VXLAN详解
VXLAN技术是目前SDN解决方案中最流行的技术,在SDN的学习和测试过程中,我也对VXLAN技术进行了一些深入的理解和研究,而在讲VXLAN技术前也必须先介绍下overlay网络架构,下面简单说说我对overlay组网以及vxlan协议的理解。
一、overlay网络简介
overlay网络的诞生很大程度上是因为云计算、虚拟化相关技术的发展,传统的网络无法满足于规模大、灵活性要求高的云数据中心的要求,于是便有了overlay网络的概念。在介绍overlay网络之前,首先说明一个问题,在SDN非常火爆的今天,很多人认为overlay是一种SDN的解决方案,把openflow跟overlay对立或者并列,其实这个不对。overlay只是一种组网方案,openflow是一个控制协议,所以实际网络中,可以是这样的:控制器通过openflow协议控制vSwitch来构建一个overlay网络。
1)云计算、虚拟化对传统网络的挑战
虚拟机迁移范围受到网络架构限制
由于虚拟机迁移的网络属性要求,其从一个物理机上迁移到另一个物理机上,要求虚拟机不间断业务,则需要其IP地址、MAC地址等参数维保持不变,如此则要求业务网络是一个二层网络,且要求网络本身具备多路径多链路的冗余和可靠性。传统的网络生成树(STPSpaning Tree Protocol)技术不仅部署繁琐,且协议复杂,网络规模不宜过大,限制了虚拟化的网络扩展性。基于各厂家私有的的IRF/vPC等设备级的(网络N:1)虚拟化技术,虽然可以简化拓扑简化、具备高可靠性的能力,但是对于网络有强制的拓扑形状限制,在网络的规模和灵活性上有所欠缺,只适合小规模网络构建,且一般适用于数据中心内部网络。而为了大规模网络扩展的TRILL/SPB/FabricPath/VPLS等技术,虽然解决了上述技术的不足,但对网络有特殊要求,即网络中的设备均要软硬件升级而支持此类新技术,带来部署成本的上升。
虚拟机规模受网络规格限制
在大二层网络环境下,数据流均需要通过明确的网络寻址以保证准确到达目的地,因此网络设备的二层地址表项大小(即MAC地址表),成为决定了云计算环境下虚拟机的规模的上限,并且因为表项并非百分之百的有效性,使得可用的虚机数量进一步降低,特别是对于低成本的接入设备而言,因其表项一般规格较小,限制了整个云计算数据中心的虚拟机数量,但如果其地址表项设计为与核心或网关设备在同一档次,则会提升网络建设成本。虽然核心或网关设备的MAC与ARP规格会随着虚拟机增长也面临挑战,但对于此层次设备能力而言,大规格是不可避免的业务支撑要求。减小接入设备规格压力的做法可以是分离网关能力,如采用多个网关来分担虚机的终结和承载,但如此也会带来成本的上升。
网络隔离/分离能力限制
当前的主流网络隔离技术为VLAN(或VPN),在大规模虚拟化环境部署会有两大限制:一是VLAN数量在标准定义中只有12个比特单位,即可用的数量为4000个左右,这样的数量级对于公有云或大型虚拟化云计算应用而言微不足道,其网络隔离与分离要求轻而易举会突破4000;二是VLAN技术当前为静态配置型技术(只有EVB/VEPA的802.1Qbg技术可以在接入层动态部署VLAN,但也主要是在交换机接主机的端口为常规部署,上行口依然为所有VLAN配置通过),这样使得整个数据中心的网络几乎为所有VLAN被允许通过(核心设备更是如此),导致任何一个VLAN的未知目的广播数据会在整网泛滥,无节制消耗网络交换能力与带宽。
对于小规模的云计算虚拟化环境,现有的网络技术如虚拟机接入感知(VEPA/802.1Qbg)、数据中心二层网络扩展(IRF/vPC/TRILL/FabricPath)、数据中心间二层技术(OTV/EVI/TRILL)等可以很好的满足业务需求,上述限制不成为瓶颈。然而,完全依赖于物理网络设备本身的技术改良,目前看来并不能完全解决大规模云计算环境下的问题,一定程度上还需要更大范围的技术革新来消除这些限制,以满足云计算虚拟化的网络能力需求。在此驱动力基础上,逐步演化出Overlay的虚拟化网络技术趋势。
2)Overlay技术介绍
Overlay在网络技术领域,指的是一种网络架构上叠加的虚拟化技术模式,其大体框架是对基础网络不进行大规模修改的条件下,实现应用在网络上的承载,并能与其它网络业务分离,并且以基于IP的基础网络技术为主。其实这种模式是以对传统技术的优化而形成的。早期的就有标准支持了二层Overlay技术,如RFC3378(Ethernet in IP),就是早期的在IP上的二层Overlay技术。并且基于Ethernet over GRE的技术,H3C与Cisco都在物理网络基础上发展了各自的私有二层Overlay技术——EVI(Ethernet Virtual Interconnection)与OTV(Overlay Transport Virtualization)。EVI与OTV都主要用于解决数据中心之间的二层互联与业务扩展问题,并且对于承载网络的基本要求是IP可达,部署上简单且扩展方便。
随着云计算虚拟化的驱动,基于主机虚拟化的Overlay技术出现,在服务器的Hypervisor内vSwitch上支持了基于IP的二层Overlay技术,从更靠近应用的边缘来提供网络虚拟化服务,其目的是使虚拟机的部署与业务活动脱离物理网络及其限制,使得云计算的网络形态不断完善。主机的vSwitch支持基于IP的Overlay之后,虚机的二层访问直接构建Overlay之上,物理网不再感知虚机的诸多特性,由此,Overlay可以构建在数据中心内,也可以跨越数据中心之间。当然这样一来硬件交换机便被通道化,地位岌岌可危,因此以cisco为代表的传统老牌硬件厂商开始发力,将overlay技术集成了到了硬件的交换机上,所以现在overlay技术的也就分成了硬件overlay和软件overlay两个方向。
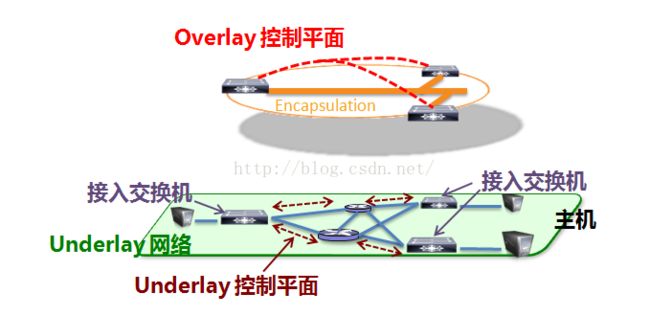
3)Overlay网络如何解决当前的主要问题
上文中提到的传统网络的三个问题,落到实际中看就是以下四个问题,我们分别看看overlay网络是如何解决的:
问题1:云计算中需要一个弹性的二层网络,而现有的大二层技术的扩展能力都不够。
如何解决:overlay网络的本质是在三层网络中实现二层网络的扩展。三层网络可以通过路由的方式在网络中分发,而路由网络本身并无特殊网络结构限制,具备良性大规模扩展能力,并且对设备本身无特殊要求,以高性能路由转发为佳,且路由网络本身具备很强的的故障自愈能力、负载均衡能力。并且三层网络还规避了二层网络的种种弊端,使得整个网络扩展性强且更加健壮。而二层网络如何在三层网络中得到扩展,在传统的网络中是无法实现的,overlay网络中主要靠的是封装技术来实现,具体实现方式后面VXLAN技术的时候会详细介绍。
问题2:大二层网络下,需要维护一个非常庞大的mac和arp表项,尤其是TOR交换机的mac地址表大小可能会影响整个fabric的规模。
如何解决:由于overlay组网中,网络设备互联多采用三层互联的方式,这样arp表就无需泛洪到全网,所以每个tor交换机仅仅需要维护一张本地的mac地址表即可。
问题3:云计算网络的多租户的情况下,vlan数量不够,并且租户隔离困难;
如何解决:在Overlay技术中引入了类似12比特VLANID的用户标识,支持千万级以上的用户标识,并且在Overlay中沿袭了云计算“租户”的概念,称之为Tenant ID(租户标识),用24或64比特表示。
问题4:二层过大导致的BUM(广播、单播、组播问题)问题;
如何解决:首先overlay组网是一个三层网络,三层网络就可以有效的避免传统二层中的非正常BUM的流量(比如风暴问题),而overlay组网通常和云环境以及SDN一起使用,所以正常的BUM流量也是基于虚机创建来生成的,不会产生多余的流量。
二、VXLAN技术介绍
目前在overlay技术领域有三大技术路线:VXLAN、NVGRE、STT,其中最火的就是VXLAN技术,包括vmware、cisco、h3c、华为等多个虚拟化以及传统网络厂商,都是以VXLAN技术来构建自己的SDN解决方案。
1)VXLAN的报文格式:
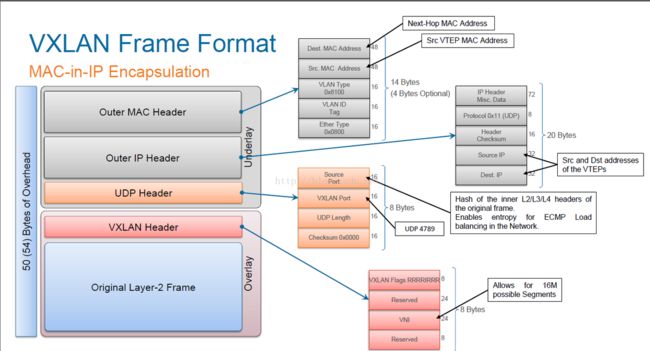
VXLAN报文是在原始的二层报文前面再封装一个新的报文,新的报文中和传统的以太网报文类似,拥有源目mac、源目ip等元组。当原始的二层报文来到vtep节点后会被封装上VXLAN包头(在VXLAN网络中把可以封装和解封装VXLAN报文的设备称为vtep,vtep可以是虚拟switch也可以是物理switch),打上VXLAN包头的报文到了目标的vtep后会将VXLAN包头解封装,并获取原始的二层报文。outer mac header以及outer ip header里面的相关元组信息都是vtep的信息,和原始的二层报文没有任何关系。所在数据包在源目vtep节点之间的传输和原始的二层报文是毫无关系的,依靠的是外层的包头完成。
除此之外还有几个字段需要关注:1、在VXLAN Header报文中封装了24bit的VXLAN ID(VNI),前文中提到的vlan的扩展、租户的扩展就是依靠这个VXLAN ID来实现的;2、在UDP header里面有一个source port的字段,用于VXLAN网络节点之间ECMP的hash;3、在VXLAN Header里的reserved字段,作为保留字段,很多厂商都会加以运用来实现自己组网的一些特性。
2)VXLAN的控制和转发平面
- 数据平面—隧道机制
- 控制平面—改进的二层协议
3)VXLAN的报文转发:
- VXLAN报文转发过程:
报文解析:对收到的上行报文进行解析,得到后续处理所需要的各种信息如外层IP头、以太网头,以及VXLAN报头等;入接口信息获取:根据报文接收端口的配置信息来决定是否需要进行VXLAN上行报文处理;如果需要进行VXLAN上行报文的处理,则还将获得VXLAN ID的映射关系,该VXLAN ID的映射关系可通过VLAN或源MAC地址来标记VXLAN ID;VXLAN ID确定:根据之前获得的VXLAN ID的映射关系进行查表,如VXLAN ID用VLAN标记时,用入接口 ID和VLAN ID作为关键字进行查找,在查找结果的输出中可以获得转发需要的VXLAN ID;二层转发查表:根据报文的目的MAC地址和VXLAN ID共同作为关键字进行查表,获得该报文的目的地以及编辑方式。(如果是组播报文,则针对每一个组播组成员,获得对应的目的地以及编辑方式,后续处理将针对每一个组播组成员依次处理;在二层转发表查表模块中,通常需要设置一条默认条目,这样在查表的时候必然可以返回结果。通常情况下,广播、组播和未知单播报文都可以使用该条目,其目的是使当前报文洪泛到虚拟转发域中的所有成员);出口信息获取:根据转发表决定的目的地获取出接口的信息;报文封装:根据转发表决定的封装信息,进行相应的封装,包括VXLAN头、UDP头、外层IP头、外层以太网头的封装;报文转发:从相应的目的端口发送出去,从而完成VXLAN上行报文的处理过程。
下行报文处理:下行报文是指vtep收到从IP网络发来的带有VXLAN封装的报文。
报文解析:对收到的报文进行解析,得到后续处理所需要的各种信息如外层IP头、以太网头,以及VXLAN报头等;
入接口信息获取:根据报文接收端口的配置信息以及当前报文的封装结构,来决定是否需要进行VXLAN下行报文处理,只有当报文具有VXLAN封装,并且外层目的IP是本接入点需要处理的时候,才会进入后续的解封装,否则仅仅执行普通的路由处理;
解封装:根据入接口信息,使用外层目的IP、源IP和封装在报文中的VXLAN ID—起作为关键字进行查表,获得解封装信息。然后去掉报文的外层IP头、以太网头,以及VXLAN报头,并且获得VXLAN报头中所携带的VXLAN ID;
二层转发表查表:根据内层的目的MAC地址和封装在报文中的VXLAN ID共同作为关键字进行查表,得到报文的处理信息,该处理信息包括目的端口和编辑信息,由于此时不需要对报文进行封装,因此只可能有一些编辑信息,如VLAN。(当查表结果是组播的话,则需要进行组播复制,然后获取每一个组播成员的目的端口和编辑信息。在二层转发表查表模块中,通常需要设置一条默认条目,这样在查表的时候必然可以返回结果。通常情况下,广播、组播和未知单播报文都可以使用该条目,其目的是使当前报文洪泛到虚拟转发域中的所有成员。)
出接口信息获取:根据查表的结果,得到需要转发出去的端口信息;
报文编辑:根据查表结果和目的端口的配置,对内层报文进行必要的编辑,然后交给报文转发模块进行转发。在报文编辑模块中,最主要的作用是根据VXLAN ID映射出在目的端口虚拟机上所对应的VLAN ID,以便使服务器可以识别,发送给对应的虚拟机;
报文转发:从相应的目的端口发送出去,从而完成VXLAN下行报文的处理过程。
- ARP报文转发:
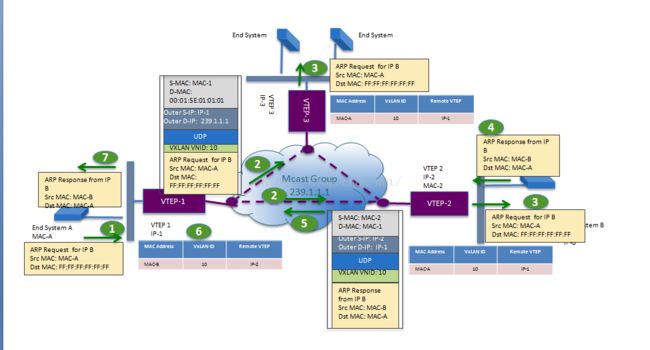
ARP报文转发过程:
1、主机A向主机B发出ARP Request,Src MAC为MAC-A,Dst MAC为全f;
2、ARP Request报文到达vtep-1后,vtep-1对其封装VXLAN包头,其中外层的Src MAC为vtep-1的MAC-1,Dst MAC为组播mac地址, Src ip为vtep-1的IP-1,Dst ip为组播ip地址,并且打上了VXLAN VNID:10。由于vtep之间是三层网络互联的,广播包无法穿越三层网络,所以只能借助组播来实现arp报文的泛洪。通常情况下一个组播地址对应一个VNID,同时可能会对应一个租户或者对应一个vrf网络,通过VNID进行租户之间的隔离。
3、打了VXLAN头的报文转发到了其他的vtep上,进行VXLAN头解封装,原始的ARP Request报文被转发给了vtep下面的主机,并且在vtep上生成一条MAC-A(主机A的mac)、VXLAN ID、IP-1(vtep-1的ip)的对应表项;
4、主机B收到ARP请求,回复ARP Response,Src MAC:MAC-B、Dst MAC:MAC-A;
5、ARP Response报文到达vtep-2后,被打上VXLAN的包头,此时外层的源目mac和ip以及VXLAN ID是根据之前在vtep-2上的MAC-A、VXLAN ID、IP-1对应表项来封装的,所以ARP Response是以单播的方式回复给主机A;
6、打了VXLAN头的报文转发到vtep-1后,进行VXLAN头的解封装,原始的ARP Response报文被转发给了主机A;
7、主机A收到主机B返回的ARP Response报文,整个ARP请求完成。
说明:这种用组播泛洪ARP报文的方式是VXLAN技术早期的方式,这种方式也是有一些缺点,比如产生一些不可控的组播流量等,所以现在很多厂商已经使用了控制器结合南向协议(比如openflow或者一些私有南向协议)来解决ARP的报文转发问题。
- 单播报文转发(同一个Vxlan):

在经过arp报文后,vtep-1和vtep-2上都会形成一个vxlan二层转发表,大致如下(不同厂商表项可能略有不同,但是最主要的是以下元素):
vtep-1:
| MAC | VNI | vtep |
|---|---|---|
| MAC-A | 10 | e1/1 |
| MAC-B | 10 | vtep-2 ip |
vtep-2:
| MAC | VNI | vtep |
|---|---|---|
| MAC-B | 10 | e1/1 |
| MAC-A | 10 | vtep-1 ip |
单播转发的过程如下:
1、host-A将原始报文上送到vtep;
2、根据目的mac和VNI的号(这里的VNI获取是vlan和vxlan的mapping查询出的结果),查找到外层的目的ip是vtep-2 ip,然后将外层的源目ip分别封装为vtep-1 ip和vtep-2 ip,源目mac为下一段链路的源目mac;
3、数据包穿越ip网络;
4、根据VNI、外层的源目ip,进行解封装,通过VNI和目的mac查表,得到目的端口是e1/1;
5、host-B接受此原始报文,并回复host-A,回复过程同上一致。
- 不同Vxlan之间转发:
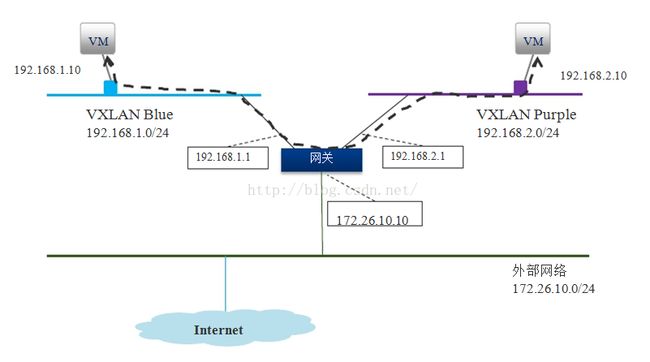
- Vxlan和vlan之间转发

4)典型的VXLAN组网模式
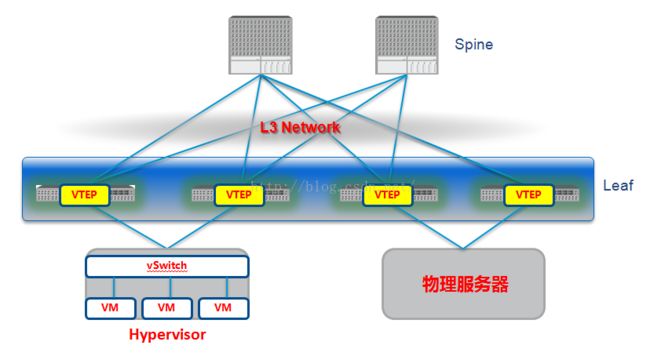
软件模式:

软件模式中vtep功能由vswitch实现,图中物理交换网络是一个L3的网络,实际软件overlay的场景下物理的交换网并不一定要是一个L3的网络,只要物理服务器的ip互相可达即可,当然L3的网络是一个比较好的选择,因为L3的网络扩展性比L2好,L2网络一大就会有各种二层问题的存在,比如广播泛洪、未知单播泛洪,比如TOR的mac问题,这个前文已经讲了很多,这里就不多讲了。
优点:1、硬件交换机的转发平面和控制平面解耦,更加灵活,不受物理设备和厂商的限制;
2、现有的硬件网络设备无需进行替换。(如果现有物理设备是L2的互联网络也可以使用软件overlay的方式,当然L3互联更佳,overlay的网络还是建议L3的方式)
缺点:1、vSwitch转发性能问题,硬件交换机转发基本都是由ASIC芯片来完成,ASIC芯片是专门为交换机转发而设计的芯片,而vSwitch的转发是由X86的CPU来完成,当vSwitch作为vtep后并且增加4-7层服务外加分布式路由的情况下,性能、可靠性上可能会存在问题;
2、无法实现虚拟网络和物理服务器网络的共同管理;
3、如果是用商业的解决方案,则软件层面被厂商绑死,如果选用开源或自研的vswitch,对于传统行业有一定的难度和风险。如果是传统行业的公司选用了vmware的云平台,可以考虑使用vmware NSX;
4、软件overlay容易造成管理上的混乱,特别对于传统行业来说,overlay网络到底是网络运维管还是云平台运维管,会有一些利益冲突。不过这个并不是一个技术问题,在云计算环境下,类似这种问题会越来越多。
案例:互联网公司用软件overlay的还挺多,下面附上几个的方案简介,设计一些商业解决方案和一些开源的解决方案:
UCloud的“公有云SDN网络实践”分享
浙江电信云资源池引入VxLAN的部署初探(NSX)
硬件模式:
硬件模式中vtep功能由物理交换机来实现,硬件overlay解决方案中物理网络一般都是L3的网络。
优点:1、硬件交换机作为vtep转发性能比较有保证;
2、虚拟化网络和物理服务器网络可以统一管理;
3、向下兼容各种的虚拟化平台(商业或开源)。
缺点:1、各硬件交换机厂商的解决方案难有兼容性,可能会出现被一个厂商绑死的情况;
2、老的硬件交换机基本上芯片都不支持VXLAN技术,所以要使用vxlan组网,会出现大规模的设备迭代;
案例:硬件overlay主要是Cisco、华为、H3C这种传统的硬件厂商提供解决方案,下面链接一个华为的的案例:
美团云携手华为SDN解决方案
软硬件混合模式:
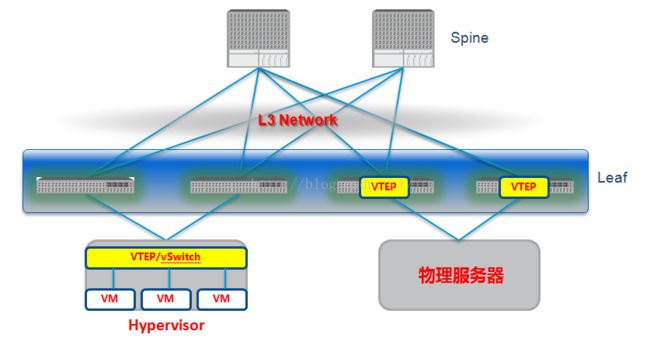
软硬件混合模式是一种比较折中的解决方案,虚拟化平台上依然使用vSwitch作为vtep,而对于物理服务器使其接入物理的vtep交换机。
优点:整合了软、硬件模式的优缺点,是一种比较理想的overlay网络模型;
缺点:落地起来架构比较复杂,统一性比较差,硬件交换机和软件交换机同时作为vtep,管理平台上兼容性是个问题。
案例:这个解决方案目前一些硬件的交换机厂商会提供(比如华为),还有就是一些研发能力比较强的互联网公司会选择这个方案。
附上一个kitty大神写的阿里的实践:OpenFlow与VxLAN在云网络的应用
本文转载自:https://blog.csdn.net/sinat_31828101/article/details/50504656