS云端的流,也支持播放第三方源站的流。
模板:
模板是用于配置音视频直播流的具体操作功能参数集合,包含转码、录制、截图等媒体处理操作。
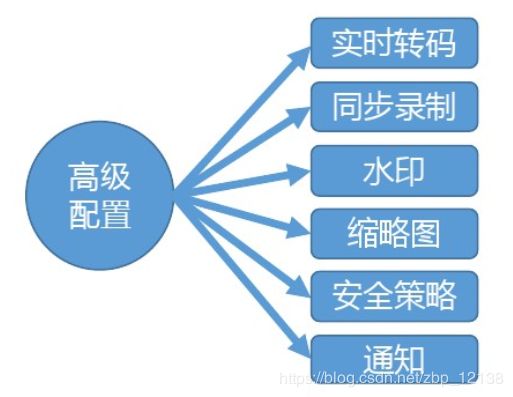
通知:
开启直播通知,LSS在直播状态转换时主动向开发者服务器推送消息。通知通过用户提供的回调地址进行创建。如果用户在创建域名时指定了通知,那么在直播过程中,当直播流状态改变时会向用户指定的回调地址推送通知消息。
域名管理:
-
输入配置
1、推流域名
支持RTMP协议,拼接地址规则如下:
rtmp://{push.your-domain.com}/{app-name}/{stream-name}?{鉴权信息}
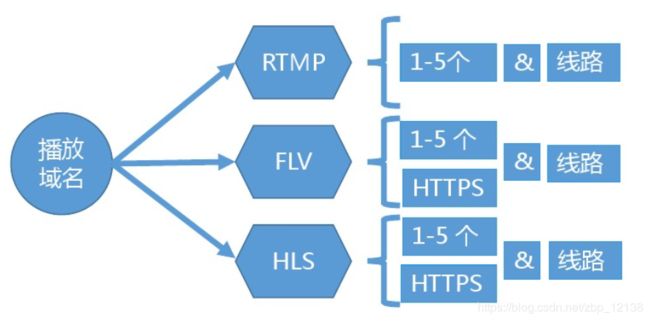
2、拉流域名
支持RTMP、FLV、HLS协议,拼接地址规则如下:
FIv播放地址的拼接规则
http:// {play.your-domain.com}/{app-name} /{stream-name}.flv
RTMP播放地址的拼接规则
rtmp://{play.your- domain.com}/{app-name} /{stream-name}
HLS播放地址的拼接规则
http://{play.your- domain.com} /{app-name} /{stream-name}.m3u8 -
输出配置
-
高级设置
流管理:
流是最基本的直播管理单元
如果流不存在,推流系统会自动创建流
每个应用(App)继承所属域名(Domain)的所有配置,同理,每个
流(Stream)继承所属应用(App)的所有配置。.
流状态:
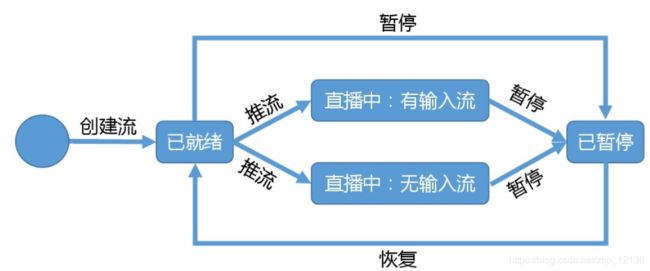
全方位的安全策略:

推流认证:
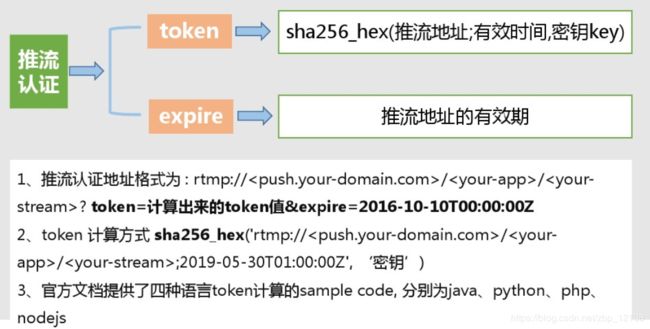
播放认证:

防盗链:

云端实时监控:
转码模板:
转码模板可以配置音视频编码标准、码率、输出流类型等基本参数,包括两
类:
- 样例模板:系统内置,方便您直接使用从而简化域名配置。
- 用户模板:自定义模板,根据需求量身定制从而更好地适配用户业务场景。
录制模板:
LSS提供直播视频录制功能,通过在创建录制模板时指定视频存储路径,并在域名配置中绑定适当的录制模板,即可将直播内容同步录制到对象存储BOS或音视频点播VOD

水印模板:
在直播流中,可以通过水印模板(支持图片水印和时间戳水印)对输出视频添加水印,水印模版中定义水印的详细参数集合用于完成水印添加,包括水印形态(图片、时间戳)、水印大小、位置等。
缩略图模板:
在直播流中,可以通过缩略图模板为输出视频生成缩略图,缩略图模版中定义缩略图的详细参数集合用,包括图片格式、伸缩策略及尺寸大小、BOSBucket及所属区域等。
黄反审核:
黄反审核用于配置黄色、反动相关内容的审核策略,目前提供黄色、性感内
容的审核,支持“默认审核策略”一种审核策略,默认处于"关闭”状态,
需要手动开启。

云原生概念解析及实践应用解析
关于云原生的概念,这里我找了一篇文章:
https://www.jianshu.com/p/a37baa7c3eff
云原生是一种构建和运行应用程序的方法,是一套技术体系和方法论。云原生(CloudNative)是一个组合词,Cloud+Native。
Cloud表示应用程序位于云中,而不是传统的数据中心;Native表示应用程序从设计之初即考虑到云的环境,原生为云而设计,在云上以最佳姿势运行,充分利用和发挥云平台的弹性+分布式优势。
云原生微服务应用平台(Cloud-Native Application Platform,简称CNAP)是一个为企业提供应用托管和微服务管理能力的PaaS平台,帮助企业简化部署、监控、运维等应用生命周期管理,同时支持微服务注册、服务治理、服务监控和调用链的一站式微服务管理和运维能力。
应用:
在CNAP中,应用是由用户定义的一个业务单元,或者一组相互关联的服务合集。如企业的官网可以作为一个应用部署在CNAP中,某物流企业的供应链管理系统,也可以作为一个应用来管理。用户可以在CNAP中创建应用、部署应用、并管理应用的完整生命周期。
工作空间:
CNAP通过工作空间为同一个百度智能云账户下的不同业务/项目组提供逻辑隔离的应用运行环境。如某个金融企业在使用CNAP时,为其信贷部门和财务管理部门创建不同的工作空间,这两个部门的开发人员将分别在各自的工作空间中进行应用部署和运维,从而加强对权限和资源的管理。
环境:
环境在工作空间内,用于管理不同场景中部署应用所需的不同资源和配置。比如在工作空间内划分生产环境、测试环境、开发环境,可以为不同的环境提供不同的底层资源,部署应用的不同版本,以避免在开发和测试环境中频繁修改代码和配置时对生产环境的污染。
集群:
集群是一个云服务器的集合,为CNAP提供资源管理和调度的接口。用户可以通过导入集群的方式,为不同的工作空间、环境提供用于实际部署应用的基础云资源。用户需要在百度智能云上采购服务器以搭建集群,然后通过CNAP的导入功能将集群关联到需要使用资源的工作空间和环境中。
部署组:
部署组是一个应用在CNAP中的实际部署单元,当一个应用被实际部署到某个环境中时,即产生一个部署组。一个应用可以在不同环境中创建出多个部署组,用户可以分别对这些部署组进行更新、管理和运行状态的监控。
CDN
内容分发网络CDN(Content Delivery Network)将源站内容分发至遍布全国的加速节点,缩短用户查看内容的延迟,提高用户访问网站的响应速度与网站的可用性,解决网络带宽小、用户访问量大、网点分布不均等问题。
CDN系统能够实时地根据网络流量和各节点的连接、负载状况以及到用户的距离和响应时间等综合信息将用户的请求重新导向离用户最近的服务节点上。其目的是使用户可就近取得所需内容,解决 Internet网络拥挤的状况,提高用户访问网站的响应速度。
百度智能云CDN加速原理:

如上图所示,CDN加速详细步骤如下:
1.网站用户查询 my.com 的地址
2.请求权威DNS
3.返回配置的CNAME: my.com.a.bdydns.com
4.请求my.com.a.bdydns.com对应的IP
5.根据智能调度返回离用户最近的接入点IP
6.LocalDNS返回my.com的IP地址并缓存
7.向CDN节点发起HTTP/HTTPS请求,访问my.com的内容
8.CDN 通过百度智能云加速链路,将请求转发至多线中心节点
9.中心节点向源站发起回源请求
10.源站向中心节点返回响应
11、12.中心节点、边缘节点将响应返回用户,并缓存响应内容
BCC
云服务器BCC(Baidu Cloud Compute)是处理能力可弹性伸缩的计算服务。管理方式比物理服务器更简单高效,可根据您的业务需要创建、释放任意多台云服务器实例,提升运维效率。为用户快速部署应用构建稳定可靠的基础,降低网络规模计算的难度,使用户更专注于核心业务创新。且无需花费时间和金钱来购买及维护托管虚拟机的硬件,有效降低IT成本。
BCC云服务器提供多种配置选择,其中包括:CPU、内存、公网带宽、镜像类型、操作系统、CDS磁盘、本地磁盘,您可以根据实际需要选择,不同配置项的选择范围如下:
- CPU:1核-96核
- 内存:1GB-256GB
- 公网带宽:1Mbps-200Mbps
- 镜像类型:公共镜像、自定义镜像、服务集成镜像
- 操作系统:支持多种类型的操作系统,具体请以创建实例界面可选择的操作系统类型为准。
- CDS磁盘:5GB-32765GB
- 本地磁盘:5GB-500GB
- 系统盘:免费赠送40GB。
对已创建的BCC可以:
- 灵活升级配置。
- 随时启动、停止、修改和批量修改。
- 按需计费的BCC可以随时释放,包月包年的BCC需要根据付费时间释放。
- 通过客户端或VNC远程登录BCC。
- 通过快照备份和恢复在线数据。
- 通过镜像快速创建BCC实例或更换BCC实例的系统盘。
- 通过安全组对一组BCC实例约定的安全访问规则。
- 通过配置监控报警策略可实时监控资源利用率和异常报警。
BCC提供两种计费方式:
- 包年包月:可选1至12个月的包月服务,或1至3年的包年服务,价格较按需计费更低。采用预付费方式,购买后请留意实例过期时间并及时续费。
- 按需计费:根据您的实际使用量,按分钟实时计费并扣费,您只需在购买前预先向账户充值即可。
- 实例:在百度智能云中作为虚拟服务器运行的系统映像的副本。
- 镜像:即包含了软件及必要配置的云服务器模板。这里提到的镜像分为两种,一种是百度智能云提供的“系统镜像”,包括多种Linux、Windows操作系统。另一种是“自定义镜像”,是用户根据云服务器的快照来自行创建的。
- 快照:是指云服务器或云磁盘在某一特定时间点的完整内容及结构的副本。用户可以随时按快照点进行数据恢复,从而实现包括增量备份等各种形式的备份服务。
- 安全组:是对云服务器实例所应用的通信方向、网络协议、端口、源IP规则的集合。

EIP
EIP的主要用途包括:
- 通过EIP实例,用户可以获取公网带宽服务。
- 用户可灵活配置EIP实例的计费模式,包括按需按带宽付费、按需按流量付费和包年包月按带宽付费三种。
- 用户可将EIP实例与任意BCC或BLB实例绑定或解绑,匹配用户的不同业务场景。
VPC
私有网络 VPC(Virtual private Cloud) 是一个用户能够自定义的虚拟网络,灵活设置网络地址空间,实现私有网络隔离,多个虚拟网络之间(同城、跨城)稳定高速对等互通。您也可以通过专线/ VPN 等连接方式,将百度智能云与您的私有数据中心构建组成一个混合云,将原有的业务轻松迁移云端。
私有网络:
私有网络(Virtual private Cloud,VPC) 是一个用户能够自定义的虚拟网络,能够帮助用户构建属于自己的网络环境。通过指定IP地址范围和子网等配置,即可快速创建一个VPC,不同的 VPC 之间完全隔离,用户可以在VPC内创建和管理BCC实例。
子网:
子网是 VPC 内的用户可定义的IP地址范围,根据业务需求,通过CIDR(无类域间路由)可以指定不同的地址空间和IP段。未来用户可以将子网作为一个单位,用来定义Internet访问权限、路由规则和安全策略。
安全组:
安全组(SecurityGroup)是在VPC 网络内为BCC实例和DCC 专属实例中创建的安全防火墙,定义IP+端口的入站和出站访问策略。
创建 VPC 时同时默认创建一个默认安全组。
用户能够创建自定义VPC,将一个 BCC实例加入该 VPC 时,需要指定关联到所属的哪个安全组,若不指定则仅关联至该 VPC 下的默认安全组。
ACL:
访问控制列表(Access Control List,ACL)作为应用在子网上的防火墙组件帮助用户实现子网级别的安全访问控制。
路由表:
路由表是指路由器上管理路由条目的列表。
弹性网卡:
弹性网卡(Elastic Network Interface Card,ENIC)是挂载云主机的一种弹性网络接口,可在多个云主机间自由迁移。通过在云主机上绑定多个弹性网卡,实现高可用网络方案;也可以在弹性网卡上绑定多个内网 IP,实现单主机多 IP 部署。
服务网卡:
服务网卡(Service Network Interface Card,SNIC)将BOS等VPC外部服务映射到VPC内部,用户可以在VPC内或者混合云对端通过内网便捷、安全地访问这些服务。
NAT网关:
NAT(Network Address Translation)网关为私有网络提供访问Internet服务,支持SNAT和DNAT,可以使多台云服务器共享公网IP资源访问Internet,也可以使云服务器能够提供Internet服务。NAT网关可以绑定EIP实例及共享带宽,为云服务器实现从内网IP到公网IP的多对一或多对多的地址转换服务。
VPN网关:
通过虚拟专用网络(Virtual Private Network,VPN)服务,将百度智能云与客户的多个数据中心快速、灵活搭建VPN隧道,实现混合云。百度智能云VPN网关,基于主备模式的高可靠架构实现,支持VPN健康性自动检测、故障自动恢复等功能。
对等连接:
对等连接(Peer Connection)为用户提供了VPC级别的网络互联服务,使用户实现在不同虚拟网络之间的流量互通,实现同区域/跨区域,同用户/不同用户之间稳定高速的虚拟网络互联。
专线网关:
专线网关是VPC连接物理专线的接口。
-
隔离资源
在百度智能云提供的网络资源上创建一个逻辑隔离区,让您在自定义的私有网络 VPC 内创建云资源。 -
自定义网络
您可以在百度智能云管理控制台自定义设置网络,将VPC 内的 IP 地址空间划分成一个或多个子网,不同类型的云服务资源按需部署在不同的子网内,方便管理和运行服务。 -
访问控制
百度智能云 VPC 提供了安全组功能,安全组是用户在 VPC 内为实例创建的安全防火墙,在实例级别定义IP+端口的入站和出站规则。 -
跨区域和可用区
在同一个 region 内,VPC 可以跨不同可用区(AZ)创建,目前 VPC 不支持跨区域(Region)。 -
高性能
两个VPC之间数据互通,支持高达10G的的带宽,单个NAT网关支持高达5G的吞吐性能。
区块链
一个例子了解区块链:
1、村民把钱存给村长,村长进行记录,村长德高望重,可以从村长这里进行随时支出
2、村长老了,村民开始顾虑,1)村长糊涂了把账本丢了2)村长想谋取私利,开始收手续费3)村长挪用了钱,当村民要取时候没钱给村民4)村长把村民给卖了,信息泄露6)村长找不到了,钱取不到了
区块链:
1、每个村民都有一个小账本
2、每天村里有个大喇叭在播放村民谁存了多少钱都记在本上
3、账本的每-页相当于一页区块,有个人来帮大家校验每页纸上的内容有没有问题,这个人就是矿工

中心化的弊端:
1、账簿消失(不可抗力因素导致账本数据丢失)
2、中心权利过大,掌控所有人的利益,如收取高额手续费
3、掌握所有个人信息,发生信息泄露
4、中心机构失联,交易系统瘫痪
区块链发展现状及应用
三种类型:公有、私有、联盟链。准入条件的限制联盟链是目前企业应用区块链的主流架构。原因:
1、安全第一,需要准入,需要可控。谈到公有链,比特币、ETH、 数字货币。私有链实验平台,测试平台。
2、多点互信,单点谈信任都是伪需求
共识算法:分布式没问题,如何让众多村民的账本是一致的成为了一个难题。( 离喇叭太远听不清,好几个人一起造账本)
如上案例只有记账,ETH出现了,让区块链不仅仅用于记账,可以处理逻辑。( 可以存证、可以处理简单的计算逻辑、可以查找链上的一台服务…) ,于是衍生出了区块链2.0时代,区块链才走进了企业应用世界。
区块链的三层体系:
区块链底层分布式账本、智能合约、业务系统
区块链作为可信任的基础设施,可助力企业业务的创新升级:

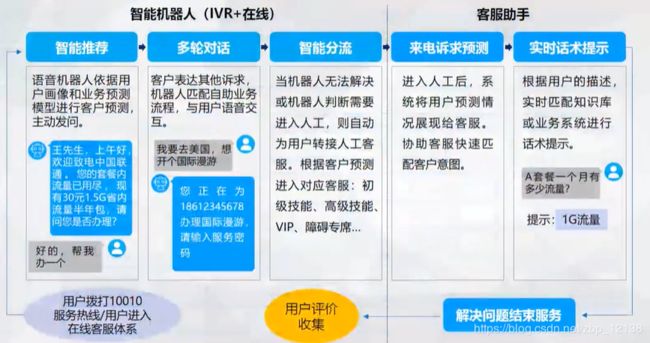
ABC 技术垂直应用之智能客服
智能机器人服务+客服助手 --> 服务用户全流程
动手实验
人工智能实验入门
机器学习,尤其是监督学习则有更加明确的指代。机器学习是专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。这句话有点“云山雾罩”的感觉,让人不知所云。
机器学习的实现步骤可以分成两步,训练和预测。这两个专业名词类似于归纳和演绎的含义。归纳是从具体案例中抽象一般规律,机器学习中的“训练”亦是如此。从一定数量的样本(已知模型输入X和模型输出Y)中,学习出输出Y与输入X的关系(可以想象成是某种表达式)。演绎则是从一般规律推导出具体案例的结果,机器学习中的预测亦是如此。基于训练得到的Y与X之间的关系,遇到新出现的输入X,计算出输出Y。在多数时候,通过模型计算得到的输出,如果和真实场景中的输出一致,说明模型是有效的。
模型假设,评价函数(损失/优化目标)和优化算法是构成一个模型的三个部分。
天文史上,使用大圆和小圆组合的方式计算天体运行在中世纪是可以拟合观测数据的。但随着欧洲机械工业的进步,天文观测设备逐渐强大,越来越多的观测数据无法套用已有的理论。这促进了使用椭圆计算天体运行的理论假说出现。所以,模型有效的基本条件是能够拟合已知的样本,这给我们提供了学习有效模型的实现方案。
以H为模型的假设,它是一个关于参数θ和输入X的函数,用H(θ,X)表示。模型的优化目标是使得H(θ,X)的输出与真实输出Y尽量一致,即两者相差程度即是模型效果的评价函数(相差越小越好)。
那么,学习参数的过程就是在已知的样本上,不断减小该评价函数H(θ,X)和Y相差的过程,直到学习到一个参数θ使得评价函数的取值最小。这个衡量模型预测值和真实值差距的评价函数也被称为损失函数(损失 Loss)。上述优化参数的过程如下图公式所示。
最小化损失是模型的优化目标,实现损失最小化的方法称为优化算法,也称为寻解算法(找到使得损失函数最小的参数解)。
机器学习算法理论在上个世纪90年代发展成熟,在诸多领域也取得了应用效果。但平静的日子过到2010年左右,深度学习模型的异军突起,极大改变了机器学习的应用格局。在今天,多数机器学习任务均可以使用深度学习模型解决。在语音,计算机视觉和自然语言处理等领域,深度学习模型的效果比传统机器学习算法有显著提升。
那么,深度学习又怎样对机器学习的算法结构提出了改进呢?其实两者的理论结构是一致的,也存在模型假设,评价函数和优化算法,最根本的差别在于假设的复杂度上。
对于一张图片,人脑接收到五颜六色的光学信号,计算机则接收到一个数字矩阵。人脑以极快的速度反应出这张图片是一位美女,而且是程序员喜欢的类型。这个结果是一个非常高级的语义概念,从像素到高级语义概念中间要经历怎样复杂的信息变换是难以想象的!这种变换已经复杂到无法用数学公式表达,所以研究者们借鉴了人脑神经元的结构,设计出神经网络的模型。
人工神经网络包括多个神经网络层(卷积层、全连接层、LSTM等),每一层又包括很多神经元,超过三层的非线性神经网络都可以被成为深度神经网络。通俗的讲,深度学习的模型可以视为是输入到输出的映射函数,比如中文到英文的映射,足够深的神经网络理论上可以拟合任何复杂的函数,因此,神经网络非常适合学习样本数据的内在规律和表示层次,对文字\图像和声音任务有很好的适用性,因为这几个领域的任务是人工智能的基础模块,所以深度学习被称为实现人工智能的基础也就不足为奇了。
神经网络思想的提出已经是75年前的事情了,现今的神经网络和深度学习的设计理论是一步步的完善的。在这漫长的发展岁月中,有一些取得关键突破的闪光时刻。
其中有1960年代,基本网络结构设计完善后的黄金时代,也有在1969年异或问题被提出后(人们惊奇的发现神经网络模型连简单的异或问题也无法解决),神经网络模型被束之高阁的黑暗时代。虽然在1986年,新提出的多层的神经网络解决了异或问题,但随着90年代后理论更完备并且实践效果更好的SVM等机器学习模型的兴起,神经网络并未得到重视。
真正的兴起是在2010年左右,基于神经网络模型改进的技术在语音和计算机视觉任务上大放异彩,也逐渐被证明在更多的任务(自然语言处理以及海量数据的任务)上有效。至此,神经网络模型重新焕发生机,并有了一个更加响亮的名字:深度学习。
为何神经网络到2010年后才焕发生机,这与深度学习成功所依赖的先决条件有关。
大数据是它有效的前提。
神经网络和深度学习是非常强大的模型,但也需要足够量级的训练数据。时至今日,很多传统机器学习算法和人工特征依然是足够有效的方案,原因在于很多场景下没有足够的标记数据来支撑深度学习这样强大的模型。深度学习的能力特别像科学家托罗密的豪言壮语:“给我一根足够长的杠杆,我能撬动地球!”,它也可以发出类似的豪言:“给我足够多的数据,我能够学习任何复杂的关系”。但在现实中,足够长的杠杆与足够多的数据一样,往往只能是一种美好的愿景。直到近些年,各行业IT化程度提高,累积的数据量爆发式的增长,才使得应用深度学习模型成为可能。
依靠硬件的发展和算法的优化。
现阶段依靠更强大的计算机,GPU,Autoencoder预训练和并行计算等技术,深度网络在训练上的困难已经被逐渐克服。其中,数据量和硬件是更主要的原因。没有前两者,科学家们想优化算法都无从进行。
早在1998年,一些科学家就已经使用神经网络模型识别手写字母图像了。但深度学习在计算机视觉应用上的兴起,还是在2012年ImageNet比赛上,使用AlexNet做图像分类。如果比较下98年和12年的模型,会发现两者在网络结构上非常类似,仅在一些细节上有所优化。在这十四年间计算性能的大幅提升和数据量的爆发式增长,促使模型完成了从“简单的字母识别”到“复杂的图像分类”的跨越。
虽然历史悠久,但深度学习在今天依然在蓬勃发展,一方面基础研究快速进展,另一方面工业实践层出不穷。
如下图所示,基于深度学习的顶级会议ICLR(international conference on learning representations)统计,深度学习相关的论文数量呈逐年递增的状态。同时,不仅仅是深度学习会议,与数据和模型技术相关的会议ICML和KDD,专注视觉的CVPR和专注自然语言处理的EMNLP等国际会议的大量论文均涉及着深度学习技术。该领域和相关领域的研究方兴未艾,技术仍在不断创新突破中。
另一方面,以深度学习为基础的人工智能技术在升级改造众多的传统行业,存在极其广阔的应用场景。下图选自艾瑞咨询的研究报告,人工智能技术不仅可在众多行业中落地应用(广度),在部分行业(如安防)已经实现了市场化变现和高速增长(深度)。
除了应用广泛的特点外,深度学习还推动人工智能进入工业大生产阶段,算法的通用性导致标准化、自动化和模块化的框架产生。此前,不同流派的机器学习算法理论和实现均不同,导致每个算法均要独立实现,例如随机森林和支撑向量机(SVM)。但在深度学习框架下的诸多算法结构有较大的通用性,例如常用与计算机视觉的卷积神经网络模型(CNN)和常用于自然语言处理的长期短期记忆模型(LSTM),均可以分为组网模块,梯度下降的优化模块,预测模块等。这使得抽象出统一的框架成为了可能,并大大降低了编写建模代码的成本。一些相对通用的模块,如网络基础算子的实现,各种优化算法等均可以由框架实现。建模者只需要关注数据处理,配置组网的方式,以及用少量代码串起训练和预测的流程即可。
在深度学习框架出现之前,机器学习工程师处于手工业作坊生产的时代。为了完成建模,工程师需要储备大量数学知识,并为特征工程工作积累大量行业知识。每个模型是极其个性化的,建模者如同手工业者一样,将自己的积累形成模型的“个性化签名”。
深度学习在很多机器学习领域均有非常出色的表现,在图像识别、语音识别、自然语言处理、机器人、网络广告投放、医学自动诊断和金融等各大领域有着广泛的应用。面对繁多的应用场景,深度学习框架可以节省大量而繁琐的外围工作,使建模者关注业务场景和模型设计本身。
使用深度学习框架完成建模任务有两个显著优势。
1、节省大量编写底层代码的精力:屏蔽底层实现,用户只需关注模型的逻辑结构,降低了深度学习入门门槛。
2、省去了部署和适配环境的烦恼:飞桨框架具备灵活的移植性,可将代码部署到CPU/GPU/移动端上,选择具有分布式性能的深度学习工具会使模型训练更高效,预测端也针对大量的硬件进行了适配和优化工作。
百度出品的深度学习框架飞桨(PaddlePaddle)是与国外TensorFlow、Pytorch等框架并列,在主流深度学习框架中唯一完全国产化的产品。国内大量企业的研发人员基于飞桨研发出丰富的行业应用,部分典型案例如下图所示。
框架的本质是由框架实现建模过程中相对通用的模块,将不同模型个性化的部分交予用户实现,在“投入节省精力”和“产出灵活强大”之间达到一个平衡。假设你是深度框架的创造者,你会让框架实现哪些功能呢?
相信已经对神经网络模型有所了解的读者,都会得出下表所示的设计思路。在实现建模的过程中,每一步所需要完成的任务均可以拆分成个性化的部分和通用化的部分。
个性的往往是指定模型由哪些逻辑元素组合,而通用的部分则是这些元素的算法实现。无论是计算机视觉任务还是自然语言处理任务,使用的深度学习模型结构均是类似的,只是在每个环节指定的实现算法不同。多数情况下,这些实现只是相对有限的一些选择,比如常见的Loss函数不超过十种,常用的网络配置也就十几种,常用优化算法不超过五种等等。这些特性使得基于框架建模更像一个编写“模型配置”的过程。
飞桨(PaddlePaddle)不仅包含深度学习框架,还提供了一整套紧密关联、灵活组合的工具组件和服务平台,助力深度学习技术的应用落地。
以模型库为例,大量工业实践任务并不是从头编写,而是在相对标准化的模型上进行微调和优化。飞桨框架已经提供了主流深度学习任务的模型实现,并且在多数模型的效果上达到业界领先。既然飞桨如此强大,我们没必要从头到尾编写深度学习模型的完整实现,基于飞桨可以更高效的完成建模。
智慧卫生-智能垃圾分类实验
智慧卫生智能垃圾分类系统实训实施思路
- 导入相关库和模块
- 定义参数初始化函数
- 卷积神经网络卷积与池化定义
- 智能垃圾分类模型构建
- 损失函数、训练节点及准确率定义
- 数据集读取与模型训练
- 智能垃圾分类模型评估
实施步骤
步骤1:导入相关库和模块
导入时运行报错,则应该按照报错的提示去安装未安装的模块,
# -*- coding:utf-8 -*-
import os
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
from numpy import *
from prework import *
步骤2:定义参数初始化函数
将参数的初始化封装成函数,提高代码的复用率,使代码更加简洁明了。
- tf.truncated_normal(shape, mean, stddev, dtype)这个函数产生符合正态分布的随机数,均值和标准差自己设定。
- shape表示生成张量的维度
- mean是均值,默认为0
- stddev是标准差,默认为1
- dtype为数据类型
- tf.constant(value, shape, dtype)生成常量
- value表示数值
#权值初始化
def weight_variable(shape, n):
# 请在此处创建一个结构为shape的矩阵,初始化值符合标准差为n的正态分布的随机数
initial = tf.truncated_normal(shape, stddev = n, dtype = tf.float32)
return initial
#偏置初始化
def bias_variable(shape):
# 请在此处创建一个结构为shape的矩阵,初始化所有值为0.1
initial = tf.constant(0.1, shape = shape, dtype = tf.float32)
return initial
步骤3:卷积神经网络卷积与池化定义
TensorFlow已提供了卷积函数 tf.nn.conv2d()
函数原型:
tf.nn.conv2d(input, filter, strides, padding, name)
例:
tf.nn.conv2d(x_input, W_1, strides = [1,1,1,1],padding = ‘SAME’)
参数:
-
input : 输入的要做卷积的图片,要求为一个张量,shape为 [ batch, in_height, in_weight, in_channel ],其中batch为图片的数量,in_height 为图片高度,in_weight 为图片宽度,in_channel 为图片的通道数,灰度图该值为1,彩色图为3。
-
filter: 卷积核,要求也是一个张量,shape为 [ filter_height, filter_weight, in_channel, out_channels ],其中 filter_height 为卷积核高度,filter_weight 为卷积核宽度,in_channel 是图像通道数 ,和 input 的 in_channel 要保持一致,out_channel 是卷积核数量。
-
strides: 卷积时在图像每一维的步长,这是一个一维的向量,[ 1, strides, strides, 1],第一位和最后一位固定必须是1,第二位和第三位分别为横向步长和纵向步长。
-
padding: string类型,值为“SAME” 和 “VALID”,表示的是卷积的形式,是否考虑边界。"SAME"是考虑边界,不足的时候用0去填充周围,使输出的特征矩阵与输入矩阵维度相同,"VALID"则不考虑。
-
tf.nn.conv2d将返回一个张量Tensor,shape是[batch, height, width, channels]这种形式。
# 请在此处定义卷积运算函数
def conv2d(x, W):
initial = tf.nn.conv2d(x, W, strides = [1,1,1,1], padding = 'SAME')
return initial
TensorFlow也提高了各种池化的操作,这里以 MaxPooling为例。
函数原型:
tf.nn.max_pool(input, ksize, strides, padding, name)
例:
tf.nn.max_pool(x, ksize = [1,3,3,1], strides = [1,2,2,1], padding=‘SAME’)
- input:需要池化的输入,一般池化层接在卷积层后面,所以输入通常是feature map,依然是[batch, height, width, channels]这样的shape;
- ksize:池化窗口的大小,取一个四维向量,一般是[1, height, width, 1],因为我们不想在batch和channels上做池化,所以这两个维度设为了1;
- strides:和卷积类似,窗口在每一个维度上滑动的步长,一般也是[1, stride,stride, 1]
- padding:string类型,值为“SAME” 和 “VALID”,表示的是卷积的形式,是否考虑边界。"SAME"是考虑边界,不足的时候用0去填充周围,使输出的特征矩阵与输入矩阵维度相同,"VALID"则不考虑。
返回一个Tensor,类型不变,shape仍然是[batch, height, width, channels]这种形式。
# 请在此处定义池化函数
def max_pool_3x3(x, name):
initial = tf.nn.max_pool(x, ksize = [1,3,3,1], strides = [1,2,2,1], padding = 'SAME', name = name)
return initial
步骤4:智能垃圾分类模型构建

def inference(images, batch_size, n_classes, keep_prob):
# 搭建网络
# 第一层卷积
# with tf.variable_scope('conv1') as scope: 作用是指定一个变量域,变量域内创建的变量作用范围仅在域内,
#且能够被所有输入共享,从而达到记忆特征的目的,每个域各自独立。通常每一层设置一个变量域。
with tf.variable_scope('conv1') as scope:
# 创建权值w,尺寸为3*3的3通道卷积核,数量为64个
# 图变量用法:tf.Variable(initializer, name, dtype)
# 权值初始化:weight_variable(shape, n)
w_conv1 = tf.Variable(weight_variable([3,3,3,64], 1.0), name = 'weights', dtype = tf.float32)
# 创建偏置值b,数量为64个
# 图变量用法:tf.Variable(x, name, dtype)
# 偏置值初始化:bias_variable(shape)
b_conv1 = tf.Variable(bias_variable([64]), name = 'biases', dtype = tf.float32)
# 选用relu激活函数激活卷积后的结果,得到128*128*64
# relu激活函数用法:tf.nn.crelu(x, name)
# 卷积运算函数用法:conv2d(x, W)
h_conv1 = tf.nn.relu(conv2d(images, w_conv1)+b_conv1, name = 'conv1')
# 第一层池化
# 3x3最大池化,步长strides为2,池化后执行lrn()操作,局部响应归一化,增强了模型的泛化能力。
# LRN对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元
with tf.variable_scope('pooling1_lrn') as scope:
# 池化上层结果
# 池化函数用法:max_pool_3x3(x, name)
pool1 = max_pool_3x3(h_conv1, name = 'pooling1')
# 进行局部响应归一化
norm1 = tf.nn.lrn(pool1, depth_radius=4, bias=1.0, alpha=0.001 / 9.0, beta=0.75, name='norm1')
# 得到64*64*64
# 第二层卷积
# 32个3x3的卷积核(32通道)
with tf.variable_scope('conv2') as scope:
# 创建权值w,尺寸为3*3的64通道卷积核,数量为32个
w_conv2 = tf.Variable(weight_variable([3,3,64,32], 0.1), name = 'weights', dtype = tf.float32)
# 创建偏置值b,数量为32个
b_conv2 = tf.Variable(bias_variable([32]), name = 'biases', dtype = tf.float32)
# 选用relu激活函数激活卷积后的结果,得到64*64*32
h_conv2 = tf.nn.relu(conv2d(norm1, w_conv2)+b_conv2, name='conv2')
# 第二层池化
# 3x3最大池化,步长strides为2,池化后执行lrn()操作
with tf.variable_scope('pooling2_lrn') as scope:
# 池化上层结果
pool2 = max_pool_3x3(h_conv2, name = 'pooling2')
# 进行局部响应归一化
norm2 = tf.nn.lrn(pool2, depth_radius=4, bias=1.0, alpha=0.001 / 9.0, beta=0.75, name='norm2')
# 得到32*32*32
# 第三层卷积
# 16个3x3的卷积核(16通道)
with tf.variable_scope('conv3') as scope:
# 创建权值w,尺寸为3*3的32通道卷积核,数量为16个
w_conv3 = w_conv2 = tf.Variable(weight_variable([3,3,32,16], 0.1), name = 'weights', dtype = tf.float32)
# 创建偏置值b,数量为16个
b_conv3 = tf.Variable(bias_variable([16]), name = 'biases', dtype = tf.float32)
# 选用relu激活函数激活卷积后的结果,得到32*32*16
h_conv3 = tf.nn.relu(conv2d(norm2, w_conv3)+b_conv3, name='conv3')
# 第三层池化
# 3x3最大池化,步长strides为2,池化后执行lrn()操作
with tf.variable_scope('pooling3_lrn') as scope:
# 池化上层结果
pool3 = max_pool_3x3(h_conv3, name = 'pooling3')
# 进行局部响应归一化
norm3 = tf.nn.lrn(pool3, depth_radius=4, bias=1.0, alpha=0.001 / 9.0, beta=0.75, name='norm3')
# 得到16*16*16
# 第四层全连接层
with tf.variable_scope('local3') as scope:
# 将之前pool层的输出reshape成二维矩阵[批次,神经元数量],-1为自动判断数量
reshape = tf.reshape(norm3, shape=[batch_size, -1])
# 取得第二维度的数量
dim = reshape.get_shape()[1].value
# 再将所有神经元全连接至128个神经元
w_fc1 = tf.Variable(weight_variable([dim, 128], 0.005), name='weights', dtype=tf.float32)
b_fc1 = tf.Variable(bias_variable([128]), name='biases', dtype=tf.float32)
h_fc1 = tf.nn.relu(tf.matmul(reshape, w_fc1) + b_fc1, name=scope.name)
# 第五层全连接层
# 128个神经元
with tf.variable_scope('local4') as scope:
w_fc2 = tf.Variable(weight_variable([128 ,128], 0.005),name='weights', dtype=tf.float32)
b_fc2 = tf.Variable(bias_variable([128]), name='biases', dtype=tf.float32)
h_fc2 = tf.nn.relu(tf.matmul(h_fc1, w_fc2) + b_fc1, name=scope.name)
# 对卷积结果执行dropout操作
# Dropout可以比较有效的缓解过拟合的发生,在一定程度上达到正则化的效果
# tf.nn.dropout(x, keep_prob, noise_shape=None, seed=None, name=None)
# 第二个参数keep_prob: 设置神经元被选中的概率,在初始化时keep_prob是一个占位符
h_fc2_dropout = tf.nn.dropout(h_fc2, keep_prob)
# Softmax回归层
# 将前面的FC层输出至n_classes个类,做一个线性回归,计算出每一类的得分。
# 这里只需要预测结果,没必要计算得分,有兴趣的同学可以加上softmax激活函数计算每一类的得分
with tf.variable_scope('softmax_linear') as scope:
weights = tf.Variable(weight_variable([128, n_classes], 0.005), name='softmax_linear', dtype=tf.float32)
biases = tf.Variable(bias_variable([n_classes]), name='biases', dtype=tf.float32)
softmax_linear = tf.add(tf.matmul(h_fc2_dropout, weights), biases, name='softmax_linear')
# softmax_linear = tf.nn.softmax(tf.add(tf.matmul(h_fc2_dropout, weights), biases, name='softmax_linear'))
return softmax_linear
# 最后返回softmax层的输出
步骤5: 损失函数、训练节点及准确率定义
使用交叉熵损失函数计算损失
# loss计算
# 传入参数:logits,网络计算输出值。labels,真实值
# 返回参数:loss,损失值
def losses(logits, labels):
with tf.variable_scope('loss') as scope:
# 交叉熵损失函数可以衡量p与q的相似性。
# 交叉熵作为损失函数还有一个好处是使用sigmoid函数在梯度下降时
# 能避免均方误差损失函数学习速率降低的问题,因为学习速率可以被输出的误差所控制。
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits, labels=labels, name='xentropy_per_example')
# 计算张量tensor沿着tensor的某一维度上的平均值
loss = tf.reduce_mean(cross_entropy, name='loss')
return loss
使用动量梯度下降法优化参数
# loss损失值优化
# 输入参数:loss。learning_rate,学习率。
# 返回参数:train_op,训练op,这个参数要输入sess.run中让模型去训练。
def trainning(loss, learning_rate):
with tf.name_scope('optimizer'):
# 定义动量梯度下降法
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
# 设置一个用于记录全局训练步骤的单值global_step
global_step = tf.Variable(0, name='global_step', trainable=False)
# 使用minimize()操作优化更新训练的模型参数,同时为全局步骤(global step)计数
train_op = optimizer.minimize(loss, global_step=global_step)
return train_op
计算评价/准确率
# 评价/准确率计算
# 输入参数:logits,网络计算值。labels,标签.
# 返回参数:accuracy,当前step的平均准确率,也就是在这些batch中多少张图片被正确分类了。
def evaluation(logits, labels):
with tf.variable_scope('accuracy') as scope:
# tf.nn.in_top_k用于计算预测的结果和实际结果的是否相等,返回一个bool类型的张量
# tf.nn.in_top_k(predictions, targets, k, name=None)
correct = tf.nn.in_top_k(logits, labels, 1)
# 计算correct的平均值
# tf.cast用于改变某个张量的数据类型
accuracy = tf.reduce_mean(tf.cast(correct, tf.float16))
return accuracy
步骤6:数据集读取与模型训练
# --------------------------训练过程-----------------------------
# 训练步数,可修改
MAX_STEP = 600
# 读取数据集,batch的大小设置为32
train_batch, train_label_batch = get_batch_record('train.tfrecords',32)
# 使用占位符,训练时把keep_prob设置为0.5,需要在sess.run(feed_dict={keep_prob:0.5})赋值
# tf.placeholder用于定义数据类型
keep_prob = tf.placeholder(tf.float32)
# 输入网络得到预测结果
logits = inference(train_batch, 32, 3, keep_prob)
# 训练损失值
train_loss = losses(logits, train_label_batch)
# 训练节点,学习率设置为0.001
train_op = trainning(train_loss, 0.001)
acc = evaluation(logits, train_label_batch)
# 产生一个会话
sess = tf.Session()
# 产生一个saver来存储训练好的模型
saver = tf.train.Saver()
# 所有节点初始化
sess.run(tf.global_variables_initializer())
# 队列监控
coord = tf.train.Coordinator() # 设置多线程协调器
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
try:
for step in np.arange(MAX_STEP):
if coord.should_stop():
break
# 将各个节点送进会话中运行,并为keep_prob赋值
_, tra_loss, tra_acc = sess.run([train_op, train_loss, acc], feed_dict = {keep_prob : 0.5})
# 每隔50步打印一次当前的loss以及acc,
if step % 50 == 0:
print('Step %d, train loss = %.3f, train accuracy = %.2f%%' % (step, tra_loss, tra_acc * 100.0))
# 保存模型
saver.save(sess, './trash_classify_conv_net.ckpt')
print('successfully saving the .ckpt \n training done!')
# 如果遍历完之后还调用sess.run()的话,会报tf.errors.OutOfRangeError错误
except tf.errors.OutOfRangeError:
print('Done training -- epoch limit reached')
finally:
coord.request_stop()
coord.join(threads)
sess.close()
步骤7:智能垃圾分类模型评估
#----------------------------评估过程--------------------------------
# 使用占位符,目的是评估时把keep_prob设置为1,需要在sess.run(feed_dict={keep_prob:1.0})赋值
keep_prob = tf.placeholder(tf.float32)
# 读取数据集,并组装成每个批次32个样本
test_batch, test_label_batch = get_batch_record('test.tfrecords',32)
# 输入网络得到预测结果
test_logits = inference(test_batch, 32, 3, keep_prob)
# 准确值
test_acc = evaluation(test_logits, test_label_batch)
# 取得推断的索引值
logits = tf.argmax(test_logits, 1)
# 三个类的列表
lists = ('glass','paper','plastic')
#saver用以后面加载模型
saver = tf.train.Saver()
sess = tf.Session()
coord = tf.train.Coordinator() # 设置多线程协调器
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
# 读取训练好的模型
ckpt = tf.train.get_checkpoint_state('./')
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess, ckpt.model_checkpoint_path)
print('Loading successfully')
MAX_STEP = 60
test_sum = 0
# 计算准确率
for step in range(MAX_STEP):
tes_acc = sess.run(test_acc, feed_dict = {keep_prob : 1.0})
test_sum = test_sum + tes_acc
if step % 20 == 0:
print('Step %d, test accuracy = %.2f%%' % (step, tes_acc * 100.0))
print('The avarage of test accuracy is %.2f%%' % ((test_sum / MAX_STEP) * 100))
# 从会话中取出结果
img, label, logits = sess.run([test_batch, test_label_batch, logits], feed_dict={keep_prob : 1.0})
# 将取出的样本转回0-255px的格式,用以展示
img = tf.cast((img + 0.5) * 255. , tf.uint8)
img = sess.run(img)
# 显示预测结果
for i in np.arange(32):
plt.imshow(img[i, :, :, :])
title = ('label: {} , prediction: {}').format(lists[int(label[i])], lists[int(logits[i])])
plt.title(title)
plt.show()
coord.request_stop()
coord.join(threads)
