Kubernetes 源码剖析之 WorkQueue 队列 | 文末送书

Docker 技术鼻祖系列
文末直接送 5 本《Kubernetes 源码剖析》。
在 Kubernetes 系统中,组件之间通过 HTTP 协议进行通信,在不依赖任何中间件的情况下需要保证消息的实时性、可靠性、顺序性等。那么 Kubernetes 是如何做到的呢?答案就是 Informer 机制。Kubernetes 的其他组件都是通过 client-go 的 Informer 机制与 Kubernetes API Server 进行通信的。
而 Informer 又需要和 Reflector、Delta FIFO Queue、Workqueue 等协同工作,具体可以参考我之前的一篇文章:从 Kubernetes 资源控制到开放应用模型,控制器的进化之旅。
本文主要通过 WorkQueue 的源码来分析其工作原理。
WorkQueue 称为工作队列,Kubernetes 的 WorkQueue 队列与普通 FIFO(先进先出,First-In, First-Out)队列相比,实现略显复杂,它的主要功能在于标记和去重,并支持如下特性。
有序:按照添加顺序处理元素(item)。
去重:相同元素在同一时间不会被重复处理,例如一个元素在处理之前被添加了多次,它只会被处理一次。
并发性:多生产者和多消费者。
标记机制:支持标记功能,标记一个元素是否被处理,也允许元素在处理时重新排队。
通知机制:ShutDown 方法通过信号量通知队列不再接收新的元素,并通知 metric goroutine 退出。
延迟:支持延迟队列,延迟一段时间后再将元素存入队列。
限速:支持限速队列,元素存入队列时进行速率限制。限制一个元素被重新排队(Reenqueued)的次数。
Metric:支持 metric 监控指标,可用于 Prometheus 监控。
WorkQueue 支持 3 种队列,并提供了 3 种接口,不同队列实现可应对不同的使用场景,分别介绍如下。
Interface:FIFO 队列接口,先进先出队列,并支持去重机制。
DelayingInterface:延迟队列接口,基于 Interface 接口封装,延迟一段时间后再将元素存入队列。
RateLimitingInterface:限速队列接口,基于 DelayingInterface 接口封装,支持元素存入队列时进行速率限制。
1. FIFO 队列
FIFO 队列支持最基本的队列方法,例如插入元素、获取元素、获取队列长度等。另外,WorkQueue 中的限速及延迟队列都基于 Interface 接口实现,其提供如下方法:
// 代码路径:vendor/k8s.io/client-go/util/workqueue/queue.go
type Interface interface {
Add(item interface{})
Len() int
Get() (item interface{}, shutdown bool)
Done(item interface{})
ShutDown()
ShuttingDown() bool
}
FIFO 队列 Interface 方法说明如下。
Add:给队列添加元素(item),可以是任意类型元素。
Len:返回当前队列的长度。
Get:获取队列头部的一个元素。
Done:标记队列中该元素已被处理。
ShutDown:关闭队列。
ShuttingDown:查询队列是否正在关闭。
FIFO 队列数据结构如下:
type Type struct {
queue []t
dirty set
processing set
cond *sync.Cond
shuttingDown bool
metrics queueMetrics
unfinishedWorkUpdatePeriod time.Duration
clock clock.Clock
}
FIFO 队列数据结构中最主要的字段有 queue、dirty 和 processing。其中 queue 字段是实际存储元素的地方,它是 slice 结构的,用于保证元素有序;dirty 字段非常关键,除了能保证去重,还能保证在处理一个元素之前哪怕其被添加了多次(并发情况下),但也只会被处理一次;processing 字段用于标记机制,标记一个元素是否正在被处理。应根据 WorkQueue 的特性理解源码的实现,FIFO 存储过程如图 5-9 所示:

图5-9 FIFO存储过程
通过 Add 方法往 FIFO 队列中分别插入 1、2、3 这 3 个元素,此时队列中的 queue 和 dirty 字段分别存有 1、2、3 元素,processing 字段为空。然后通过 Get 方法获取最先进入的元素(也就是 1 元素),此时队列中的 queue 和 dirty 字段分别存有 2、3 元素,而 1 元素会被放入 processing 字段中,表示该元素正在被处理。最后,当我们处理完 1 元素时,通过 Done 方法标记该元素已经被处理完成,此时队列中的 processing 字段中的 1 元素会被删除。
如图 5-9 所示,这是 FIFO 队列的存储流程,在正常的情况下,FIFO 队列运行在并发场景下。高并发下如何保证在处理一个元素之前哪怕其被添加了多次,但也只会被处理一次?下面进行讲解,FIFO 并发存储过程如图 5-10 所示。

图5-10 FIFO并发存储过程
如图 5-10 所示,在并发场景下,假设 goroutine A 通过 Get 方法获取 1 元素,1 元素被添加到 processing 字段中,同一时间,goroutine B 通过 Add 方法插入另一个 1 元素,此时在 processing 字段中已经存在相同的元素,所以后面的 1 元素并不会被直接添加到 queue 字段中,当前 FIFO 队列中的 dirty 字段中存有 1、2、3 元素,processing 字段存有 1 元素。在 goroutine A 通过 Done 方法标记处理完成后,如果 dirty 字段中存有 1 元素,则将 1 元素追加到 queue 字段中的尾部。需要注意的是,dirty 和 processing 字段都是用 Hash Map 数据结构实现的,所以不需要考虑无序,只保证去重即可。
2. 延迟队列
延迟队列,基于 FIFO 队列接口封装,在原有功能上增加了 AddAfter 方法,其原理是延迟一段时间后再将元素插入 FIFO 队列。延迟队列数据结构如下:
// 代码路径:vendor/k8s.io/client-go/util/workqueue/delaying_queue.go
type DelayingInterface interface {
Interface
AddAfter(item interface{}, duration time.Duration)
}
type delayingType struct {
Interface
clock clock.Clock
stopCh chan struct{}
heartbeat clock.Ticker
waitingForAddCh chan *waitFor
metrics retryMetrics
deprecatedMetrics retryMetrics
}
AddAfter 方法会插入一个 item(元素)参数,并附带一个 duration(延迟时间)参数,该 duration 参数用于指定元素延迟插入 FIFO 队列的时间。如果 duration 小于或等于 0,会直接将元素插入 FIFO 队列中。
delayingType 结构中最主要的字段是 waitingForAddCh,其默认初始大小为 1000,通过 AddAfter 方法插入元素时,是非阻塞状态的,只有当插入的元素大于或等于 1000 时,延迟队列才会处于阻塞状态。waitingForAddCh 字段中的数据通过 goroutine 运行的 waitingLoop 函数持久运行。延迟队列运行原理如图 5-11 所示。

图5-11 延迟队列运行原理
如图 5-11 所示,将元素 1 放入 waitingForAddCh 字段中,通过 waitingLoop 函数消费元素数据。当元素的延迟时间不大于当前时间时,说明还需要延迟将元素插入 FIFO 队列的时间,此时将该元素放入优先队列(waitForPriorityQueue)中。当元素的延迟时间大于当前时间时,则将该元素插入 FIFO 队列中。另外,还会遍历优先队列(waitForPriorityQueue)中的元素,按照上述逻辑验证时间。
3. 限速队列
限速队列,基于延迟队列和 FIFO 队列接口封装,限速队列接口(RateLimitingInterface)在原有功能上增加了 AddRateLimited、Forget、NumRequeues 方法。限速队列的重点不在于 RateLimitingInterface 接口,而在于它提供的 4 种限速算法接口(RateLimiter)。其原理是,限速队列利用延迟队列的特性,延迟某个元素的插入时间,达到限速目的。RateLimiter 数据结构如下:
// 代码路径:vendor/k8s.io/client-go/util/workqueue/default_rate_limiters.go
type RateLimiter interface {
When(item interface{}) time.Duration
Forget(item interface{})
NumRequeues(item interface{}) int
}
限速队列接口方法说明如下。
When:获取指定元素应该等待的时间。
Forget:释放指定元素,清空该元素的排队数。
NumRequeues:获取指定元素的排队数。
注意:这里有一个非常重要的概念——限速周期。限速周期是指从执行
AddRateLimited方法到执行完Forget方法之前的时间。如果该元素被Forget方法处理完,从清空队列数。
下面会分别详解 WorkQueue 提供的 4 种限速算法,应对不同的场景,这 4 种限速算法分别如下。
令牌桶算法(BucketRateLimiter)。
排队指数算法(ItemExponentialFailureRateLimiter)。
计数器算法(ItemFastSlowRateLimiter)。
混合模式(MaxOfRateLimiter),将多种限速算法混合使用。
令牌桶算法
令牌桶算法是通过 Go 语言的第三方库 golang.org/x/time/rate 实现的。令牌桶算法内部实现了一个存放 token(令牌)的“桶”,初始时“桶”是空的,token 会以固定速率往“桶”里填充,直到将其填满为止,多余的 token 会被丢弃。每个元素都会从令牌桶得到一个 token,只有得到 token 的元素才允许通过(accept),而没有得到 token 的元素处于等待状态。令牌桶算法通过控制发放 token 来达到限速目的。令牌桶算法原理如图 5-12 所示。

图5-12 令牌桶算法原理
WorkQueue 在默认的情况下会实例化令牌桶,代码示例如下:
rate.NewLimiter(rate.Limit(10), 100)
在实例化 rate.NewLimiter 后,传入 r 和 b 两个参数,其中 r 参数表示每秒往“桶”里填充的 token 数量,b 参数表示令牌桶的大小(即令牌桶最多存放的 token 数量)。我们假定 r 为 10,b 为 100。假设在一个限速周期内插入了 1000 个元素,通过 r.Limiter.Reserve().Delay 函数返回指定元素应该等待的时间,那么前 b(即 100)个元素会被立刻处理,而后面元素的延迟时间分别为 item100/100ms、item101/200ms、item102/300ms、item103/400ms,以此类推。
排队指数算法
排队指数算法将相同元素的排队数作为指数,排队数增大,速率限制呈指数级增长,但其最大值不会超过 maxDelay。元素的排队数统计是有限速周期的,一个限速周期是指从执行 AddRateLimited 方法到执行完 Forget 方法之间的时间。如果该元素被 Forget 方法处理完,则清空排队数。排队指数算法的核心实现代码示例如下:
// 代码路径:vendor/k8s.io/client-go/util/workqueue/default_rate_limiters.go
r.failures[item] = r.failures[item] + 1
backoff := float64(r.baseDelay.Nanoseconds()) * math.Pow(2, float64(exp))
if backoff > math.MaxInt64 {
return r.maxDelay
}
该算法提供了 3 个主要字段:failures、baseDelay、maxDelay。其中,failures 字段用于统计元素排队数,每当 AddRateLimited 方法插入新元素时,会为该字段加 1;另外,baseDelay 字段是最初的限速单位(默认为 5ms),maxDelay 字段是最大限速单位(默认为 1000s)。排队指数增长趋势如图 5-13 所示。
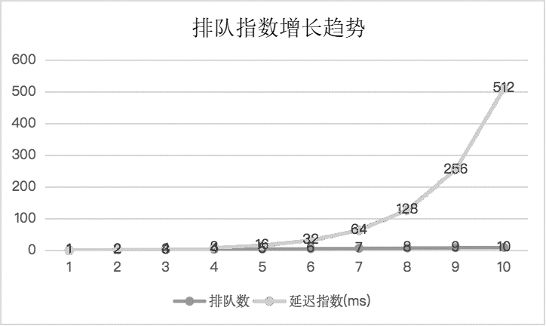
图5-13 排队指数增长趋势
限速队列利用延迟队列的特性,延迟多个相同元素的插入时间,达到限速目的。
注意:在同一限速周期内,如果不存在相同元素,那么所有元素的延迟时间为
baseDelay;而在同一限速周期内,如果存在相同元素,那么相同元素的延迟时间呈指数级增长,最长延迟时间不超过baseDelay。
们假定 baseDelay 是 1 * time.Millisecond,maxDelay 是 1000 * time.Second。假设在一个限速周期内通过 AddRateLimited 方法插入 10 个相同元素,那么第 1 个元素会通过延迟队列的 AddAfter 方法插入并设置延迟时间为 1ms(即 baseDelay),第 2 个相同元素的延迟时间为 2ms,第 3 个相同元素的延迟时间为 4ms,第 4 个相同元素的延迟时间为 8ms,第 5 个相同元素的延迟时间为 16ms……第 10 个相同元素的延迟时间为 512ms,最长延迟时间不超过 1000s(即 maxDelay)。
计数器算法
计数器算法是限速算法中最简单的一种,其原理是:限制一段时间内允许通过的元素数量,例如在 1 分钟内只允许通过 100 个元素,每插入一个元素,计数器自增 1,当计数器数到 100 的阈值且还在限速周期内时,则不允许元素再通过。但 WorkQueue 在此基础上扩展了 fast 和 slow 速率。
计数器算法提供了 4 个主要字段:failures、fastDelay、slowDelay 及 maxFastAttempts。其中,failures 字段用于统计元素排队数,每当 AddRateLimited 方法插入新元素时,会为该字段加 1;而 fastDelay 和 slowDelay 字段是用于定义 fast、slow 速率的;另外,maxFastAttempts 字段用于控制从 fast 速率转换到 slow 速率。计数器算法核心实现的代码示例如下:
r.failures[item] = r.failures[item] + 1
if r.failures[item] <= r.maxFastAttempts {
return r.fastDelay
}
return r.slowDelay
假设 fastDelay 是 5 * time.Millisecond,slowDelay 是 10 * time.Second,maxFastAttempts 是 3。在一个限速周期内通过 AddRateLimited 方法插入 4 个相同的元素,那么前 3 个元素使用 fastDelay 定义的 fast 速率,当触发 maxFastAttempts 字段时,第 4 个元素使用 slowDelay 定义的 slow 速率。
混合模式
混合模式是将多种限速算法混合使用,即多种限速算法同时生效。例如,同时使用排队指数算法和令牌桶算法,代码示例如下:
func DefaultControllerRateLimiter() RateLimiter {
return NewMaxOfRateLimiter(
NewItemExponentialFailureRateLimiter(5*time.Millisecond, 1000*time.Second),
&BucketRateLimiter{Limiter: rate.NewLimiter(rate.Limit(10), 100)},
)
}赠书福利
关注公众帐号云原生实验室,后台回复:源码获取抽奖入口

????长按上方二维码关注,回复 源码 即可参与
本次将随机抽取5位,每人获得《Kubernetes 源码剖析》书籍一本,感谢电子工业出版社博文视点提供的书籍
活动截止时间:7月9日18:00
没抽中的小伙伴也可以通过如下入口直接购买~


你可能还喜欢
点击下方图片即可阅读


云原生是一种信仰 ????

扫码关注公众号
后台回复◉k8s◉获取史上最方便快捷的 Kubernetes 高可用部署工具,只需一条命令,连 ssh 都不需要!


点击 "阅读原文" 获取更好的阅读体验!
❤️给个「在看」,是对我最大的支持❤️