Elastic:使用机器学习 API 创建一个任务
针对机器学习的API,我们可以在地址:https://www.elastic.co/guide/en/elasticsearch/reference/7.8/ml-apis.html 找到。这次,我们就其中的一些 API 来做一个简单的介绍。
删除一个已有的 Job
我们可以通过如下如下的 API 来查询 datafeed 的状态:
GET _cat/ml/datafeedsdatafeed-response-request-by-app stopped 1006 712
datafeed-total-request stopped 1006 12
datafeed-unusual-user stopped 2000 6上面显示,我们有三个 datafeed,他们的状态是停止的状态。如果它是运行的状态,我们可以通过如下的命令来停止它:
POST _ml/datafeeds/datafeed-total-request/_stop上面的 datafeed-total-request 就是 datafeed 的 ID。
我们可以通过如下的方式来删除一个 datafeed ID:
DELETE _ml/datafeeds/datafeed-unusual-user那么我们可以重新来查看现有的 datafeed ID 列表:
GET _cat/ml/datafeedsdatafeed-response-request-by-app stopped 1006 712
datafeed-total-request stopped 1006 12在机器学习的界面上,我们可以看到:

我们可以通过如下的方式来关掉一个 Job:
POST _ml/anomaly_detectors/unusual-user/_close一旦被关掉,我们可以执行如下的命令来删除这个:
DELETE _ml/anomaly_detectors/unusual-user然后,我们可以通过如下的 API 来查看信息:
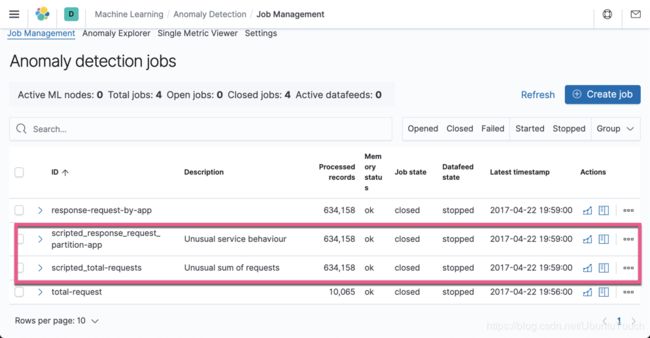
GET _ml/anomaly_detectors那么,我们可以看到剩下的两个 anomaly_detector。我们可以检查 Machine Learning 的 UI。

使用 API 来创建一个 single metric job
当然,如果你已经有一个这样的 job,你可以按照我上面介绍的方法把这个 job 进行删除。再安装如下的方式来创建。
PUT _ml/anomaly_detectors/scripted_total-requests
{
"description": "Unusual sum of requests",
"analysis_config": {
"bucket_span": "10m",
"detectors": [
{
"detector_description": "Sum of total",
"function": "sum",
"field_name": "total"
}
]
},
"data_description": {
"time_field": "@timestamp",
"time_format": "epoch_ms"
}
}打入上面的命令:
{
"job_id" : "scripted_total-requests",
"job_type" : "anomaly_detector",
"job_version" : "7.8.0",
"description" : "Unusual sum of requests",
"create_time" : 1593418388764,
"analysis_config" : {
"bucket_span" : "10m",
"detectors" : [
{
"detector_description" : "Sum of total",
"function" : "sum",
"field_name" : "total",
"detector_index" : 0
}
],
"influencers" : [ ]
},
"analysis_limits" : {
"model_memory_limit" : "1024mb",
"categorization_examples_limit" : 4
},
"data_description" : {
"time_field" : "@timestamp",
"time_format" : "epoch_ms"
},
"model_snapshot_retention_days" : 10,
"daily_model_snapshot_retention_after_days" : 1,
"results_index_name" : "shared",
"allow_lazy_open" : false
}我们打开 Machine Learning 的界面:

从这里我们可以看见已经创建了一个叫做 scritpted_total_requests 的 Job,但是它还没有datafeed。
接下来,我来创建一个 datafeed:
PUT _ml/datafeeds/datafeed-scripted_total-requests
{
"job_id": "scripted_total-requests",
"indexes": [
"server-metrics"
],
"scroll_size": 1000
}上面的返回结果:
{
"datafeed_id" : "datafeed-scripted_total-requests",
"job_id" : "scripted_total-requests",
"query_delay" : "99278ms",
"indices" : [
"server-metrics"
],
"query" : {
"match_all" : { }
},
"scroll_size" : 1000,
"chunking_config" : {
"mode" : "auto"
},
"delayed_data_check_config" : {
"enabled" : true
},
"indices_options" : {
"expand_wildcards" : [
"open"
],
"ignore_unavailable" : false,
"allow_no_indices" : true,
"ignore_throttled" : true
}
}我们在 Machine Learning 的界面查看:
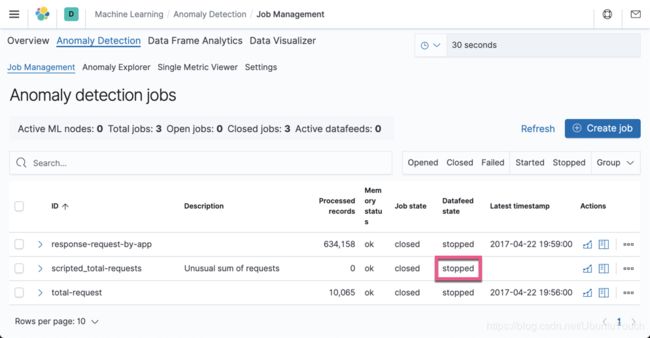
显然这次,我们看到了一个增加的 datafeed,但是它的状态是 stopped。
我们接下来就是打开这个机器学习的 job:
POST _ml/anomaly_detectors/scripted_total-requests/_open{
"opened" : true,
"node" : "oN68xZaMSA2v8G1xEHg65g"
}我们再次查看 Machine Learning 的界面,还是没有什么变化。接下来,我们需启动这个任务:
POST _ml/datafeeds/datafeed-scripted_total-requests/_start?start=1970-01-02T10:00:00Z&end=2017-06-01T00:00:00Z{
"started" : true,
"node" : "oN68xZaMSA2v8G1xEHg65g"
}重新再查看 Machine Learning 的界面:

从上面,我们可以看出来,在 processoed records 里有显示和 response-request-by-app 一样多的文档,说明它已经运行完成,并停止了。
我们可以通过如下的命令来关闭这个 job:
POST _ml/anomaly_detectors/scripted_total-requests/_close上面的命令显示的结果是:
{
"closed" : true
}为了自动化着整个的过程,我创建了如下的一个脚本:
create_single_metric.sh
HOST='localhost'
PORT=9200
JOB_ID='scripted_total-requests'
INDEX_NAME='server-metrics'
ROOT="http://${HOST}:${PORT}/_ml"
JOBS="${ROOT}/anomaly_detectors"
DATAFEEDS="${ROOT}/datafeeds"
USERNAME=elastic
PASSWORD=changeme
printf "\n== Script started for... $JOBS/$JOB_ID"
printf "\n\n== Stopping datafeed... "
curl -s -u ${USERNAME}:${PASSWORD} -X POST ${DATAFEEDS}/datafeed-${JOB_ID}/_stop
printf "\n\n== Deleting datafeed... "
curl -s -u ${USERNAME}:${PASSWORD} -X DELETE ${DATAFEEDS}/datafeed-${JOB_ID}
printf "\n\n== Closing job... "
curl -s -u ${USERNAME}:${PASSWORD} -X POST ${JOBS}/${JOB_ID}/_close
printf "\n\n== Deleting job... "
curl -s -u ${USERNAME}:${PASSWORD} -X DELETE ${JOBS}/${JOB_ID}
printf "\n\n== Creating job... \n"
curl -s -u ${USERNAME}:${PASSWORD} -X PUT -H 'Content-Type: application/json' ${JOBS}/${JOB_ID}?pretty -d '{
"description" : "Unusual sum of requests",
"analysis_config" : {
"bucket_span":"10m",
"detectors" :[
{
"detector_description": "Sum of total",
"function": "sum",
"field_name": "total"
}
]},
"data_description" : {
"time_field":"@timestamp",
"time_format": "epoch_ms"
}
}'
printf "\n\n== Creating Datafeed... \n"
curl -s -u ${USERNAME}:${PASSWORD} -X PUT -H 'Content-Type: application/json' ${DATAFEEDS}/datafeed-${JOB_ID}?pretty -d '{
"job_id" : "'"$JOB_ID"'",
"indexes" : [
"'"$INDEX_NAME"'"
],
"scroll_size" : 1000
}'
printf "\n\n== Opening job for ${JOB_ID}... "
curl -u ${USERNAME}:${PASSWORD} -X POST ${JOBS}/${JOB_ID}/_open
printf "\n\n== Starting datafeed-${JOB_ID}... "
curl -u ${USERNAME}:${PASSWORD} -X POST "${DATAFEEDS}/datafeed-${JOB_ID}/_start?start=1970-01-02T10:00:00Z&end=2017-06-01T00:00:00Z"
sleep 20s
printf "\n\n== Closing job for ${JOB_ID}... "
curl -u ${USERNAME}:${PASSWORD} -X POST ${JOBS}/${JOB_ID}/_close
printf "\n\n== Finished ==\n\n"同样地,如果你想创建一个 mulit mertic job,那么你可以使用如下的脚本:
create_multi_metric.sh
HOST='localhost'
PORT=9200
JOB_ID='scripted_response_request_partition-app'
INDEX_NAME='server-metrics'
ROOT="http://${HOST}:${PORT}/_ml"
JOBS="${ROOT}/anomaly_detectors"
DATAFEEDS="${ROOT}/datafeeds"
USERNAME=elastic
PASSWORD=changeme
printf "\n== Script started for... $JOBS/$JOB_ID"
printf "\n\n== Stopping datafeed... "
curl -s -u ${USERNAME}:${PASSWORD} -X POST ${DATAFEEDS}/datafeed-${JOB_ID}/_stop
printf "\n\n== Deleting datafeed... "
curl -s -u ${USERNAME}:${PASSWORD} -X DELETE ${DATAFEEDS}/datafeed-${JOB_ID}
printf "\n\n== Closing job... "
curl -s -u ${USERNAME}:${PASSWORD} -X POST ${JOBS}/${JOB_ID}/_close
printf "\n\n== Deleting job... "
curl -s -u ${USERNAME}:${PASSWORD} -X DELETE ${JOBS}/${JOB_ID}
printf "\n\n== Creating job... \n"
curl -s -u ${USERNAME}:${PASSWORD} -X PUT -H 'Content-Type: application/json' ${JOBS}/${JOB_ID}?pretty -d '{
"description" : "Unusual service behaviour",
"analysis_config" : {
"bucket_span":"10m",
"detectors" :[
{
"detector_description": "Unusual sum for each service",
"function": "sum",
"field_name": "total",
"partition_field_name": "service"
},
{
"detector_description": "Unusually high response for each service",
"function": "high_mean",
"field_name": "response",
"partition_field_name": "service"
}
],
"influencers": ["host"]
},
"data_description" : {
"time_field":"@timestamp",
"time_format": "epoch_ms"
}
}'
printf "\n\n== Creating Datafeed... \n"
curl -s -u ${USERNAME}:${PASSWORD} -X PUT -H 'Content-Type: application/json' ${DATAFEEDS}/datafeed-${JOB_ID}?pretty -d '{
"job_id" : "'"$JOB_ID"'",
"indexes" : [
"'"$INDEX_NAME"'"
],
"scroll_size" : 1000
}'
printf "\n\n== Opening job for ${JOB_ID}... "
curl -u ${USERNAME}:${PASSWORD} -X POST ${JOBS}/${JOB_ID}/_open
printf "\n\n== Starting datafeed-${JOB_ID}... "
curl -u ${USERNAME}:${PASSWORD} -X POST "${DATAFEEDS}/datafeed-${JOB_ID}/_start?start=1970-01-02T10:00:00Z&end=2017-06-01T00:00:00Z"
sleep 20s
printf "\n\n== Stopping datafeed-${JOB_ID}... "
curl -u ${USERNAME}:${PASSWORD} -X POST "${DATAFEEDS}/datafeed-${JOB_ID}/_stop"
printf "\n\n== Closing job for ${JOB_ID}... "
curl -u ${USERNAME}:${PASSWORD} -X POST ${JOBS}/${JOB_ID}/_close
printf "\n\n== Finished ==\n\n"运行上面的两个脚本,我们可以看到: