OpenStack Neutron浅析(四)
传统网络到虚拟化网络的演进
传统网络:
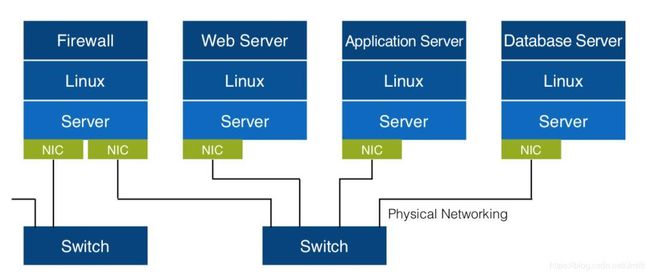
虚拟网络:
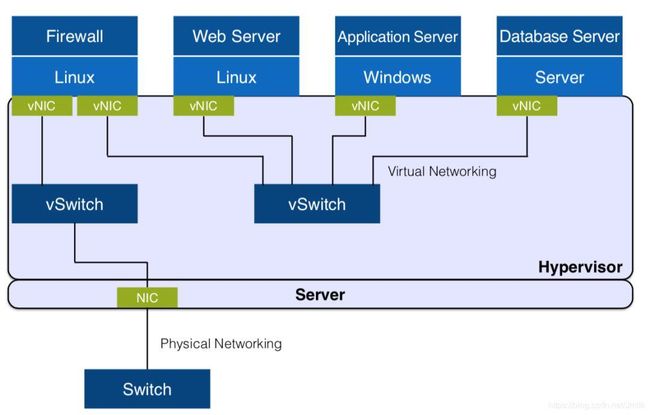
布式虚拟网络:
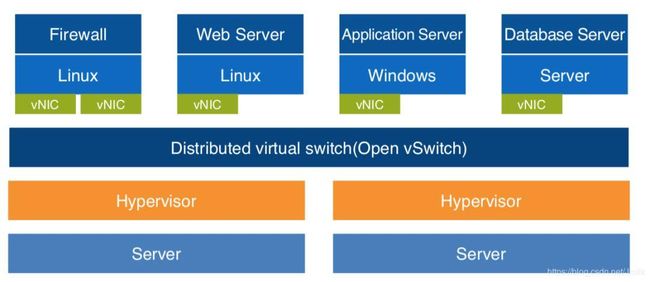
单一平面网络到混合平面网络的演进
单一平面租户共享网络:所有租户共享一个网络(IP 地址池),只能存在单一网络类型(VLAN 或 Flat)。
- 没有私有网络
- 没有租户隔离
- 没有三层路由

多平面租户共享网络:具有多个共享网络供租户选择。
- 没有私有网络
- 没有租户隔离
- 没有三层路由

混合平面(共享/私有)网络:共享网络和租户私有网络混合。
- 有私有网络
- 没有租户隔离
- 没有三层路由
NOTE:因为多租户之间还是依赖共享网络(e.g. 需要访问外部网络),没有做到完全的租户隔离。

基于运营商路由功能的多平面租户私有网络:每个租户拥有自己私有的网络,不同的网络之间通过运营商路由器(公共)来实现三层互通。
- 有私有网络
- 有租户隔离
- 共享三层路由
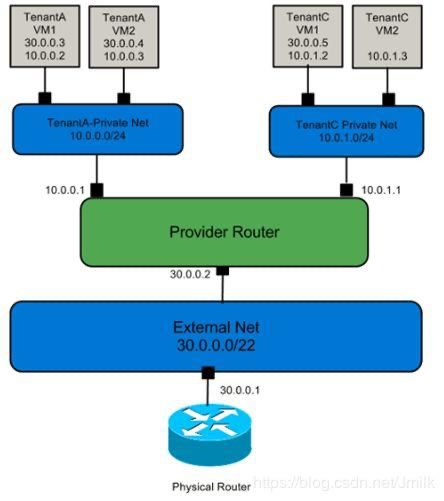
基于私有路由器实现的多平面租户私有多网络:每个租户可以拥有若干个私有网络及路由器。租户可以利用私有路由器实现私有网络间的三层互通。
- 有私有网络
- 有租户隔离
- 有三层路由

NEUTRON 简述
Neutron is an OpenStack project to provide “network connectivity as a service” between interface devices (e.g., vNICs) managed by other OpenStack services (e.g., nova). The OpenStack Networking service (neutron) provides an API that allows users to set up and define network connectivity and addressing in the cloud. The project code-name for Networking services is neutron. OpenStack Networking handles the creation and management of a virtual networking infrastructure, including networks, switches, subnets, and routers for devices managed by the OpenStack Compute service (nova). Advanced services such as firewalls or virtual private network (VPN) can also be used. — — 官方网站:https://docs.openstack.org/neutron/latest/
Neutron 是为 OpenStack 提供 Network Connectivity as s Service 的项目,当然 Neutron 也可以脱离 Keystone 体系作为一个独立的 SDN 中间件。
- 作为 OpenStack 组件:为 OpenStack 虚拟机、裸机、容器提供网络服务。
- 作为 SDN 中间件:北向提供统一抽象资源接口,南向对接异构 SDN 控制器。
之所以有前两个章节,是希望以此来引出 Neutron 所追求的目标 —— 云计算时代的分布式虚拟化网络与多租户隔离私有的多平面网络。
从软件实现的角度来看,对 Neutron 熟悉的开发者不难察觉:Neutron 团队肯定首先设计好 Core API Models(核心资源模型)然后再往下实现的。这也是很多 OpenStack 项目的实现风格,值得我们学习。在设计软件架构时,不要急于撸代码,而是首先思考清楚 「XXX as a Service」中 Service 的含义,即 “什么是服务、为谁服务、提供什么服务、如何提供”?Neutron 提供的网络即服务的精髓就在于租户只需关心服务,不必关心实现细节,而服务的内容就是资源类型(API)的定义。只有稳定、兼容、平滑过渡的 API 才能引发 APIs 经济(围绕开放式 API 的生态圈),让软件得以在残酷的开源市场中存活下来。
而且 Neutron 的设计初衷是纯粹的 “软件定义”,无需设计新的硬件,而是对现有硬件的协同,这是一个务实的设计思想,通过 Plugin-Driver 的方式来调用底层物理/虚拟网元功能,为上层服务提供支撑。这一特点使 Neutron 得以在业界收到广泛的关注。
NEUTRON 的网络实现模型
在了解 Neutron 网络实现模型的过程中,我们主要弄明白三个问题:
- Neutron 是怎么支持多类型网络的(e.g. VLAN、VxLAN)?
- 同一个租户网络内的跨计算节点虚拟机之间是怎么通信的?
- 虚拟机是怎么访问外网的?
Neutron 的网络实现模型概览:
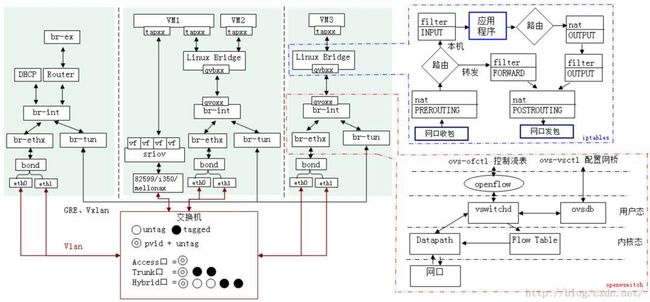
计算节点网络实现模型
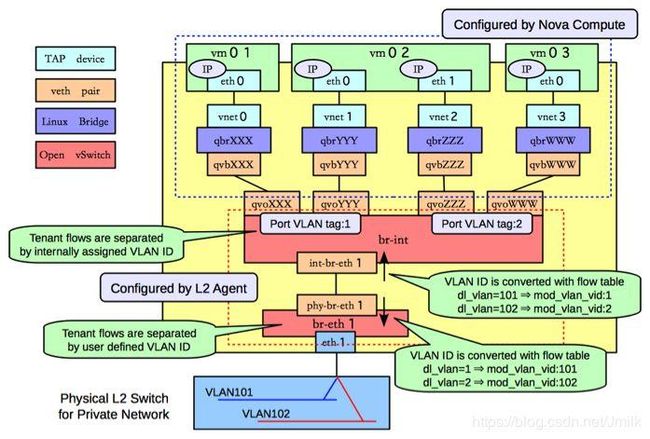
下面我们直接介绍计算机节点上的虚拟机流量是如果被送出计算节点的,并在过程中插入介绍相关的虚拟网络设备于工作机理。
Step 1. 流量经由虚拟机内核 TCP/IP Stack 交给虚拟网卡 vNIC 处理,vNIC 是一个 Tap 设备,它允许用户态程序(这里指 GuestOS,一个 qemu 进程)向内核 TCP/IP 协议栈注入数据。Tap 设备可以运行在 GuestOS 上,提供与物理 NIC 完全相同的功能。
Step 2. 虚拟机的 vNIC(Tap 设备)没有直连到 OvS Bridge 上,而是通过 Linux Bridge 中继到 OvS br-int(Integrated bridge,综合网桥)。为什么 vNIC 不直连 br-int?这是因为 OvS 在 v2.5 以前只有静态防火墙规则,并不支持有状态的防火墙规则。这些规则是 Neutron Security Group 的底层支撑,为虚拟机提供针对端口(vNIC)级别的安全防护,所以引入了 Linux Bridge 作为安全层,应用 iptables 对有状态的数据包进行过滤。其中 Linux Bridge qbr 是 quantum bridge 的缩写。还有一些其他原因:
- Openstack Neutron需要在宿主机上执行一定的安全策略;
- Hulk平台使用的ovs版本是2.3.1,该版本尚未完全支持安全策略的内核模块实施部分:netfilter模块;
- 增加一个中间层Linux bridge可以解决网络策略配置。
Step 3. Linux Bridge 与 OvS Bridge 之间通过 veth pair (虚拟网线)设备连接,“网线” 的一端命名为 qvb(quantum veth bridge)另一端命名为 qvo(quantum veth ovs)。veth pair 设备总是成对存在的,用于连接两个虚拟网络设备,模拟虚拟设备间的数据收发。veth pair 设备的工作原理是反转通讯数据的方向,需要发送的数据会被转换成需要收到的数据重新送入内核 TCP/IP 协议栈进行处理,最终重定向到目标设备(“网线” 的另一端)。
Step 4. OvS br-int 是一个综合网桥,作为计算节点本地(Local)虚拟交换设备,完成虚拟机流量在本地的处理 —— Tenant flows are separated by internally assigned VLAN ID.(Tenant 网络的 Local VLAN ID 由 内部分配)
- 虚拟机发出的流量在 br-int 打上 Local VLAN tag,传输到虚拟机的流量在 br-int 被去掉 Local VLAN tag。
- 本地虚拟机之间的 2 层流量直接在 br-int 转发,被同 VLAN tag 的端口接收。
Step 5. 从本地虚拟机传输到远端虚拟机(或网关)的流量由 OvS br-int 上的 int-br-eth1(ovs patch peer 设备)端口送到 OvS br-ethX 上。需要注意的是,br-ethX 并未是一成不变的:当网络类型为 Flat、VLAN 时,使用 br-ethX;当网络类型为 Tunnel(e.g. VxLAN、GRE)时,br-ethX 就会被 br-tun 替换。上图示例为 VLAN 网络。我们将 br-ethX、br-tun 统称为租户网络层网桥设备(TNB),以便于叙述。
NOTE: qbr-xxx 与 OvS br-int 之间使用 veth pair 设备相连,br-int 与 br-ethx/br-tun 之间使用 patch peer 设备相连。两种都是类似的虚拟 “网线”,区别在于前者是 Linux 虚拟网络设备,后者是 OvS 实现的虚拟网络设备。
NOTE: 如果租户网桥是 br-tun 而不是 br-ethX,那么在 br-tun 上会有 port:patch-int,br-int 上会有 port:patch-tun,通过 patch-int 和 patch-tun 实现租户网桥 br-tun 和本地网桥 br-int 之间的通信。
Step 6. 当虚拟机流量流经 OvS br-int 与 OvS br-ethX 之间时,需要进行一个至关重要且非常复杂的动作 —— 内外 VID 转换。这是一种 “分层兼容” 的设计理念,让我想起了:所有计算机问题都可以通过引入一个中间层来解决。而 Neutron 面对的这个问题就是 —— 支持多种租户网络类型(Flat、VLAN、VxLAN、GRE)。
Step 7. 最后虚拟机流量通过挂载到 TNB(br-ethX/br-tun)上的物理网卡 ethX 发出到物理网络。OvS br-int 与 OvS br-ethX 之间也是通过 veth pair 设备实现。
Step 8. 虚拟机的流量进入到物理网络之后,剩下的就是传统网络的那一套了。网络包被交换机或其他桥接设备转发到其他计算、网络节点(PS:这取决于具体的部署网络拓扑,一般虚拟机流量只会被同处 Internal Network 的计算节点)接收到。
内外 VID 转换
从网络层的角度看,计算节点的网络模型可分为:租户网络层、本地网络层。
其中本地网络层通过 VLAN ID 来划分 br-int 中处于不同网络的虚拟机(端口),本地网络仅支持 VLAN 类型;而租户网络层为了实现多类型混合平面的需求却要支持非隧道类型网络 Flat、VLAN(br-ethX)及隧道类型网络 VxLAN、GRE(br-tun)。显然,本地网络层和租户网络层之间必须存在一层转换。这就是所谓的 VID 转换。
VID 是一个逻辑概念,针对不同的租户网络类型也有不同类型的 “VID”。

需要注意的是 VID 的范围是由租户定义的 —— Tenant flows are separated by user defined VLAN ID.(租户网络的 VID 由 User Defined,此时示例为 VLAN 类型网络)。所谓 “User Defined” 就是用户通过 Neutron 配置文件 ml2_conf.ini 为各种网络类型配置的 range。e.g.
# /etc/neutron/plugins/ml2/ml2_conf.ini
[ml2_type_vlan]
network_vlan_ranges = public:3001:4000
[ml2_type_vxlan]
vni_ranges = 1:1000
[ml2_type_gre]
tunnel_id_ranges = 1:1000
再次强调,本地网络的 VLAN ID 是由内部代码逻辑算法分配的,而租户网络的 VID 才是由用户自定义配置的。
或许你会感到奇怪,为什么租户网络与本地网络同为 VLAN 类型的情况下还需要进行内外 VID 转换?解答这个问题只需要辩证思考一下:加入不进行内外 VID 转换会怎样?答案是会在混合 VLAN 和 VxLAN 类型租户网络的场景中出现内外 VID 冲突的情况。
假设网络1:租户网络 VLAN 的 VID 为 100,不做内外 VID 转换,那么本地网络 VLAN ID 也是 100。 网络2:租户网络 VxLAN 的 VID 为 1000,进行内外 VID 转换,本地网络 VLAN 100 也可能是 100。
这是因为 VxLAN 网络再进行内外 VID 转换的时候并不知道 VLAN 网络的 VID 是多少,只有当 VLAN 网络进行了内外 VID 转换之后才会知道,因为 VID 转换是有由 OvS Flow Table 记录并执行的 —— VLAN ID is converted with flow table。
所以 VLAN 类型网络也要进行内外 VID 转换是为了防止混合 VLAN 和 VxLAN 类型租户网络的场景中出现内外 VID 冲突的情况!
至此,我们就可以回到开篇的其中两个问题了。
- Neutron 是怎么支持多类型网络的?
- 同一个租户网络内的跨计算节点虚拟机之间是怎么通信的?
网络节点网络实现模型
网络节点所承载的最核心的功能就是解决虚拟机与外部网络(e.g. Internet)通信的问题,围绕这个问题我们设想一下在传统网络中是怎么实现的?
- 所有计算节点内的虚拟机,要访问 Internet,必须先经过网络节点,网络节点作为第一层网关。
- 网络节点会通过连接 DC 物理网络中的一个设备(e.g. 交换机,或者是路由器)到达 DC 的网关 。这个设备称为第二层网关。当然,网络节点也可以直接对接 DC 网关(如果 DC 网关可控的话),这时候,就不需要第二层网关了。
- DC 网关再连接到 Internet上。
可见,网络节点要处理的事情就是第一层网关处理的事情,西接所有计算节点的流量,东接物理网络(第二层)网关设备。为此,网络节点所需要的元素就是一个 L3 Router。需要注意的是,这里所提到的 L3 Router 并不是一个 vRouter(SDN 中的虚拟路由器),而是网络节点本身(一个可作为路由器的 Linux 服务器)。借助于 Linux 服务器本身的路由转发功能,网络节点得以成为了上文提到的:访问外部网络所需要通过的 第一层网关。
依旧从分层的角度来看,网络节点的网络实现模型可以分为 4 层:
- 租户网络层:对接所有(计算、控制、网络)节点,支持多种网络类型。
- 本地网络层:基于内外 VID 转换机制,通过 Local VLAN tag 来区分网络包所属的网络。
- 服务网络层:提供 L3 Router 和 DHCP 服务。
- 外部网络层:对接外部网络(e.g. Internet)。
网络节点出了提供 L3 Router 服务,同时也为每个有必要(用户手动开启)的租户网络提供 DHCP 服务。为了实现多租户网络资源隔离,应用了 Linux 提供的 Network Namesapce 技术。每创建一个 L3 Router 资源对象,就会添加一个与之对应的 qrouter-XXX namesapce;每为一个租户网络开启 DHCP 服务,就会添加一个与之对应的 qdhcp-XXX namesapce。
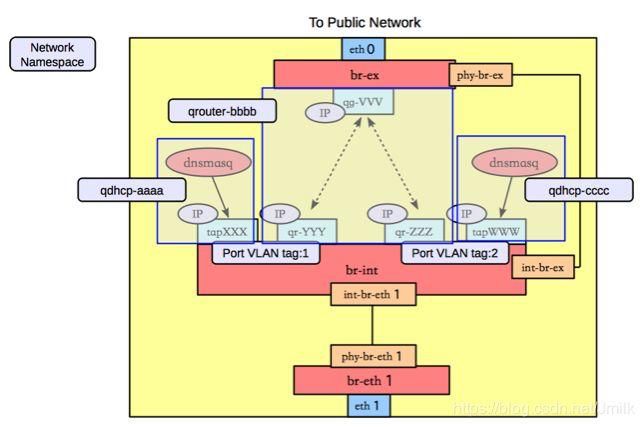
上图可见,DHCP 服务实际是由 dnsmasq 服务进程提供的,在 qdhcp-XXX namesapce 中会添加一个 DHCP 的端口(Tap 设备),这个 DHCP 端口连接到 br-int 上,具有与对应的租户网络相同的 Local VLAN tag(和租户网络 VID),以此实现为租户网络提供 DHCP 服务。
除此之外,还可以看见在 qrouter-XXX namesapce 中 br-int 和 br-ex 两个网桥设备通过 veth pair 设备 qr-XXX(quantum router) 和 qg-XXX(quantum gateway)连接到了一起。而且 qr-XXX 端口也具有租户网络对应的 Local VLAN tag。不同的租户网络通过不同的 Network Namesapce 实现了 Router 配置(路由表、iptables 规则)的隔离,启用 iptables 在 qrouter-XXX 中主要是提供 NAT 功能,支撑 Neutron 的 Floating IP 功能。
不同的租户具有不同的 qrouter-XXX 与 qdhcp-XXX 实例,所以不同租户间可以实现 IP 地址的复用。
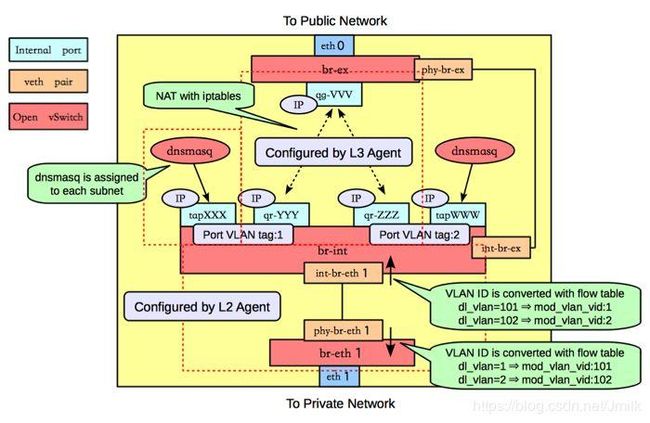
计算节点的网络模型章节中国我们介绍了虚拟机流量如何被送出计算节点,这里继续介绍虚拟机流量是如何被送出外部网络的:
Step 9. 物理网卡 ethX(OvS br-ethX/br-tun)从物理网络接收到从计算节点上虚拟机发出的外部网络访问流量,首先进行内外 VID 转换,然后通过 VETH Pair 设备传输到 OvS br-int。
NOTE: 针对每一个租户网络在租户网络层上的 VID 肯定的一致的,而在不同(计算、网络)节点上的 Local VLAN ID 却未必一样,但这并不会导致不同租户网络间的数据包混乱,因为这一切都在 Open vSwitch 流表的掌握之中,我们暂且先对这个问题有个印象。
Step 10. 在网络节点上 OvS br-int 连接了不同的 Network namesapce,qrouter-XXX 通过 qr-XXX 端口接收到租户内跨网段访问流量以及公网访问流量。
-
跨网段访问流量: qr-XXX 端口接收到流量后,内核 TCP/IP 协议栈根据 qrouter-XXX中的路由规则对跨网段访问流量进行路由、改写 MAC 地址并通过相应的 qr-YYY 接口向 OvS br-int传输数据包。实现不同网段之间的路由转发。
-
公网访问流量: qr-XXX 端口接收到流量后,内核 TCP/IP 协议栈根据 qrouter-XXX 中的 iptables NAT 规则对流量进行网络地址转换(Floating IP 的实现原理),之后再通过 qg-XXX 接口将数据包发送给 OvS br-ex。
Step 11. 最终由连接第二层网关并挂载到 br-ex 上的物理网卡 ethX 发出送至 Internet 路由器。
综上,“虚拟机是怎么访问外网的?” 这个问题解决了。
控制节点的网络实现模型
控制节点的网络实现模型就相对好理解很多了,因为控制节点不负责数据平面的问题,所以也没有实现具体的网络功能。我们需要关心的只是 neutron-server 这个服务进程。Neutron 没有显式(名为)的 neutron-api 服务进程,而是由 neutron-server 提供 Web Server 的服务。北向接收 REST API 请求,南向通过 RPC 协议转发各节点上的 Neutron Agent 服务进程,这就是 Neutron 在控制节点上的网络实现模型。
至此,我们介绍完了 Neutron 在分别计算、网络、控制节点上的网络实现模型,我们不妨回味一下这之间最重要的的设计思想 —— 分层。
让我们先抛开 OpenStack 和 Neutron,单纯的想象如何应用虚拟交换机实现跨主机间的虚拟机通信以及虚拟机访问外网的需求?答案其实很简单,如果应用 OvS,就会简单到只需要在每个节点上创建一个 Bridge(e.g. br-int)设备即可,无需 br-ex、br-ethX/br-tun、Linux Bridge 等等一大堆东西。e.g.
# Host1
ovs-vsctl add-br br-vxlan
# Host2
ovs-vsctl add-br br-vxlan
# Host1 上添加连接到 Host2 的 Tunnel Port
ovs-vsctl add-port br-vxlan tun0 -- set Interface tun0 type=vxlan options:remote_ip=<host2_ip>
# Host2 上添加连接到 Host1 的 Tunnel Port
ovs-vsctl add-port br-vxlan tun0 -- set Interface tun0 type=vxlan options:remote_ip=<host1_ip>
如果应用 Linux Bridge 的话,就会稍微复杂一些,正如我在《KVM + LinuxBridge 的网络虚拟化解决方案实践》所记录的一般,这里不再赘述。e.g.
但如果考虑到需要实现的是在「云平台上的多租户多平面网络」的话,那么事情就会变得相当复杂。一个有生命力的灵活的云平台,需要支持的网络类型实在是太多了,Neutron 至今仍在为之付出努力。在这样的条件下就急需设计出一个「上层抽象统一,下层异构兼容」的软件架构,而这种架构设计就是我们常说的 —— 分层架构设计。设计方案总是依赖于底层支撑选型,Neutron 网络实现模型的分层架构得益于 Open vSwitch(OpenFlow 交换机)的 Flow Table 定义功能。通过这个章节,希望大家能够对此有所感受。
原文链接:http://www.99cloud.net/10741.html%EF%BC%8F