ElasticSearch常用指令
- 对于不需要聚合的字段,建议关闭fielddata,因为fielddata比较耗内存
- 索引排序会加速查询的效率
- 查看索引列表
GET /_cat/indices?v
- 创建索引
索引命名有如下限制:
a. 仅限小写字母
b. 不能包含\、/、 *、?、"、<、>、|、#以及空格符等特殊符号
c. 从7.0版本开始不再包含冒号
d. 不能以-、_或+开头
e. 不能超过255个字节(注意它是字节,因此多字节字符将计入255个限制)
put /test
- 查看索引配置信息
get /test
- 修改现有索引的配置
a. ElasticSearch中对shard的分布是有要求的, 有其内置的特殊算法。
b. ElasticSearch尽可能保证primary shard平均分布在多个节点上。Replica shard会保证不和对应的primary shard分配在同一个节点上。
c. 索引一旦创建,primary shard数量不可变化,但是可以改变replica shard数量
PUT /test/_settings
{
"number_of_replicas": 1
}
- 创建索引指定相关配置
PUT /test
{
"settings" : {
"number_of_shards" : 1,
"number_of_replicas" : 1
}
}
- 删除索引
DELETE /test [, other_index]
- 插入/全量更新文档
在index中增加document时, ElasticSearch有自动识别机制。如果增加的document对应的index不存在, 则自动创建;如果index存在,type不存在自动创建;如果index和type都存在,则使用现有的。
#不带主键, elasticsearch自动生成一个主键
post /test/_doc
{
"name":"redis",
"age":29,
"sex": "男"
}
#带主键, 如果主键不存在,则插入;反之,则更新
post /test/_doc/1
{
"name":"redis",
"age":29,
"sex": "男"
}
#强制新增。如果Document的id在ES中已存在,则会报错
post /test/_doc/1/_create
{
"name":"redis",
"age":29,
"sex": "男"
}
#非全量更新(部分更新)
post /test/_doc/1/_update
{
"doc":{
"sex":"男"
}
}
或(版本7及以上)
post /test/_update/1/
{
"doc":{
"sex":"男"
}
}
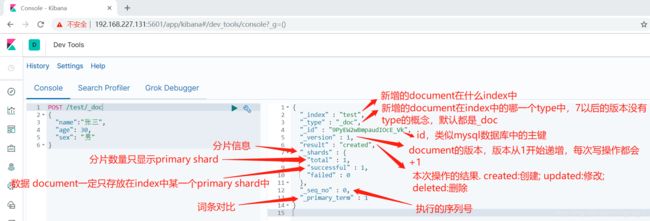
- 删除文档
a. 执行删除操作时,ElasticSearch先标记document为deleted状态,而不是直接物理删除。
b. 当ElasticSearch存储空间不足或工作空闲时,才会执行物理删除操作。
c. 标记为deleted状态的数据不会被查询搜索到。
d. 所有的标记动作都是为了NRT实现(近实时)
delete /test/_doc/1
- 查询
#根据主键查询
get /test/_doc/1
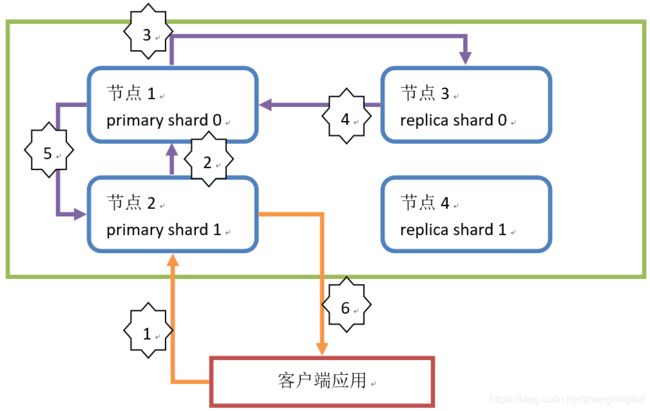
- ElasticSearch增删改原理
a. 客户端发起请求,执行增删改操作。所有的增删改操作都由primary shard直接处理,replica shard只被动的备份数据。此操作请求到节点2(请求发送到的节点随机),这个节点称为协调节点(coordinate node)。
b. 协调节点通过路由算法,计算出本次操作的Document所在的shard。假设本次操作的Document所在shard为 primary shard 0。协调节点计算后,会将操作请求转发到节点1。
c. 节点1中的primary shard 0在处理请求后,会将数据的变化同步到对应的replica shard 0中,也就是发送一个同步数据的请求到节点3中。
d. replica shard 0在同步数据后,会响应通知请求这同步成功,也就是响应给primary shard 0(节点1)。
e. primary shard 0(节点1)接收到replica shard 0的同步成功响应后,会响应请求者,本次操作完成。也就是响应给协调节点(节点2)。
f. 协调节点返回响应给客户端,通知操作结果。
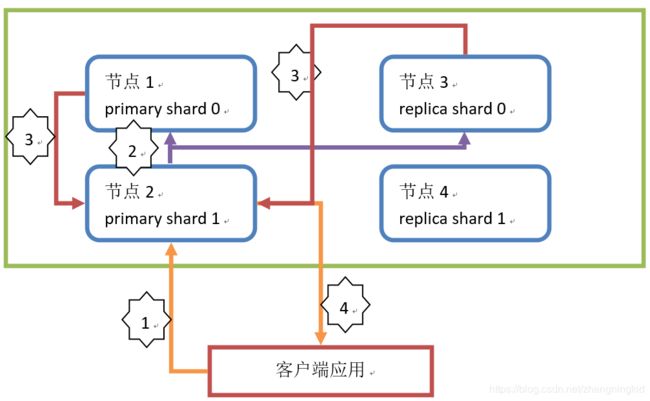
- ElasticSearch查询原理
a. 客户端发起请求,执行查询操作。查询操作都由primary shard和replica shard共同处理。此操作请求到节点2(请求发送到的节点随机),这个节点称为协调节点(coordinate node)。
b. 协调节点通过路由算法,计算出本次查询的Document所在的shard。假设本次查询的Document所在shard为 shard 0。协调节点计算后,会将操作请求转发到节点1或节点3。分配请求到节点1还是节点3通过随机算法计算,ES会保证当请求量足够大的时候,primary shard和replica shard处理的查询请求数是均等的(是不绝对一致)。
c. 节点1或节点3中的primary shard 0或replica shard 0在处理请求后,会将查询结果返回给协调节点(节点2)。
d. 协调节点得到查询结果后,再将查询结果返回给客户端。
- 查询
#查询所有
get /test/_search
#全文检索
get /test/_search?q=xxx
#DSL(Domain Specified Language)语句
#查询所有
get /test/_search
{
"query":{
"match_all": {}
}
}
#按条件查询,并排序
get /test/_search
{
"query":{
"match": {
"sex":"女"
}
},
"sort":[
{"age":"desc"}
]
}
#分页查询
get test/_search
{
"query":{
"match_all": {}
},
"from":1, #从第几条数据开始查询,从0开始计数
"size":2, #查询多少数据
"sort":[
{"age":"desc"}
]
}
#查询部分字段 - 此搜索操作适合构建复杂查询条件,生产环境常用。
get /test/_search
{
"query":{
"match_all": {
}
},
"_source":["name"]
}
# 多条件查询
GET /test/_search
{
"query": {
"bool": { # 多条件搜索,内部的若干条件,只要有正确结果,即可
"must": [ # 必须,内部若干条件,必须都匹配才有结果(类似mysql中的and关键字, 与之对应的是should, 类似mysql中的or关键字)
{
"match": {
"name": "张三"
}
},
{
"match": {
"sex": "女"
}
}
]
}
}
}
#全文检索 - full-text search
#要求查询条件拆分后的任意词条与具体数据匹配就算搜索结果。查询结果顺序默认与匹配度分数相关
GET /test/_search
{
"query": {
"match": {
"name": "张三"
}
}
}
#phrase search(短语搜索)。
#要求查询条件必须和具体数据完全匹配才算搜索结果
GET /test/_search
{
"query": {
"match_phrase": {
"name": "张三"
}
}
}
#高亮搜索结果
#高亮显示。高亮不是搜索条件,是显示逻辑。在搜索的时候,经常需要对条件实现高亮显示
get /test/_search
{
"query":{
"match":{
"name":"张三"
}
},
"highlight":{
"pre_tags": [""],
"post_tags": [""],
"fields":{
"name":{}
}
}
}
#聚合搜索
#准备工作
PUT /products_index/_doc/1
{
"name":"IPHONE 8",
"remark":"64G",
"price":548800,
"producer":"APPLE",
"tags" : [ "64G", "red color", "Nano SIM" ]
}
PUT /products_index/_doc/2
{
"name":"IPHONE 8",
"remark":"64G",
"price":548800,
"producer":"APPLE",
"tags" : [ "64G", "golden color", "Nano SIM" ]
}
PUT /products_index/_doc/3
{
"name":"IPHONE 8 PLUS",
"remark":"128G",
"price":748800,
"producer":"APPLE",
"tags" : [ "128G", "red color", "Nano SIM" ]
}
PUT /products_index/_doc/4
{
"name":"IPHONE 8 PLUS",
"remark":"256G",
"price":888800,
"producer":"APPLE",
"tags" : [ "256G", "golden color", "Nano SIM" ]
}
#开启fielddata
PUT /products_index/_mapping/
{
"properties" : {
"tags" : {
"type":"text",
"fielddata":true #开启正排索引,类似mysql中的普通索引,用以下面的聚合查询
}
}
}
#查询每个词条出现的个数统计。
#类似mysql中的select count(*) .. from .. group by ...
get /products_index/_search
{
"aggs":{ # 开始聚合,类似query,是一个命令。或api
"group_by_tags":{ # 给聚合数据,加一个命名。自定义
"terms": { # 是一个聚合api,类似数据库中的聚合函数。解析某字段中的词条。类似的聚合函数还有avg等
"field": "tags"
}
}
}
}
#结合查询条件的聚合统计。
#类似类似mysql中的select count(*) .. from ...where.... group by ...
GET /products_index/_search
{
"query" : {
"match" : { "name" : "PLUS" }
},
"aggs" : {
"group_by_tags":{
"terms" : { "field" : "tags" }
}
}
}
#计算name中包含plus的document数据中的price字段平均值
#类似mysql的select avg(...) from ... group by...
GET /products_index/_search
{
"query" : {
"match" : { "name" : "PLUS" }
},
"aggs" : {
"avg_by_price":{
"avg" : { "field" : "price" }
}
}
}
#聚合是可以嵌套的,内层聚合是依托于外层聚合的结果之上,实现聚合计算的。
#搜索包含plus的document,根据tags做词条统计,在统计结果中,计算price平均值。
#类似mysql中的select avg(..) from ... group by ...
GET /products_index/_search
{
"query": {
"match": {
"name": "plus"
}
},
"aggs": {
"group_by_tags": {
"terms": {
"field": "tags"
},
"aggs": {
"avg_by_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
#聚合aggs中如果使用order排序的话,要求排序字段必须是一个aggs聚合相关的字段。
#计算每个tag中的Document数据的price平均值,并根据price字段数据排序.类似mysql中的select .. from ...where.... group by ...order by...
get /products_index/_search
{
"aggs":{
"group_by_tags":{
"terms": {
"field": "tags",
"order": {
"avg_price": "desc"
}
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
#使用price取值范围分组,再计算分组document中price的平均值
get /products_index/_search
{
"query":{
"match_all": {}
},
"_source":"price",
"aggs":{
"range_by_price":{
"range": {
"field": "price",
"ranges": [
{
"from": 500000,
"to": 600000
},
{
"from": 600001,
"to": 800000
},
{
"from": 800001,
"to": 1000000
}
]
},
"aggs": {
"avg_by_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
- 创建索引的mapping
PUT /test
{
"settings" : {
"number_of_shards" : 1,
"number_of_replicas" : 1
},
"settings" : {
"index" : {
"sort.field" : ["name", "age"],
"sort.order" : ["asc", "desc"]
}
},
"mappings": {
"properties": {
"name":{
"type": "keyword"
},
"age":{
"type":"integer"
},
"description":{
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}