1. 背景:
最早是由 Vladimir N. Vapnik 和 Alexey Ya. Chervonenkis 在1963年提出
目前的版本(soft margin)是由Corinna Cortes 和 Vapnik在1993年提出,并在1995年发表
深度学习(2012)出现之前,SVM被认为机器学习中近十几年来最成功,表现最好的算法
2 . 机器学习的一般框架:
训练集 => 提取特征向量 => 结合一定的算法(分类器:比如决策树,KNN)=>得到结果
3 . 介绍:
3.1 例子:

两类?哪条线最好?
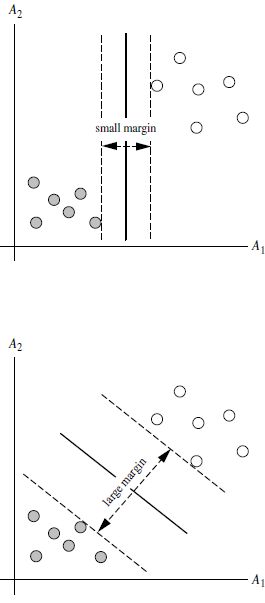
3.2 SVM寻找区分两类的超平面(hyper plane), 使边际(margin)最大

总共可以有多少个可能的超平面?无数条
如何选取使边际(margin)最大的超平面 (Max Margin Hyperplane)?
超平面到一侧最近点的距离等于到另一侧最近点的距离,两侧的两个超平面平行
3. 线性可区分(linear separable) 和 线性不可区分 (linear inseparable)
3.1 线性可分情况
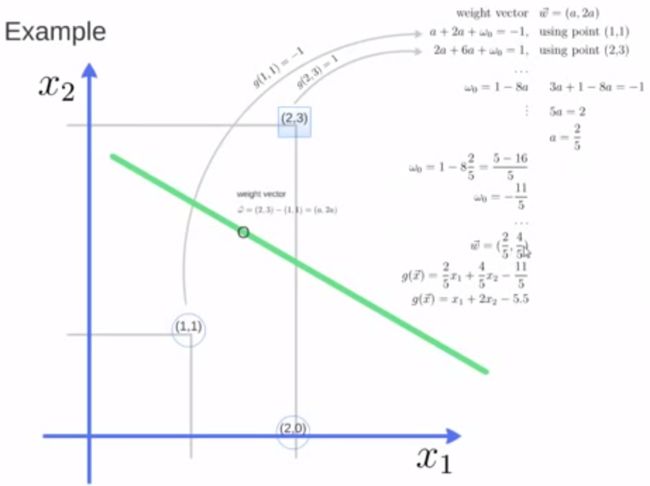
3.1.1 定义与公式建立
超平面可以定义为:其中:
W: weight vectot
X: 训练实例
b: bias
所有坐落在边际的两边的的超平面上的被称作”支持向量(support vectors)"
3.1.2 SVM如何找出最大边际的超平面呢(MMH)?
利用一些数学推倒,可变为有限制的凸优化问题(convex quadratic optimization)
利用 Karush-Kuhn-Tucker (KKT)条件和拉格朗日公式,可以推出MMH可以被表示为以下“决定边界 (decision boundary)”
3.1.3 对于任何测试(要归类的)实例,带入以上公式,得出的符号是正还是负决定
3.1.4 特点
训练好的模型的算法复杂度是由支持向量的个数决定的,而不是由数据的维度决定的。所以SVM不太容易产生overfitting
SVM训练出来的模型完全依赖于支持向量(Support Vectors), 即使训练集里面所有非支持向量的点都被去除,重复训练过程,结果仍然会得到完全一样的模型。
一个SVM如果训练得出的支持向量个数比较小,SVM训练出的模型比较容易被泛化。
3.2 线性不可分的情况



数据集在空间中对应的向量不可被一个超平面区分开
3.2.1 两个步骤来解决:
利用一个非线性的映射把原数据集中的向量点转化到一个更高维度的空间中
在这个高维度的空间中找一个线性的超平面来根据线性可分的情况处理

3.2.2 核方法
3.2.2.1 动机
在线性SVM中转化为最优化问题时求解的公式计算都是以内积(dot product)的形式出现的,就是把训练集中的向量点转化到高维的非线性映射函数,因为内积的算法复杂度非常大,所以我们利用核函数来取代计算非线性映射函数的内积。
3.2.2.2常用的核函数(kernel functions)
- h度多项式核函数(polynomial kernel of degree h)
- 高斯径向基核函数(Gaussian radial basis function kernel)
- S型核函数(Sigmoid function kernel):
如何选择使用哪个kernel?
根据先验知识,比如图像分类,通常使用RBF,文字不使用RBF
尝试不同的kernel,根据结果准确度而定
4. SVM扩展可解决多个类别分类问题
对于每个类,有一个当前类和其他类的二类分类器(one-vs-rest)
5 SVM运用
5.1 sklearn简单例子
from sklearn import svm
x = [[2, 0], [1, 1], [2, 3]]
y = [0, 0, 1]
clf = svm.SVC(kernel = 'linear')
clf.fit(x, y)
print(clf)
# get support vectors
print(clf.support_vectors_)
# get indices of support vectors
print(clf.support_)
# get number of support vectors for each class
print(clf.n_support_)
# 预测点(2,0)
print(clf.predict([[2,0]]))
运行结果:
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='auto', kernel='linear',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
[[ 1. 1.]
[ 2. 3.]]
[1 2]
[1 1]
[0]
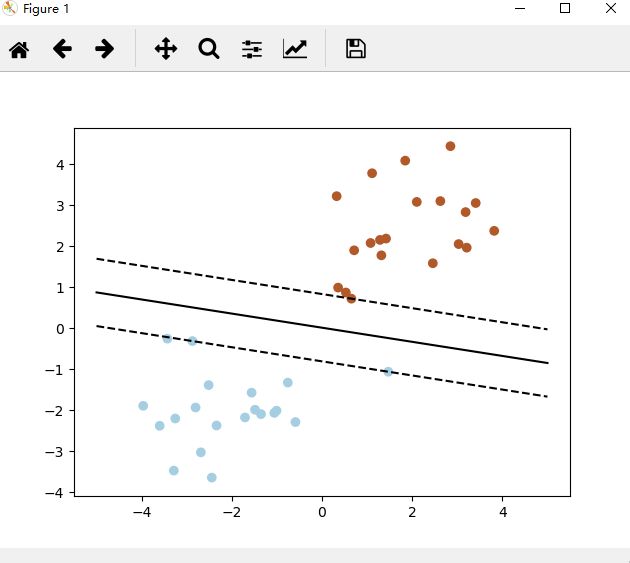
5.2 sklearn画出决定界限
import numpy as np
import pylab as pl
from sklearn import svm
# we create 40 separable points
X = np.r_[np.random.randn(20, 2) - [2, 2], np.random.randn(20, 2) + [2, 2]]
Y = [0]*20 +[1]*20 # 前20个点归类为0 ,后20个为1
# fit the model
clf = svm.SVC(kernel='linear')
clf.fit(X, Y)
# get the separating hyperplane
w = clf.coef_[0]
a = -w[0]/w[1]
xx = np.linspace(-5, 5)
yy = a*xx - (clf.intercept_[0])/w[1]
# plot the parallels to the separating hyperplane that pass through the support vectors
b = clf.support_vectors_[0] # 第一个支持向量
yy_down = a*xx + (b[1] - a*b[0])
b = clf.support_vectors_[-1] # 最后一个支持向量
yy_up = a*xx + (b[1] - a*b[0])
print("w: ", w)
print("a: ", a)
# print "xx: ", xx
# print "yy: ", yy
print("support_vectors_: ", clf.support_vectors_)
print("clf.coef_: ", clf.coef_)
# switching to the generic n-dimensional parameterization of the hyperplan to the 2D-specific equation
# of a line y=a.x +b: the generic w_0x + w_1y +w_3=0 can be rewritten y = -(w_0/w_1) x + (w_3/w_1)
# plot the line, the points, and the nearest vectors to the plane
pl.plot(xx, yy, 'k-')
pl.plot(xx, yy_down, 'k--')
pl.plot(xx, yy_up, 'k--')
pl.scatter(clf.support_vectors_[:, 0], clf.support_vectors_[:, 1],
s=80, facecolors='none')
pl.scatter(X[:, 0], X[:, 1], c=Y, cmap=pl.cm.Paired)
pl.axis('tight')
pl.show()
运行结果:
5.3 利用SVM进行人脸识别实例
from __future__ import print_function
from time import time
import logging
import matplotlib.pyplot as plt
from sklearn.cross_validation import train_test_split
from sklearn.datasets import fetch_lfw_people
from sklearn.grid_search import GridSearchCV
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.decomposition import RandomizedPCA
from sklearn.svm import SVC
print(__doc__)
# Display progress logs on stdout
logging.basicConfig(level=logging.INFO, format='%(asctime)s %(message)s')
###############################################################################
# Download the data, if not already on disk and load it as numpy arrays
lfw_people = fetch_lfw_people(min_faces_per_person=70, resize=0.4)
# introspect the images arrays to find the shapes (for plotting)
n_samples, h, w = lfw_people.images.shape
# for machine learning we use the 2 data directly (as relative pixel
# positions info is ignored by this model)
X = lfw_people.data
n_features = X.shape[1]
# the label to predict is the id of the person
y = lfw_people.target
target_names = lfw_people.target_names
n_classes = target_names.shape[0]
print("Total dataset size:")
print("n_samples: %d" % n_samples)
print("n_features: %d" % n_features)
print("n_classes: %d" % n_classes)
###############################################################################
# Split into a training set and a test set using a stratified k fold
# split into a training and testing set
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25)
###############################################################################
# Compute a PCA (eigenfaces) on the face dataset (treated as unlabeled
# dataset): unsupervised feature extraction / dimensionality reduction
n_components = 150
print("Extracting the top %d eigenfaces from %d faces"
% (n_components, X_train.shape[0]))
t0 = time()
pca = RandomizedPCA(n_components=n_components, whiten=True).fit(X_train) # 将高维特征值降维
print("done in %0.3fs" % (time() - t0))
eigenfaces = pca.components_.reshape((n_components, h, w))
print("Projecting the input data on the eigenfaces orthonormal basis")
t0 = time()
X_train_pca = pca.transform(X_train)
X_test_pca = pca.transform(X_test)
print("done in %0.3fs" % (time() - t0))
###############################################################################
# Train a SVM classification model
print("Fitting the classifier to the training set")
t0 = time()
param_grid = {'C': [1e3, 5e3, 1e4, 5e4, 1e5],
'gamma': [0.0001, 0.0005, 0.001, 0.005, 0.01, 0.1], }
clf = GridSearchCV(SVC(kernel='rbf', class_weight='auto'), param_grid)
clf = clf.fit(X_train_pca, y_train)
print("done in %0.3fs" % (time() - t0))
print("Best estimator found by grid search:")
print(clf.best_estimator_)
###############################################################################
# Quantitative evaluation of the model quality on the test set
print("Predicting people's names on the test set")
t0 = time()
y_pred = clf.predict(X_test_pca)
print("done in %0.3fs" % (time() - t0))
print(classification_report(y_test, y_pred, target_names=target_names))
print(confusion_matrix(y_test, y_pred, labels=range(n_classes)))
###############################################################################
# Qualitative evaluation of the predictions using matplotlib
def plot_gallery(images, titles, h, w, n_row=3, n_col=4):
"""Helper function to plot a gallery of portraits"""
plt.figure(figsize=(1.8 * n_col, 2.4 * n_row))
plt.subplots_adjust(bottom=0, left=.01, right=.99, top=.90, hspace=.35)
for i in range(n_row * n_col):
plt.subplot(n_row, n_col, i + 1)
plt.imshow(images[i].reshape((h, w)), cmap=plt.cm.gray)
plt.title(titles[i], size=12)
plt.xticks(())
plt.yticks(())
# plot the result of the prediction on a portion of the test set
def title(y_pred, y_test, target_names, i):
pred_name = target_names[y_pred[i]].rsplit(' ', 1)[-1]
true_name = target_names[y_test[i]].rsplit(' ', 1)[-1]
return 'predicted: %s\ntrue: %s' % (pred_name, true_name)
prediction_titles = [title(y_pred, y_test, target_names, i)
for i in range(y_pred.shape[0])]
plot_gallery(X_test, prediction_titles, h, w)
# plot the gallery of the most significative eigenfaces
eigenface_titles = ["eigenface %d" % i for i in range(eigenfaces.shape[0])]
plot_gallery(eigenfaces, eigenface_titles, h, w)
plt.show()
【注】:本文为麦子学院机器学习课程的学习笔记
相关学习链接:
http://blog.pluskid.org/?p=632
http://blog.csdn.net/v_july_v/article/details/7624837