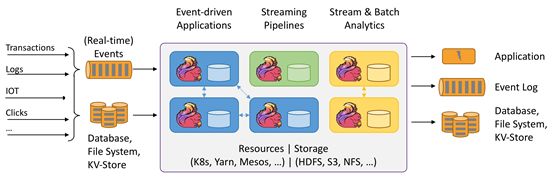
- window10下编译hadoop报错:Failed to execute goal org.apache.maven.plugins:maven-antrun-plugin:1.7:
huangxgc
hadoophadoopwindows
Windows10下buildhadoop2.7.3报错:Failedtoexecutegoalorg.apache.maven.plugins:maven-antrun-plugin:1.7:[ERROR]Failedtoexecutegoalorg.apache.maven.plugins:maven-antrun-plugin:1.7:run(dist)onprojecthadoop-hdf
- 快速开始,使用 VSCode 开发 Vue 项目如何配置语法高亮和自动格式化
dadiyang
Vue学习笔记前端填坑之旅VueIDEVSCode插件配置
关于IDE开发Vue项目,一般使用VSCode/WebStorm/Atom等IDE,推荐使用VSCode。而VSCode原生不支持Vue语法高亮和自动格式化等功能,需要通过插件来支持。安装插件点击首选项->扩展,安装以下插件:Vetur–vue必备插件,用于语法高亮和代码提示AutoCloseTag–自动完成标签,如输入时,自动添加AutoRenameTag–重命名开始或结束标签时,自动将配对的开
- 图文详解 MapReduce on YARN
Shockang
大数据技术体系大数据mapreduceyarn
前言本文隶属于专栏《1000个问题搞定大数据技术体系》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!本专栏目录结构和参考文献请见1000个问题搞定大数据技术体系正文权威版本——《Hadoop权威指南第3版》1.作业提交MRrunJob从RM获取新的作业ID作业客户端检査作业的输出说明,计算输入分片并将作业资源(包括作业JAR、配置和分片信息)复制到HDFS。通过调用R
- 深入MapReduce——从MRv1到Yarn
黄雪超
大数据基础#深入MapReducemapreduce大数据hadoop
引入我们前面篇章有提到,和MapReduce的论文不太一样。在Hadoop1.0实现里,每一个MapReduce的任务并没有一个独立的master进程,而是直接让调度系统承担了所有的worker的master的角色,这就是Hadoop1.0里的JobTracker。在Hadoop1.0里,MapReduce论文里面的worker就是TaskTracker,用来执行map和reduce的任务。而分配
- RDD 算子全面解析:从基础到进阶与面试要点
天冬忘忧
Sparkspark大数据
Spark的介绍与搭建:从理论到实践_spark环境搭建-CSDN博客Spark的Standalone集群环境安装与测试-CSDN博客PySpark本地开发环境搭建与实践-CSDN博客Spark程序开发与提交:本地与集群模式全解析-CSDN博客SparkonYARN:Spark集群模式之Yarn模式的原理、搭建与实践-CSDN博客Spark中RDD的诞生:原理、操作与分区规则-CSDN博客Spar
- Hadoop学习笔记 --- YARN执行流程与工作原理
杨鑫newlfe
数据仓库大数据挖掘与大数据应用案例YARNHadoop大数据资源调度数据仓库
一、YARN简述首先介绍一下YARN在Hadoop2.0版本引进的资源管理系统,直接从MapReduceV1演化而来(由于引擎的功能缺陷);原因是将MapReduce1中的JobTracker的资源管理和作业调度两个功能分开,分别由ResourceManager和ApplicationMaster进行实现;ResourceManager:负责整个集群的资源管理和调度ApplicationMaste
- 【深入浅出 Yarn 架构与实现】1-1 设计理念与基本架构
大数据王小皮
深入浅出Yarn架构与实现架构hadoop大数据yarnjava
一、Yarn产生的背景Hadoop2之前是由HDFS和MR组成的,HDFS负责存储,MR负责计算。一)MRv1的问题耦合度高:MR中的jobTracker同时负责资源管理和作业控制两个功能,互相制约。可靠性差:管理节点是单机的,有单点故障的问题。资源利用率低:基于slot的资源分配模型。机器会将资源划分成若干相同大小的slot,并划定哪些是mapslot、哪些是reduceslot。无法支持多种计
- 【YARN】yarn 基础知识整理——hadoop1.0与hadoop2.0区别、yarn总结
时间的美景
HadoopYarnhadoophadoop1hadoop2大数据
文章目录1.hadoop1.0和hadoop2.0区别1.1hadoop1.01.1.1HDFS1.1.2Mapreduce1.2hadoop2.01.2.1HDFS1.2.2Yarn/MapReduce22.Yarn2.1Yarn(YetAnotherResourceNegotiator)概述2.2Yarn的优点2.3Yarn重要概念2.3.1ResourceManager2.3.2NodeMa
- 搭建Hadoop与Hive环境
达达玲玲
hadoophive大数据
当搭建Hadoop与Hive环境时,以下是每个步骤的详细操作说明:1.安装并配置CentOS7操作系统:-下载CentOS7ISO镜像文件,并通过虚拟机或物理机安装CentOS7操作系统。-在安装过程中,为系统分配必要的网络、用户和权限。2.安装Java开发环境:-下载适合您的系统的JavaJDK版本。-使用命令或GUI工具安装JavaJDK。-配置JAVA_HOME环境变量:-打开终端,输入以下
- 大数据技术之MapReduce
wespten
HadoopHiveSpark大数据安全大数据mapreducehadoop
一、MapReduce概述1、MapReduce简介MapReduce是一个分布式运算程序的编程框架,是基于Hadoop的数据分析计算的核心框架。MapReduce处理过程分为两个阶段:Map和Reduce。Map负责把一个任务分解成多个任务,Reduce负责把分解后多任务处理的结果汇总。2、MapReduce优缺点MapReduce优点:MapReduce易于编程:它简单的实现一些接口,就可以完
- anaconda中pyspark_自学大数据——9 Anaconda安装与使用pyspark
步六孤陆
首先从Anaconda官网上下载Anaconda。一、解压安装包sudobashAnaconda3-2020.07-Linux-x86_64.shchown-Rhadoop:hadoop/opt/anaconda/vi/etc/profileexportANACONDA_HOME=/opt/anacondaexportPATH=$PATH:$ANACONDA_HOME/bin:source/etc
- PySpark数据处理过程简析
AI天才研究院
Python实战自然语言处理人工智能语言模型编程实践开发语言架构设计
作者:禅与计算机程序设计艺术1.简介PySpark是ApacheSpark的PythonAPI,可以用Python进行分布式数据处理,它在内存中利用了ApacheHadoopYARN资源调度框架对数据进行并行处理。PySpark可以直接使用Hadoop文件系统、HDFS来存储数据,也可以通过S3、GCS、ADLS等云存储平台保存数据。因此,在不同的数据源之间移动数据时,只需要复制一次数据就可以完成
- 2022-02-09大数据学习日志——PySpark——Spark快速入门&Standalone集群
王络不稳定
sparkbigdata大数据
第一部分Spark快速入门01_Spark快速入门【Anaconda软件安装】[掌握]使用Python编写Spark代码,首先需要安装Python语言包,此时安装Anaconda科学数据分析包。Anaconda指的是一个开源的Python发行版本,其包含了conda、Python等180多个科学包及其依赖项。Anaconda是跨平台的,有Windows、MacOS、Linux版本。#下载地址:ht
- PySpark
rainyrainbow
大数据hadoop
1.PySpark的搭建https://blog.csdn.net/qq_36330643/article/details/78429109PySpark是Spark为Python开发者提供的API,位于$SPARK_HOME/bin目录,其依赖于Py4J。在Pycharm中配置使用spark1.在Pycharm中新建python项目,解释器使用的是python3.4File=>Settings切
- spark2如何集成到cdh里
蘑菇丁
经验hadoop大数据+机器学习+oracle
最近做性能测试需要spark2测试下和spark1.6性能有多大差别,官方文档里写着可以集成,但是自己怎么搞都不行,折磨了3天的时间,目前终于把spark2集成到集群里了我安装的是最新版本的下载spark2安装包wgethttp://archive.cloudera.com/beta/spark2/parcels/latest/SPARK2-2.0.0.cloudera.beta2-1.cdh5.
- kafka开启kerberos
蘑菇丁
debian运维
一、基本环境准备创建票据创建Kerberos主体(Principal):使用kadmin.local或kadmin命令为Zookeeper和Kafka服务创建Kerberos主体。例如:注意有几台机器创建几个kadmin.local-q"addprinc-randkeyzookeeper/
[email protected]"kadmin.local-q"addprinc-rand
- ranger-kms安装
蘑菇丁
eclipsejavaide
默认已安装ranger-admin和mysql服务。Ranger组件服务默认都在/opt/bigdata.test/core/ranger目录下安装。解压安装包[hadoop~]$cd/opt/ranger[hadoop@ranger]$tar-xzvfranger-2.1.0-kms.tar.gz[hadoop@xranger]$mvranger-2.1.0-kmsranger/ranger-k
- ansible批量生产kerberos票据,并批量分发到所有其他主机脚本
蘑菇丁
ansiblehadoop学习笔记eclipsejavaide
-name:ConfigureKerberosforHadoopUsershosts:hadoop_serversbecome:nogather_facts:novars:kerberos_server:hadoop1.xuexi.comkeytab_file_path:/home/hadoop/keys/hadoop.keytabprincipals:-nn/-dn/-yarn/-starroc
- 大数据之Spark运行流程
「已注销」
Spark大数据sparkhadoop
文章目录前言(一)SparkOnYarn集群的Client模式运行流程(二)SparkOnYarn集群的Cluster模式运行流程总结前言上篇文章有讨论到SparkOnYarn的两种部署模式,如果有不清楚的地方,可以再看看,附上对应文章的链接:Spark的部署模式,本篇文章主要讨论SparkOnYarn两种部署模式的运行流程。(一)SparkOnYarn集群的Client模式运行流程该模式的Dri
- xgboost-spark-scala
maokunnn
DMxgboostsparkscala
今天学习写scala,拿xgboost试一下~先记一下xgboost调参要点:7.xgboost中比较重要的参数介绍(1)objective[default=reg:linear]定义学习任务及相应的学习目标,可选的目标函数如下:“reg:linear”–线性回归。“reg:logistic”–逻辑回归。“binary:logistic”–二分类的逻辑回归问题,输出为概率。“binary:logi
- 网络爬虫相关软件以及论文检索与推荐网站调研
Q7318
网络爬虫网络爬虫搜索引擎
最近接到一个项目,需要做一个基于网络爬虫技术的论文检索与推荐的网站,所以打算先对市面上已有的基于此技术的软件进行一次统计和分析,以备后面查询使用。一.网络爬虫相关软件1.搜索引擎NutchNutch是一个开源Java实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具。包括全文搜索和Web爬虫。Nutch的创始人是DougCutting,他同时也是Lucene、Hadoop和Avro开源项
- 修改hdfs路径权限
chimchim66
hdfshadoop大数据
目录一、背景二、定位问题三、解决一、背景执行insertoverwritetable报错报错内容如下:二、定位问题看报错日志获取到2个信息,一个网络问题,一个是文件权限问题。网络问题重试还是失败,应该不是因为这个,所以要处理文件的权限。三、解决shell执行以下命令,${hdfs_path}替换成目标表的文件路径/usr/local/service/hadoop/bin/hdfsdfs-chmod
- HDFS升级和回退
小森饭
hdfshadoop大数据
概述作为一个大型的分布式系统,Hadoop内部实现了一套升级机制,当在一个集群上升级Hadoop时,像其他的软件升级一样,可能会有新的bug或一些会影响现有应用的非兼容性变更出现;在任何有实际意义的HDFS系统中,丢失数据是不允许的,更不用说重新搭建启动HDFS了;升级可能成功,也可能失败。如果失败了,那就用rollback进行回滚;如果过了一段时间,系统运行正常,那就可以通过finalize正式
- 大数据平台建设整体架构设计方案
AI天才研究院
ChatGPTAI大模型企业级应用开发实战大数据AI人工智能大厂Offer收割机面试题简历程序员读书硅基计算碳基计算认知计算生物计算深度学习神经网络大数据AIGCAGILLMJavaPython架构设计Agent程序员实现财富自由
《大数据平台建设整体架构设计方案》关键词:大数据平台、分布式存储、分布式计算、数据仓库、数据湖、数据安全、数据质量管理、数据治理、数据挖掘、机器学习、图计算、自然语言处理、Hadoop、Spark、Flink、项目规划、运维管理、最佳实践。摘要:本文将深入探讨大数据平台建设整体架构设计方案,从概述与核心概念、技术栈、建设实践、运维管理以及经验展望等多个方面进行详细阐述。通过梳理大数据平台的核心组成
- python操作HBase
王壮_
大数据Pythonhbase数据库大数据
1.安装happybase和thriftpipinstallhappybasepipinstallthrift2.启动hbase的thrift进程,并指定端口9090hbase-daemon.shstartthrift-p90903.操作HBaseimporthappybaseconnection=happybase.Connection(host='hadoop10',port=9090)tab
- HBase伪分布式安装配置流程
TheMountainGhost
hbase数据库大数据
要配置HBase的伪分布式模式,以下是详细的操作步骤,确保每一步都执行准确。1.准备工作确保已经安装并配置好了Hadoop(伪分布式),因为HBase依赖HDFS。Hadoop已经配置并能够正常运行。Java已经安装并配置好了环境变量。SSH配置免密登录(通常在Hadoop环境中已配置)。2.下载并解压HBase下载HBase安装包并解压到你想要的目录:tar-zxvfhbase-2.4.18-b
- Scala简介
醉游江湖
scala
hadoop生态圈—>javaspark生态圈—>scala1.scala是面向对象的、面向函数的基于静态类型的编程语言。静态语言(强类型语言)静态语言是在编译时变量的数据类型即可确定的语言,多数静态类型语言要求在使用变量之前必须声明数据类型。例如:C++、Java、Delphi、C#,Scala等。scala编译后是字节码文件可以调用java源有的库动态语言(弱类型语言)动态语言是在运行时确定数
- spark官方配置参数详解
我丶怀念的
sparkscalads
以下是整理的Spark中的一些配置参数,官方文档请参考SparkConfiguration。Spark提供三个位置用来配置系统:Spark属性:控制大部分的应用程序参数,可以用SparkConf对象或者Java系统属性设置环境变量:可以通过每个节点的conf/spark-env.sh脚本设置。例如IP地址、端口等信息日志配置:可以通过log4j.properties配置Spark属性Spark属性
- 【spark床头书系列】如何在YARN上启动Spark官网权威详解说明
BigDataMLApplication
sparkspark大数据分布式
【spark床头书系列】如何在YARN上启动Spark官网权威详解说明点击这里看全文文章目录添加其他JAR文件准备工作配置调试应用程序Spark属性重要说明KerberosYARN特定的Kerberos配置Kerberos故障排除配置外部Shuffle服务使用ApacheOozie启动应用程序使用Spark历史服务器替代SparkWebUI官网链接确保HADOOP_CONF_DIR或者YARN_C
- xgboost在spark集群使用指南
一颗小草333
算法mapreducespark数据挖掘
简介XGBoost是一个优化的分布式梯度增强库,具有高效、灵活和可移植性。在梯度增强框架下实现了机器学习算法。XGBoost提供了一种并行树增强(也称为GBDT、GBM),可以快速、准确地解决许多数据科学问题。相同的代码在主要的分布式环境(Hadoop、SGE、MPI)上运行,可以解决数十亿个示例的训练问题。xgb相对于gbt所做的改进:1.2.3.XGBoost可以使用R、python、java
- Java实现的简单双向Map,支持重复Value
superlxw1234
java双向map
关键字:Java双向Map、DualHashBidiMap
有个需求,需要根据即时修改Map结构中的Value值,比如,将Map中所有value=V1的记录改成value=V2,key保持不变。
数据量比较大,遍历Map性能太差,这就需要根据Value先找到Key,然后去修改。
即:既要根据Key找Value,又要根据Value
- PL/SQL触发器基础及例子
百合不是茶
oracle数据库触发器PL/SQL编程
触发器的简介;
触发器的定义就是说某个条件成立的时候,触发器里面所定义的语句就会被自动的执行。因此触发器不需要人为的去调用,也不能调用。触发器和过程函数类似 过程函数必须要调用,
一个表中最多只能有12个触发器类型的,触发器和过程函数相似 触发器不需要调用直接执行,
触发时间:指明触发器何时执行,该值可取:
before:表示在数据库动作之前触发
- [时空与探索]穿越时空的一些问题
comsci
问题
我们还没有进行过任何数学形式上的证明,仅仅是一个猜想.....
这个猜想就是; 任何有质量的物体(哪怕只有一微克)都不可能穿越时空,该物体强行穿越时空的时候,物体的质量会与时空粒子产生反应,物体会变成暗物质,也就是说,任何物体穿越时空会变成暗物质..(暗物质就我的理
- easy ui datagrid上移下移一行
商人shang
js上移下移easyuidatagrid
/**
* 向上移动一行
*
* @param dg
* @param row
*/
function moveupRow(dg, row) {
var datagrid = $(dg);
var index = datagrid.datagrid("getRowIndex", row);
if (isFirstRow(dg, row)) {
- Java反射
oloz
反射
本人菜鸟,今天恰好有时间,写写博客,总结复习一下java反射方面的知识,欢迎大家探讨交流学习指教
首先看看java中的Class
package demo;
public class ClassTest {
/*先了解java中的Class*/
public static void main(String[] args) {
//任何一个类都
- springMVC 使用JSR-303 Validation验证
杨白白
springmvc
JSR-303是一个数据验证的规范,但是spring并没有对其进行实现,Hibernate Validator是实现了这一规范的,通过此这个实现来讲SpringMVC对JSR-303的支持。
JSR-303的校验是基于注解的,首先要把这些注解标记在需要验证的实体类的属性上或是其对应的get方法上。
登录需要验证类
public class Login {
@NotEmpty
- log4j
香水浓
log4j
log4j.rootCategory=DEBUG, STDOUT, DAILYFILE, HTML, DATABASE
#log4j.rootCategory=DEBUG, STDOUT, DAILYFILE, ROLLINGFILE, HTML
#console
log4j.appender.STDOUT=org.apache.log4j.ConsoleAppender
log4
- 使用ajax和history.pushState无刷新改变页面URL
agevs
jquery框架Ajaxhtml5chrome
表现
如果你使用chrome或者firefox等浏览器访问本博客、github.com、plus.google.com等网站时,细心的你会发现页面之间的点击是通过ajax异步请求的,同时页面的URL发生了了改变。并且能够很好的支持浏览器前进和后退。
是什么有这么强大的功能呢?
HTML5里引用了新的API,history.pushState和history.replaceState,就是通过
- centos中文乱码
AILIKES
centosOSssh
一、CentOS系统访问 g.cn ,发现中文乱码。
于是用以前的方式:yum -y install fonts-chinese
CentOS系统安装后,还是不能显示中文字体。我使用 gedit 编辑源码,其中文注释也为乱码。
后来,终于找到以下方法可以解决,需要两个中文支持的包:
fonts-chinese-3.02-12.
- 触发器
baalwolf
触发器
触发器(trigger):监视某种情况,并触发某种操作。
触发器创建语法四要素:1.监视地点(table) 2.监视事件(insert/update/delete) 3.触发时间(after/before) 4.触发事件(insert/update/delete)
语法:
create trigger triggerName
after/before
- JS正则表达式的i m g
bijian1013
JavaScript正则表达式
g:表示全局(global)模式,即模式将被应用于所有字符串,而非在发现第一个匹配项时立即停止。 i:表示不区分大小写(case-insensitive)模式,即在确定匹配项时忽略模式与字符串的大小写。 m:表示
- HTML5模式和Hashbang模式
bijian1013
JavaScriptAngularJSHashbang模式HTML5模式
我们可以用$locationProvider来配置$location服务(可以采用注入的方式,就像AngularJS中其他所有东西一样)。这里provider的两个参数很有意思,介绍如下。
html5Mode
一个布尔值,标识$location服务是否运行在HTML5模式下。
ha
- [Maven学习笔记六]Maven生命周期
bit1129
maven
从mvn test的输出开始说起
当我们在user-core中执行mvn test时,执行的输出如下:
/software/devsoftware/jdk1.7.0_55/bin/java -Dmaven.home=/software/devsoftware/apache-maven-3.2.1 -Dclassworlds.conf=/software/devs
- 【Hadoop七】基于Yarn的Hadoop Map Reduce容错
bit1129
hadoop
运行于Yarn的Map Reduce作业,可能发生失败的点包括
Task Failure
Application Master Failure
Node Manager Failure
Resource Manager Failure
1. Task Failure
任务执行过程中产生的异常和JVM的意外终止会汇报给Application Master。僵死的任务也会被A
- 记一次数据推送的异常解决端口解决
ronin47
记一次数据推送的异常解决
需求:从db获取数据然后推送到B
程序开发完成,上jboss,刚开始报了很多错,逐一解决,可最后显示连接不到数据库。机房的同事说可以ping 通。
自已画了个图,逐一排除,把linux 防火墙 和 setenforce 设置最低。
service iptables stop
- 巧用视错觉-UI更有趣
brotherlamp
UIui视频ui教程ui自学ui资料
我们每个人在生活中都曾感受过视错觉(optical illusion)的魅力。
视错觉现象是双眼跟我们开的一个玩笑,而我们往往还心甘情愿地接受我们看到的假象。其实不止如此,视觉错现象的背后还有一个重要的科学原理——格式塔原理。
格式塔原理解释了人们如何以视觉方式感觉物体,以及图像的结构,视角,大小等要素是如何影响我们的视觉的。
在下面这篇文章中,我们首先会简单介绍一下格式塔原理中的基本概念,
- 线段树-poj1177-N个矩形求边长(离散化+扫描线)
bylijinnan
数据结构算法线段树
package com.ljn.base;
import java.util.Arrays;
import java.util.Comparator;
import java.util.Set;
import java.util.TreeSet;
/**
* POJ 1177 (线段树+离散化+扫描线),题目链接为http://poj.org/problem?id=1177
- HTTP协议详解
chicony
http协议
引言
- Scala设计模式
chenchao051
设计模式scala
Scala设计模式
我的话: 在国外网站上看到一篇文章,里面详细描述了很多设计模式,并且用Java及Scala两种语言描述,清晰的让我们看到各种常规的设计模式,在Scala中是如何在语言特性层面直接支持的。基于文章很nice,我利用今天的空闲时间将其翻译,希望大家能一起学习,讨论。翻译
- 安装mysql
daizj
mysql安装
安装mysql
(1)删除linux上已经安装的mysql相关库信息。rpm -e xxxxxxx --nodeps (强制删除)
执行命令rpm -qa |grep mysql 检查是否删除干净
(2)执行命令 rpm -i MySQL-server-5.5.31-2.el
- HTTP状态码大全
dcj3sjt126com
http状态码
完整的 HTTP 1.1规范说明书来自于RFC 2616,你可以在http://www.talentdigger.cn/home/link.php?url=d3d3LnJmYy1lZGl0b3Iub3JnLw%3D%3D在线查阅。HTTP 1.1的状态码被标记为新特性,因为许多浏览器只支持 HTTP 1.0。你应只把状态码发送给支持 HTTP 1.1的客户端,支持协议版本可以通过调用request
- asihttprequest上传图片
dcj3sjt126com
ASIHTTPRequest
NSURL *url =@"yourURL";
ASIFormDataRequest*currentRequest =[ASIFormDataRequest requestWithURL:url];
[currentRequest setPostFormat:ASIMultipartFormDataPostFormat];[currentRequest se
- C语言中,关键字static的作用
e200702084
C++cC#
在C语言中,关键字static有三个明显的作用:
1)在函数体,局部的static变量。生存期为程序的整个生命周期,(它存活多长时间);作用域却在函数体内(它在什么地方能被访问(空间))。
一个被声明为静态的变量在这一函数被调用过程中维持其值不变。因为它分配在静态存储区,函数调用结束后并不释放单元,但是在其它的作用域的无法访问。当再次调用这个函数时,这个局部的静态变量还存活,而且用在它的访
- win7/8使用curl
geeksun
win7
1. WIN7/8下要使用curl,需要下载curl-7.20.0-win64-ssl-sspi.zip和Win64OpenSSL_Light-1_0_2d.exe。 下载地址:
http://curl.haxx.se/download.html 请选择不带SSL的版本,否则还需要安装SSL的支持包 2. 可以给Windows增加c
- Creating a Shared Repository; Users Sharing The Repository
hongtoushizi
git
转载自:
http://www.gitguys.com/topics/creating-a-shared-repository-users-sharing-the-repository/ Commands discussed in this section:
git init –bare
git clone
git remote
git pull
git p
- Java实现字符串反转的8种或9种方法
Josh_Persistence
异或反转递归反转二分交换反转java字符串反转栈反转
注:对于第7种使用异或的方式来实现字符串的反转,如果不太看得明白的,可以参照另一篇博客:
http://josh-persistence.iteye.com/blog/2205768
/**
*
*/
package com.wsheng.aggregator.algorithm.string;
import java.util.Stack;
/**
- 代码实现任意容量倒水问题
home198979
PHP算法倒水
形象化设计模式实战 HELLO!架构 redis命令源码解析
倒水问题:有两个杯子,一个A升,一个B升,水有无限多,现要求利用这两杯子装C
- Druid datasource
zhb8015
druid
推荐大家使用数据库连接池 DruidDataSource. http://code.alibabatech.com/wiki/display/Druid/DruidDataSource DruidDataSource经过阿里巴巴数百个应用一年多生产环境运行验证,稳定可靠。 它最重要的特点是:监控、扩展和性能。 下载和Maven配置看这里: http
- 两种启动监听器ApplicationListener和ServletContextListener
spjich
javaspring框架
引言:有时候需要在项目初始化的时候进行一系列工作,比如初始化一个线程池,初始化配置文件,初始化缓存等等,这时候就需要用到启动监听器,下面分别介绍一下两种常用的项目启动监听器
ServletContextListener
特点: 依赖于sevlet容器,需要配置web.xml
使用方法:
public class StartListener implements
- JavaScript Rounding Methods of the Math object
何不笑
JavaScriptMath
The next group of methods has to do with rounding decimal values into integers. Three methods — Math.ceil(), Math.floor(), and Math.round() — handle rounding in differen