fasthttp 快在哪里
坊间传言 fasthttp 在某些场景下比 nginx 还要快,说明 fasthttp 中应该是做足了优化。我们来做一些相关的验证工作。
先是简单的 hello server 压测。下面的结果是在 mac 上得到的,linux 下可能会有差异。
fasthttp:
wrk -c36 -t12 -d 5s http://127.0.0.1:8080
Running 5s test @ http://127.0.0.1:8080
12 threads and 36 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 267.58us 42.44us 0.90ms 79.18%
Req/Sec 11.05k 391.97 11.79k 87.42%
672745 requests in 5.10s, 89.18MB read
Requests/sec: 131930.78
Transfer/sec: 17.49MB
标准库:
wrk -c36 -t12 -d 5s http://127.0.0.1:8080
Running 5s test @ http://127.0.0.1:10002
12 threads and 36 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 310.94us 163.45us 14.41ms 93.42%
Req/Sec 9.74k 1.01k 12.80k 75.82%
593327 requests in 5.10s, 63.37MB read
Requests/sec: 116348.87
Transfer/sec: 12.43MB
rust 的 actix,编译选项带 --release:
wrk -c36 -t12 -d 5s http://127.0.0.1:9999
Running 5s test @ http://127.0.0.1:9999
12 threads and 36 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 267.31us 20.52us 622.00us 86.07%
Req/Sec 11.11k 364.03 11.64k 82.68%
676329 requests in 5.10s, 68.37MB read
Requests/sec: 132629.68
Transfer/sec: 13.41MB
好家伙,虽然是 hello 服务,但是 fasthttp 在性能上竟然赶上 rust 编写的服务了,确实有点夸张。这也间接证明了,“某些场景”至少可能真的和不带 GC 的语言性能差不多。
说明 fasthttp 里所做的优化是值得我们做点研究的。不过 fasthttp 搞的这些优化点也并不是很神奇,首先是很常见的 goroutine workerpool,对创建的 goroutine 进行了重用,其本身的 workerpool 结构:
type workerPool struct {
// Function for serving server connections.
// It must leave c unclosed.
WorkerFunc ServeHandler
.....
ready []*workerChan
}
核心就是 ready 数组,该数组的元素是已经创建出来的 goroutine 的 job channel。
type workerChan struct {
lastUseTime time.Time
ch chan net.Conn
}
这么多年过去了,基本的 workerpool 的模型还是没什么变化。最早大概是在 handling 1 million requests with go 提到,fasthttp 中的也只是稍有区别。
具体的请求处理流程也比较简单:
tcp accept -> workerpool.Serve -> 从 workerpool 的 ready 数组中获取一个 channel -> 将当前已 accept 的连接发送到 channel 中 -> 对端消费者调用 workerFunc
这里这个 workerFunc 其实就是 serveConn,之所以不写死成 serveConn 主要还是为了在测试的时候能替换掉做 mock,不新鲜。
主要的 serve 流程:
func (s *Server) serveConn(c net.Conn) (err error) {
for {
ctx := s.acquireCtx(c)
br = acquireReader(ctx) // or br, err = acquireByteReader(&ctx)
// read request header && body
bw = acquireWriter(ctx)
s.Handler(ctx) // 这里就是 listenAndServe 传入的那个 handler
if br != nil {
releaseReader(s, br)
}
if bw != nil {
releaseWriter(s, bw)
}
if ctx != nil {
s.releaseCtx(ctx)
}
}
}
在整个 serve 流程中,几乎所有对象全部都进行了重用,ctx(其中有 Request 和 Response 结构),reader,writer,body read buffer。可见作者对于内存重用达到了偏执的程度。
同时,对于 header 的处理,rawHeaders 是个大 byte 数组。解析后的 header 的 value 如果是字符串类型,其实都是指向这个大 byte 数组的,不会重复生成很多小对象:

如果是我们自己写这种 kv 结构的 header,大概率就直接 map[string][]string 上了。
通过阅读 serveConn 的流程我们也可以发现比较明显的问题,在执行完用户的 Handler 之后,fasthttp 会将所有相关的对象全部释放并重新推进对象池中,在某些场景下,这样做显然是不合适的,举个例子:
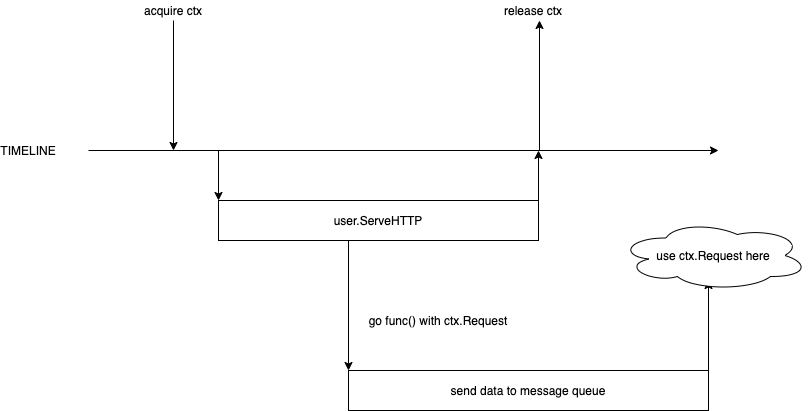
当用户流程中异步启动了 goroutine,并且在 goroutine 中使用 ctx.Request 之类对象时就会遇到并发问题,因为在 fasthttp 的主流程中认为 ctx 的生命周期已经结束,将该 ctx 放回了 sync.Pool,然而用户依然在使用。想要避免这种问题,用户需要将各种 fasthttp 返回的对象人肉拷贝一遍。
从这点上来看,基于 sync.Pool 的性能优化往往也是有代价的,无论在什么场景下使用 sync.Pool,都需要对应用程序中的对象生命周期进行一定的假设,这种假设并不见得适用于 100% 的场景,否则这些手段早就进标准库,而非开源库了。
对于库的用户来说,这样的优化手段轻则带来更高的心智负担,重则是线上 bug。在使用开源库之前,还是要多多注意。非性能敏感的业务场景,还是用标准库比较踏实。
参考资料
[1] https://github.com/valyala/fasthttp
[2] https://medium.com/smsjunk/handling-1-million-requests-per-minute-with-golang-f70ac505fca