window下使用CMUSphinx实现中文识别(生成语言模型来定向识别)
上一篇博客https://blog.csdn.net/zxy13826134783/article/details/103645228实现的中文识别效果很不好,并不是我们想要的,我们可以自己利用训练工具训练语言模型和声学模型,做到定向开发,关于语言模型和声学模型的介绍,可以参考
https://blog.csdn.net/zouxy09/article/details/7942784
https://www.cnblogs.com/bhlsheji/p/4514475.html
网上介绍的训练语言模型和声学模型都是基于Linux系统,基于window系统的我没有找到,经过一阵摸索和研究,训练语言模型算是成功了一半
步骤如下:
1 下载训练工具cmuclmtk(免安装的)
网址:https://sourceforge.net/projects/cmusphinx/files/cmuclmtk/0.7/
选择window系统版的cmuclmtk-0.7-win32.zip
你也可以通过我的网盘下载,建议下载网盘的,因为网盘里有一个我下面测试程序使用到的wav音频文件,不然满大街去找wav文件比较浪费时间
网盘链接:https://pan.baidu.com/s/1M51sgzruBTv8KOdjazM7Cw
提取码:uyie
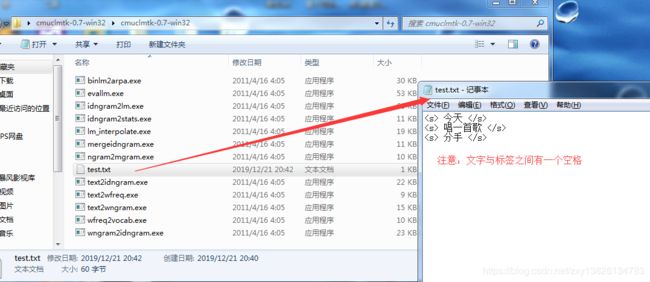
2 解压压缩包,并在压缩后的文件夹里面新建一个名为test的txt格式的语言模型文件(为何这样写呢?完全是根据我测试的wav文件里面的语言的内容来编写的),并编辑如下(注意另存为utf-8编码格式)
今天
唱一首歌
分手
如下图所示:
3 cd 切换到解压后的目录
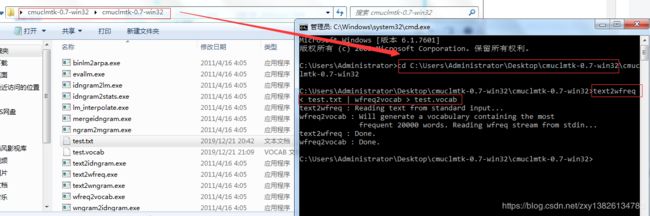
使用命令
text2wfreq < test.txt | wfreq2vocab > test.vocab生成词频文件
如下图:
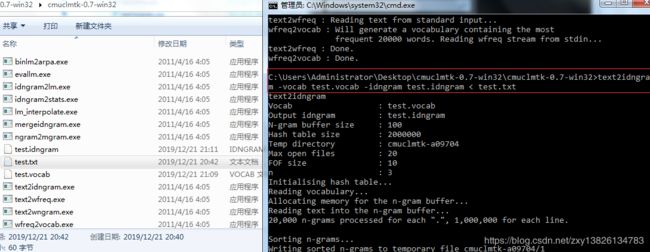
使用命令
text2idngram -vocab test.vocab -idngram test.idngram < test.txt生成arpa文件,如下图:
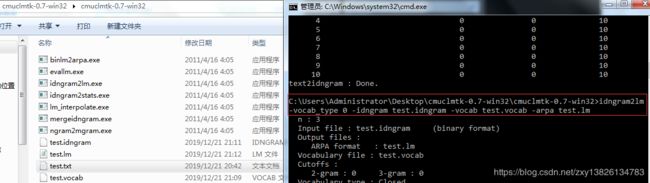
使用命令
idngram2lm -vocab_type 0 -idngram test.idngram -vocab test.vocab -arpa test.lm生成lm语言模型文件,如下图:
这样我们得到了test.lm语言模型文件待用
4 下载中文声学模型和对应的字典
https://sourceforge.net/projects/cmusphinx/files/Acoustic%20and%20Language%20Models/Mexican%20Spanish/
具体如何下载和如何操作请参考我上一篇博客https://blog.csdn.net/zxy13826134783/article/details/103645228
5 在python或者Anaconda安装目录下speech_recognition\pocketsphinx-data下新建你自己的语言模型文件,我的目录是
C:\AnacondaInstall\Lib\site-packages\speech_recognition\pocketsphinx-data
新建一个文件夹my-lan
把下载的zh_cn.cd_cont_5000文件夹重命名为acoustic-model、zh_cn.dic中dic改为pronounciation-dictionary.dict并把改名后的文件拷贝到my-lan文件夹内,把刚才生成的test.lm改名为language-model.lm.bin并把改名后的拷贝到my-lan文件夹内,如下图:

5 编写程序测试(注意,如果是使用记事本进行编辑代码,要另存为utf-8格式)
# -*- coding: utf-8 -*-
# /usr/bin/python
# Python版本:3.6.3
import speech_recognition as sr
r = sr.Recognizer() #调用识别器
test = sr.AudioFile("当.wav") #导入语音文件
with test as source:
audio = r.record(source)
type(audio)
c=r.recognize_sphinx(audio, language='my-lan') #识别输出
print(c)
运行结果如下:
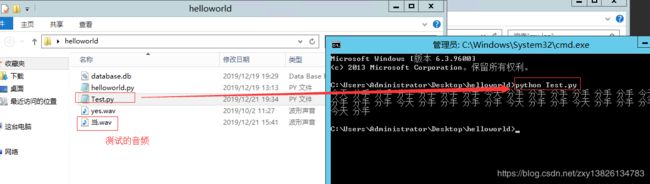
这样,识别出来的就是我们定制的文本了
还没有解决的问题:
开始我使用自己编写的字典,一直没有输出,后来我使用中文语言包的字典就有输出了,可能我编写字典的方式不对,最好是使用自己编写的字典
当然,你也可以使用在线的方式进行生成,网址如下:http://www.speech.cs.cmu.edu/tools/lmtool-new.html
参考博客
https://www.jianshu.com/p/f4e90b91efba
https://www.cnblogs.com/lijieqiong/p/4810863.html
https://cmusphinx.github.io/wiki/tutoriallm/#training-an-arpa-model-with-srilm
https://blog.csdn.net/itas109/article/details/78999477