Oracle数据库课堂笔记
Oracle数据库课堂笔记
(一)数据库基础
用户创建语句:
格式:create user username identified by password;
例:create user hejing identified by 123456;
用户修改语句:
格式(改密码):alter user username identified by password;
例:alter user hejing identified by 654321;
格式(锁定/解锁用户):alter user username ACCOUNT LOCK/UNLOCK;
例:alter user hejing ACCOUNT LOCK/UNLOCK;
9月2日
一、权限、
1、定义:使用系统的权利
分类:系统权限和对象权限。
**系统权限:**权限和系统操作有关。
例如:登录系统。
**对象权限:**权限和对象操作有关。
2、分配权限
(1)格式
GRANT privilege[, privilege…] TO user [, user…];
全是权限:create session(用户登录权限)/create table/create sequence(序列权限)/create view/create procedure等
二、角色
1、定义:使用系统的权利分类
权限分配过程:
(1)创建用户
(2)创建角色
(3)给角色分配权限
(4)给用户分配角色
角色创建格式:
create role 角色名;
例如:创建student角色
使用system用户登录
create role student;
给角色分配权限:
grant create session(连接数据库权限) to 角色; ——(可以同时分配多个权限,用逗号隔开)
给用户分配角色 :
grant 角色 to 用户; ——(to给多个用户,用逗号隔开)
系统权限(create table、create session等系统权限)
对象权限(select 、update)
1、对象权限:针对对象操作的权限。select等
2、对象权限的创建。

3、实践。

9月5日

分配一个数据表的一个列标给某个用户。

创建表空间
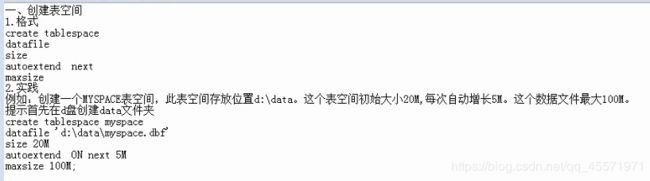
表空间属性
重命名表空间

修改表空间大小
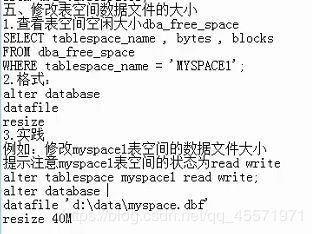
增加表空间数据文件

九月十一


 临时表空间 组 移动 删除 大文件
临时表空间 组 移动 删除 大文件
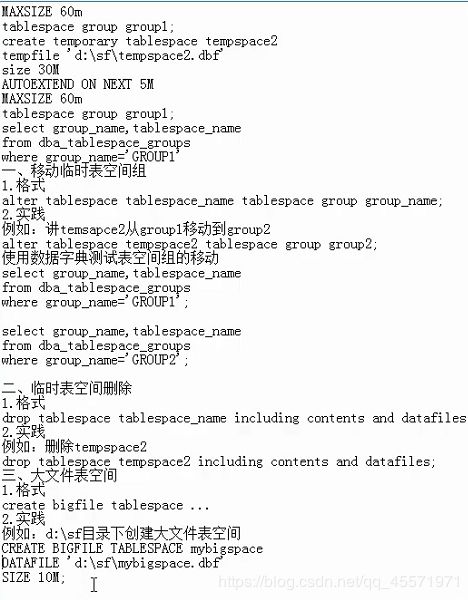
非标准数据块。


设置默认表空间

撤销表空间


9月23日
一,修改撤销表空间的保存时间
使用查询语句,查看撤销数据的保留时间
show parameter undo_retention;
1.格式
alter system set undo_retention=保留时间秒;
2.实践。
例如:修改撤销数据保留时间为1200秒;
alter system set undo_retention= 1200;
查看撤销数据保留时间点后的结果
show parameter undo_retention;
二、删除撤销表空间
1、格式
drop tablespace myundo including contents and datafiles;
2、实践
删除撤销表空间myundo
drop tablespace myundo including contents and datafiles;
三、数据表的创建
1、格式
create table [schema] table_name
(column datatype default expression)
schema 所用者信息
datatype 数据类型
default 指定数据类型
2、datadype 参阅课本 p125 表9-1
NUMBER (n,[m]) n代表数值的总长度, m表示保留的小数位数
例如:在数据表中需要保存像 98.02/7384.04这样的数据。
定义表结构
create table
(price number(20,2))
3、实践
例如创建一张数据表dept1,表中有三个列标题。分别为
deptno number(4),dname varchar2(20),loc varchar(20)
create table dept1(
deptno number(4),
dname varchar2(20),
loc varchar(20));
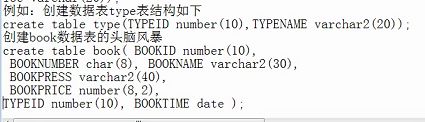

2019.9.25
登录 scott 密码 tiger
一、使用子查询实现数据表的创建
select empno,ename,sal,hiredate
from emp
where deptno=30;
二、基于子查询完成dept30数据表的创建
create table dept30
as
select empno,ename,sal,hiredate
from emp
where deptno=30;
二、数据表修改
1、
(1)在原有的数据表结构基础上添加新列标题
(2)在原有的数据表结构基础上修改列标题
2、实践
例如:在创建好的dept30数据表结构上添加新列标题 job varchar2(20)。
alter table dept30
add(job varchar2(20));
desc dept30;
例如:修改dept30数据表中ename字符串长度为20
alter table dept30
modify(ename varchar(20));
修改完毕以后,用 desc dept30 查看
三、删除数据表
drop table table_name;
实践:
例如:删除dept30数据表
第一步:使用数据字典删除当前用户中包含的数据表对象
select table_name
from user_tables;
第二步:删除
drop table dept30;
第三步:再次查询
select table_name
from user_tables;
四、修改数据表名
1、格式
rename 旧名字 to 新名字
2、实践
例如:将dept数据表明修改为deptment
先使用数据字典查看原表名
select table_name
from user_tables;
使用rename修改
rename dept to deptment;
五、数据表的截断
注意:使用truncate实现数据表中的记录全部删除,并且不能恢复
1、格式
truncate table table_name;
2、实践
例如:删除employee数据表中所有的记录,并且不让恢复
先查看内容
select ename
from employee;
截断
truncate table employee;
再次查看
select *
from employee;
2019.9.26
一、数据表添加注释
1、格式
comment on table table_name|column table.column is ‘注释内容’
2、实践
例如:给emp数据表添加注释,注释员工基本信息。
comment on table emp is ‘Employee Information’;
查看当前用户数据表的注释
select *
from USER_TAB_COMMENTS;
例如:给emp数据表中empno列标题添加注释,注释内容“Employee number”
comment on column emp.empno is ‘employee number’;
数据字典查看结果
select column_name,comments
from user_col_comments;
3、查看注释使用的数据字典
ALL_COL_COMMENTS:查看所有用户列标题的注释
USER_COL_COMMENTS:查看当前用户列标题的注释
ALL_TAB_COMMENTS:查看所有用户数据表的注释
USER_TAB_COMMENTS:查看当前用户数据表的注释
二、约束概念
1、功能分类
NOT NULL:非空约束
PRIMARY KEY:主键约束
FOREIGN KEY:外键约束
CHECK:条件约束
2、根据约束的定义位置分类
列一级
表一级
三、NOT NULL
1、功能:不允许填充空值
2、注意:它的定义格式只有列一级的约束
3、实践
例如:创建employee数据表,empno number(4),ename varchar(20)。
create table employee (empno number(4),ename varchar(20))
测试插入记录,查看是否能完成信息插入。
insert into employee values(1000,NULL);
完成上面列题以后,删除employee
drop table employee;
例如:创建employee数据表,empno number(4),ename varchar(20),给ename列标题
加入空值约束。
create table employee (employee number(4),ename varchar(20) not null);
测试插入记录,查看是否能完成信息的插入。
insert into employee values(1000,null)
四、UNIQUE
1、功能:同一列标题下的数据不可以有重复值,但可以有多个空值
2、实践
例如:创建deptment数据表(deptno number(4),dname varchar2(20)),让dname列带唯一约束使用表一级约束的定义方法。
create table deptment(deptno number(4),dname varchar2(20),)
2019.9.30
一、primary key
1、功能
2、格式
列一级
column [CONSTRAINT costrant_name] constraint_type,
表一级
column,…
[CONSTRAINT constraint_name] constraint_type
(column,…),
3、实践
例如:创建deptment, deptno number(2),dname varchar2(20)
deptno 为主键约束。
列一级
create table deptment(deptno number(2) primary key,dname varchar2(20));
drop table deptment;
表一级
create table deptment(deptno number(2),
dname varchar2(20),
constraint deptment_deptno_pk primary key(deptno));
插入测试数据
insert into deptment values(10,‘SALES’);
以下两条记录可否正常插入
insert into deptment values(10,‘MAKING’);
insert into deptment values(NULL,‘MAKING’);
二、FOREIGN KEY外键约束
1、功能:两张数据表通过一个相同的列标题建立关联,这是主表中的主键,那么他就是子表中的外键约束
2、特点:(1)插入记录的时候,主表中的记录约束子表中的记录
(2)删除记录的时候,子表中的记录约束主表中记录的删除
3、格式
列一级
column [CONSTRAINT costrant_name] constraint_type,
表一级
column,…
[CONSTRAINT constraint_name] constraint_type
(column,…),
4、实践
例如:创建employee数据表,ename varchar2(20),deptno number(2)
定义deptno为外键约束,和deptment数据表建立关联。
create table employee
(ename varchar(20),
deptno number(2),
constraint employee_deptno_FK foreign key(deptno)
references deptment(deptno));
尝试插入测试数据
insert into employee values(‘MAIWEI’,10);
再次尝试插入测试数据查看是否正常插入
insert into employee values(‘WANGLI’,20);
尝试在deptment数据表中删除部门编号为10的记录,查看是否能正常的删除
delete deptment where deptno=10;
2019.10.9
一、FOREIGN KEY
1、ON DELETE CASCADB:如果删除父表中的记录则允许级联删除子表中相关联的记录
2、实践
例如:
创建主表:
create table deptment (deptno number(4),dname varchar2(20),constraint
deptment_deptno_pk primary key(deptno));
创建子表:
create table employee(empno number(4),ename varchar2(20),deptno number
(4),constraint employee_deptno_fk foreign key(deptno) references deptment
(deptno) on delete cascade);
测试:
insert into deptment values(10,‘SALES’);
insert into deptment values(20,‘MARKING’);
在子表中插入我们的数据
insert into employee values(1001,‘ZHANGSAN’,10);
insert into employee values(1001,‘LISI’,10);
在主表中删除10部门的记录
delete deptment where deptno = 10;
二、check约束
1、功能:定义每条记录都必须满足的条件(取值范围)
2、实践
例如:创建employee数据表,要求sal列表题将来数据的取值范围(0~20000)。
drop table employee;
create table employee(empno number(4),ename varchar2(20),sal number(10),constraint employee_sal_ck check(sal between 0 and 20000));
测试:
insert into employee values (1000,‘WANGLING’,-20);
insert into employee values (1000,‘WANGLING’,30330305205);
insert into employee values (1000,‘WANGLING’,15000);
三、数据约束
1、ALTER TABLE table
ADD [CONSTRAINT constraint] type (column);
2、注意:对于not null 约束的添加,使用的关键字是 MODIFY子句
3、实践
例如:修改employee数据表,在表中添加empno主键约束。
alert table employee add constraint emp_empno_pk primary key(empno);
测试:
insert into employee values (1000,‘WANGWU’,3000);
insert into employee values (NULL,‘WANGWU’,3000);
四、删除约束
alert table employee drop constraint emp_empno_pk;
测试:
insert into employee values (1000,‘WANGWU’,3000);
insert into employee values (NULL,‘WANGWU’,3000);
**
课本第八章
**
一、数据的插入
1、格式
注意:一次只能插入一条记录
2、实践
例如:在dept数据表中完成一条部门信息的插入 50,‘MARKING’,‘SHANGHAI’
insert into dept values ( 50,‘MARKING’,‘SHANGHAI’);
注意:插入的数据时如果碰到字符型、日期型数据、一定要使用单引号将他们引起来
3、空值的插入
显示输入法:NULL
隐试输入法:不让null出现
例如:在dept数据表中添加60,SALES办公地点未定
显示空值插入:insert into dept values(60,‘SALES’,null);
例如:在dept数据表中添加70,COUNTING办公地点未定
隐试空值插入:insert into dept(deptno,dname) values(70,‘COUNTING’);
4、特殊值的插入
比如:函数等
例如:在emp数据表中插入一条员工信息 ‘1017’ ‘zhangsan’,入职日期是当前的系统时间
注意:在此案例中,当前系统时间函数是(oracle中) SYSDATE
select sysdate from dual;
insert into emp(empno,ename,hiredate) values(‘1017’,‘zhangsan’,sysdate);
5、应用替代变量实现输入插入
(1)替代变量
假设一个查询需求:SMITH/SCOTT/JONES等等
作用:类似于变量。这种变量出现查询语句或DML中,通过对它不断的付新值可以实现新记录的查询
和记录的增删改。
(2)格式: ‘&’和‘&&’
&:每次使用,都可以接收一个新的赋值
&&:一次赋值,永久有效
(3)实践
例如:使用替代变量在现有部信息表中新记录的添加
insert into dept values(&dept_no,’&d_name’,’&d_loc’);
关于重复运行:/(运行当前缓冲区中的语句)
6、使用子查询完成记录的插入
(1)格式
insert into table [column,(column)] subquwry(子查询)
(2)实践
例如:使用子查询实现在deptment数据表中记录的插入。
第一步:创建一张表结构完全相同的数据表
create table deptment
as
select *
from dept
where deptno=0;
第二步:使用子查询完成记录的插入
insert into deptment
select *
from dept;
2019-10-21
一、update
1.格式
update table
set column=value
where condition
注意:一条或者多条记录的数据修改
例如:讲dept数据表中SALES修改为MARKING
2.使用查询实现数据的修改
(1)格式
update table
set (column1,columnn)=(subquery)
where condition
(2)实践
例如:使用7499员工的job,sal修改7698员工的job和sal。
查询7698员工的job和sal
select job,sal
from emp
where empno=7698;
查询7499员工的job和sal
select job,sal
from emp
where empno=7499;
update emp
set (job,sal)=(
select job,sal
from emp
where empno=7499)
where empno=7698;
例如:使用SMITH员工的MGR,Job 和hiredate 修改ALLEN员工的Mgr,job和hiredate。
查询ALLEN员工的MGR,Job 和hiredate
select mgr,job,hiredate
from emp
where ename=‘ALLEN’;
update emp
set (MGR,job,hiredate)=(
select MGR,job,hiredate
from emp
where ename=‘SMITH’)
where ename=‘ALLEN’;
二、delete
1.格式
delete table
where condition
注意:一条或者多条语句
2.实践
例如:删除ALLEN员工的信息
delete emp
where ename = ‘ALLEN’;
3.truncate语句
(1)功能:数据表的截断。它完成数据删除操作,这组数据删除以后不能再恢复。
(2)格式
truncate table 表名称
(3)实践
例如:删除emp数据表中的全部数据并且不能恢复
truncate table emp;
2019.10.23
控制实物
一、事务
1、概念:由一组SQL做成的操作过程
2、事务的特性:原子性(一个事物是不可以继续分割原子的工作单元)、
隔离性(多个并发事务处理,一个个进行处理彼此之间不影响处理结果)、
一致性(数据的一致性)、
持久性(完成一组事务处理,所对数据库的产生是永久性的)
二、事务提交(commit)
1、功能(提交事务)
2、格式:commit
3、实践
例如:在dept数据表中插入一条记录,50,MARKING,SHNAGHAI。插入完毕以后退出当前命
令,执行事务提交。
insert into dept values(‘50’,‘MARKING’,‘SHANGHAI’);
commit;
三、保留点(savepoint)
1、功能:设置保留点
2、savepoint[savepoint_name]
四、回滚(rollback)
1、功能:撤销事务操作
2、rollback[to savepoint_name]

commit;
update dept set loc =‘A’
where loc=‘NEW YOER’;
savepoint a;
UPDATE DEPT SET loc=‘B’
where loc=‘DALLAS’;
savepoint b;
rollback to savepoint a;
commit;
2019.10.28
一、临时表的功能
1、临时表的概念
用户做一个查询出几百几千条数据,我们可以把数据放在内存中。
当多用户这样做,内存空间不足,这是我们就要把数据放在磁盘上。
对于Oracle就提供了一种临时表用于存放这些数据。
二、临时表主要有如下特点
1、临时表只有在用户表中添加数据时,Oracle才会为其分配存储空间。
2、为临时表分配的空间来自临时表空间
3、当用户当前的事务结束或者会话终止、临时表占用的存储空间会被释放,存储的数据也随之丢失。
4、当用户在临时表上建立索引、视图和触发器等
三、临时表分类
事务级别临时表和会话级别临时表
四、事务级别临时表的创建
1、特点:存放一组事务处理过程中的临时数据。当前事务完成时候,数据表中的数据立即被删除。
2、格式:
create global temporary table 临时表名
(column datatype 约束)on conmit delete rows
3、实践
例如:创建temp_emp数据表,表中有empno number(4)不为空主键约束,ename varchar2(20),sal number(7,2).
create global temporary table temp_emp
(empno number(4) not null primary key,ename varchar2(20),
sal number(7,2))on commit delete rows;
向此表中添加数据
insert into temp_emp values(1000,‘xueweiqi’,1600);
使用查询语句浏览记录是否插入成功
select* from temp_emp;
执行提交命令
commit;
使用查询语句浏览记录是否插入成功
select * from temp_emp;
结论,通过以上操作。可得出事务级别临时表中的数据会随着一个事务的结束而自动删除。
五、会话级别临时表的创建
1、特点:存放一组会话中的临时数据。当前会话结束时,数据立刻被删除。
2、格式
3、实践:
例如:创建会话级别临时表temp_dept(deptno number(2), dname varcher2(20), loc varchar2(20))
deptno有主键约束
create global temporary table temp_dept(
deptno number(2),dname varchar2(20),
loc varchar2(20),
constraint temp_dept_deptno primary key(deptno))
on commit preserve rows;
insert into temp_dept values(60,‘MARKING’,‘SHANGHAI’);
使用查询语句浏览记录是否插入成功
select * from temp_dept;
执行提交命令
commit;
使用查询语句浏览记录是否插入成功
select * from temp_dept;
2019.10.30
一、外部表
1、功能:引用在数据库以外的文件系统中存储的数据的只读表,也就是说,
外部表所要读取的数据存储在Oracle数据库外部的文件中,并且只能读取这些数据,
不能进行数据的写入
2、格式
create table table_name
(column datatype) RGANIZATION
EXTERNALA
(type ORACLE_LOADER
DEFAULT DIRECTORY 目录对象名
ACCESS PARSMETERS (LOCATION 数据文件名
FIELDS TERMINATED BY 分隔符))
TYPE:用来指定访问外部表数据文件时所使用的访问驱动程序,
该程序可以将数据从它们最初的格式转换为可以向服务器提供的格式。
DEFAULT DIRECTORY:用来指定所使用的目录对象,
该目录对象指向外部数据文件所在目录。
LOATION:用来源数据文件。
ACCESS PARAMETERS:用来设置访问驱动程序进行数据格式转换时的参数。
FIELDS TERMINATED BY:用来指定字段之间的分隔符。
3、实践
通过Oracle工具读取磁盘d:\external下的card.txt文件中的数据。
操作步骤:
1、在磁盘上建立新文件夹external,创建card.txt,添加数据
2、建立目录对象external_card,指向d:\external
格式:
create directory 目录对象名 as 路径
create directory external_card as ‘d:\external’;
3、创建e_card外部表
create table e_card(
cardid number(20),
cardnumber varchar2(20),
studentid number(20))
ORGANIZATION EXTERNAL(
TYPE ORACLE_LOADER
DEFAULT DIRECTORY external_card
ACCESS PARAMETERS(
FIELDS TERMINATED BY ‘,’)
LOCATION(‘card.txt’));
4、查询e_card表中是否能够读取磁盘中文件的数据。
select * from e_card;
2019.11.4
一、reject limit 子句
1、导入错误场景
读取外部数据错误场景
(1)在磁盘中建立目录,并放入数据文件
(2)在Oracle中创建目录对象
create directory external_card as ‘e:\external’;
(3)创建外部表
create table e_card(
cardid number(20),
cardnumber NUMBER,
studentid number(20))
ORGANIZATION EXTERNAL (
TYPE ORACLE_LOADER
DEFAULT DIRECTORY external_card
ACCESS PARAMETERS(
FIELDS TERNINATED BY ‘,’)
LOCATION(‘card.txt’))
(4)测试数据导入
select * from e_card;
使用reject limit子句去结束上述错误
2、功能:在错误发生时,通过reject limit子句实现拒绝错误限制。
3、格式
create table (…)reject limit子句实现拒绝错误限制。
4.实践
例如:通过加入reject limit子句解决上述错误。
drop table e_card;
create table e_card(
cardid number(20),
cardnumber NUMBER,
studentid number(20))
ORGANIZATION EXTERNAL (
TYPE ORACLE_LOADER
DEFAULT DIRECTORY external_card
ACCESS PARAMETERS(
FIELDS TERNINATED BY ‘,’)
LOCATION(‘card.txt’))reject limit UNLIMITED;
测试e_card数据表
select * from e_card;



一、select查询语句
1、日期的正确表达方式
例如:1981-12-2
表示为:‘2-12月-81’
select ename,hiredate
from emp
where hiredate=‘2-12月-81’;
2、查询字符串的时候要大写
select ename,hiredate
from emp
where ename=‘WARD’; ------大写
3、进行计算的时候一定要注意参与计算的值是不是空值
注意:空值既不是0也不是空格,空值参与的所有运算都是空值。
利用nvl()函数将空值转换为具有实际意义的数值
nvl(参数1,参数2)
参数1:包含空值的列标题或者空值
参数2:转换后的数值。例如:0,n,‘WARD’,'18-4月-19’等
select ename,(sal+nvl(comm,0))*12
from emp;
修改查询结果的列标题
例如将上述结果改为salary
格式1:通过空格链接原列标题和新列标题
格式2:通过as链接原列标题和新列标题
select ename,(sal+nvl(comm,0)) * 12 salary
from emp;
select ename,(sal+nvl(comm,0)) * 12 as salary
from emp;
注意:如果新生成的列标题,包含空格或者大小写的混用,那么需要使用双引号将新生成的列标题扣起来
select ename,(sal+nvl(comm,0)) * 12 as “Annaul salary” from emp;
4、在查询结果之间加入原意字符
连接符||:可以将列标题链接输出
加入原意字符用单引号括起
select ename || ’ is a ’ || job
from emp;
2019.11.11
一、编辑命令
1.list
(1)功能:将缓冲区中的语句列出
(2)格式:
list:将缓冲去中的语句全部列出
list n:将缓冲区中第n行的数据列出
list m n:将缓冲区中从m行到n行的数据列出
(3) 实践:
例如:在缓冲区中任意写一些语句,测试list的应用。
2.append
(1)功能:在文本的尾部实现新文本内容的追加
(2)格式:append text
text:需要添加的新内容
(3)实践
例如:查询员工姓名和sal,语句如下
select ename
from emp;
修订上述错误语句步骤
第一步:使用List
list 1;
第二步:使用append
sppend,sal
第三步:再次使用list
第四步:使用 run 或者 / 运行缓冲区的语句
3.change
(1)功能:修改错误和删除语句
(2)格式
change /old/new
change /text
(3) 实践
例如:输入以下错误语句,并用change修改
select ename,s
from emp;
第一步:使用List
list 1;
第二步:使用change修改
change /,s/,sal
第三步:再次使用list
第四步:使用 run 或者 / 运行缓冲区的语句
4.del
二、文件命令
1.save
(1)功能:将缓冲区内容保存到文件中去
(3)实践:
例如:在d:\file\try.txt,缓冲区中的语句
第一步在缓冲区中写入语句
第二步使用save命令,实现文件的保存
save d:\file\try.txt
2019.11.13
一、save
1.savefilename[crate][replace][append]
2.实践
例如:将缓冲区中的语句保存到d:\file\try.txt
第一步在缓冲区中加入语句
select ename,hiredate
from emp;
第二步输入save命令
save d:\file\try.txt
例如:再在缓冲区中加入语句,替换d:\file\try.txt文件中的内容
第一步在缓冲区中加入语句
select ename,sal
from emp;
第二步输入save命令
save d:\file\try.txt replace
例如:再在缓冲区中加入语句,并追加到d:\file\try.txt文件中的内容
第一步在缓冲区中加入语句
select ename,comm
from emp;
第二步输入save命令
save d:\file\try.txt append;
二、get命令
1.功能:使用GET命令读取文件内容到缓冲区
2.格式GET [file] file_name [list| nolist]
3.实践
例如:将d:\file\try.txt文件中的内容读取到缓冲区中并显示
get d:\file\try.txt;
例如:将d:\file\try.txt文件中的内容读取到缓冲区中并不显示
get d:\file\try.txt nolist;
4.edit
1.功能:编辑缓冲区内容或者文件内容
2.格式
edit filename
3.实践
例如:将d:\file\try.txt文件已编辑的模式打开
edit d:\file\try.txt;
四、start
1.功能:运行文件中的内容
2.格式
start filename
或者
@filename
3.实践
例如:运行d:\file\try.txt中的内容
start d:\file\try.txt
或者
@d:\file\try.txt
五、spool(脱机文件生成命令)
1、功能
将缓冲区中的语句和运行结果放入到文件中
3、实践
例如:将缓冲区中的语句和运行结果放入到d:\file\test.txt文件中。
第一步:启动spool命令
spool d:\file\test.txt;
第二步:在缓冲区内放入内容
select ename,sal
from emp;
select ename,hiredate
from emp;
第三步:关闭spool命令
spool off;
六、分区表
应该场景:

2019.11.18
一、使用HASH关键词创建散列分区表
HASH算法(数据结构)
1、格式
PARTITION BY HASH
2、实践
例如:
在散列分区表part_book2,使用PARTITION BY HASH字句,根据bid列,进行散列分区。
创建表空间
CREATE TABLESPACE mytemp1
dataFILE ‘d:\data\mytemp1.dbf’
SIZE 10M
AUTOEXTEND ON NEXT 2M MAXSIZE 20M;
CREATE TABLESPACE mytemp2
dataFILE ‘d:\data\mytemp2.dbf’
SIZE 10M
AUTOEXTEND ON NEXT 2M MAXSIZE 20M;
CREATE TABLESPACE mytemp3
dataFILE ‘d:\data\mytemp3.dbf’
SIZE 10M
AUTOEXTEND ON NEXT 2M MAXSIZE 20M;
创建数据表
create table part_book2
(Bid number(4),
bookname varchar2(30),
bookprice number(4,2),
booktime date)partition by hash(bid)
(partition part1 tablespace mytemp1,
partition part2 tablespace mytemp2);
插入测试数据
insert into part_book2 values(1,‘Oracle’,‘99’,‘17-7月-09’);
insert into part_book2 values(2,‘HIVE’,‘87’,‘17-7月-09’);
查看分区表数据填充数据
select * from part_book2;
select * from part_book2 partition(part1);
select * from part_book2 partition(part2);
二、使用list关键字创建列表分区
1、格式
PARTITION BY LIST(分区一句列标题)
2、实践
例如:根据图书出版社存放数据,比如清华大学出版社放入分区一中,
教育出版社放入到分区二中。
create table part_book3
(Bid number(4),
bookname varchar2(30),
bookpress varchar2(30),
booktime date)partition by list(bookpress)
(partition part1 values(‘清华大学出版社’)tablespace mytemp1,
partition part2 values(‘教育出版社’)tablespace mytemp2);
insert into part_book3 values(1,‘Oracle’,‘清华大学出版社’,‘19-7月-2017’);
insert into part_book3 values(2,‘Struts’,‘清华大学出版社’,‘29-8月-2018’);
insert into part_book3 values(3,‘SHH’,‘教育出版社’,‘25-10月-2017’);
select * from part_book3;
select * from part_book3 partition(part1);
select * from part_book3 partition(part2);
三、创建组合范围散列分区表
1、格式
PARTITION BY range(分区依据列标题)
subpartition by hash(PARTITION BY LIST(分区一句列标题))
subpartitions 2 store in(表空间1,表空间2)(
Partition part1 values less than(),
Partition part2 values less than(),
Partition part3 values less than(maxvalue));
2、实践
例如:创建part_book4组合范围散列分区表
创建语句如下:
create table part_book4(
bid number(4),
bookname varchar2(30),
bookspress varchar2(30),
booktime date)
partition by range(booktime)
subpartition by hash(bid)
subpartitions 2 store in (mytemp1,mytemp2)(
partition part1 values less than (‘01-1月-2018’),
partition part2 values less than (‘01-1月-2019’),
partition part3 values less than (maxvalue));
插入测试数据
insert into part_book4 values(1,‘Oracle’,‘人民邮电出版社’,‘17-7月-19’);
insert into part_book4 values(2,‘MySQL’,‘清华大学出版社’,‘17-2月-18’);
insert into part_book4 values(3,‘Python’,‘清华大学出版社’,‘17-2月-17’);
查询语句
select * from part_book4;
select * from part_book4 partition(part1);
select * from part_book4 partition(part2);
select * from part_book4 partition(part3);
2019.11.20
一、创建组合范围列表分区表
1、场景
组合范围列表分区表,就是将范围分区表和列表分区表结合使用。这种形式首先使用范围值进行分区,然后使用列表进行分区。
2、格式
create table tabe_name(
column1 datatype,
column2 datatype)
partition by range(column)
subpartition by list (column)
(partition partn values less than(value)
subpartition partn_n values(‘value’) tablespace tablespace_name))
3、实践
例如:创建一个夬表范围列表表空间part_book5,根据booktime列进行范围分区,
根据bookpress列进行列表分区。booktime列进行范围分区条件:2018-1月-1、
201-1月-1。根据bookpress列行列表分区条件:‘清华大学出版社’‘教育出版社’
创建表空间
CREATE TABLESPACE mytemp1
dataFILE ‘d:\data\mytemp1.dbf’
SIZE 10M
AUTOEXTEND ON NEXT 2M MAXSIZE 20M;
CREATE TABLESPACE mytemp2
dataFILE ‘d:\data\mytemp2.dbf’
SIZE 10M
AUTOEXTEND ON NEXT 2M MAXSIZE 20M;
CREATE TABLESPACE mytemp3
dataFILE ‘d:\data\mytemp3.dbf’
SIZE 10M
AUTOEXTEND ON NEXT 2M MAXSIZE 20M;
创建分区表
create table part_book5(
bid number(4),
bookname varchar2(20),
bookpress varchar2(30),
booktime date)
partition by range(booktime)
subpartition by list(bookpress)(
partition part1 values less than (‘01-1月-2017’)(
subpartition part1_1 values (‘清华大学出版社’) tablespace mytemp1,
subpartition part1_2 values (‘教育出版社’) tablespace mytemp1),
partition part2 values less than (‘01-1月-2018’)(
subpartition part2_1 values (‘清华大学出版社’) tablespace mytemp2,
subpartition part2_2 values (‘教育出版社’) tablespace mytemp2),
partition part3 values less than (‘01-1月-2019’)(
subpartition part3_1 values (‘清华大学出版社’) tablespace mytemp3,
subpartition part3_2 values (‘教育出版社’) tablespace mytemp3));
插入测试数据
insert into part_book5 values(1,‘Oracle’,‘清华大学出版社’,‘02-2月-2016’);
insert into part_book5 values(2,‘MySQL’,‘清华大学出版社’,‘02-2月-2017’);
insert into part_book5 values(3,‘SHH’,‘教育出版社’,‘02-2月-2017’);
insert into part_book5 values(4,‘大数据’,‘清华大学出版社’,‘02-2月-2018’);
查询
column bookname format a15
column bookpress format a15
select * from part_book5;
select * from part_book5 partition(part1);
select * from part_book5 subpartition(part1_1);
二、增加分区
1、增加分区适用于所有的分区形式
格式
ALERT TABLE table name ADD PARTITION …
2、在增加分区的时候:注意两点
(1)在最后一个分区增加分区、分区值必须大于当前所有分区的值
(2)如果当前存在MAXVALUE或DEFAULT值的分区,那么在增加分区时会出现错误。这种情况只能采用分割分区的方法,具体来说就是制定SPLIT PARTITION字句。
3、为范围分区增加分区
方法一:在最后一个分区增加分区
方法二:在分区中间或者开始处增加分区
4、实践
例如:为part_book增加一个分区,由创建该表时指定了MAXVALUE值,所以需要使
用ALTER TABLE table_name SPLIT PARTITION语句,将part3分区分隔成两个分区。
part_book数据表的创建:
create table part_book(
bid number(4),
bookname varchar2(30),
bookprice number(4,2),
booktime date)
partition by range(booktime)
(partition part1 values less than(‘01-1月-2018’) tablespace mytemp1,
partition part2 values less than(‘01-1月-2019’) tablespace mytemp2,
partition part3 values less than(MAXVALUE) tablespace mytemp3);
添加分区语句
alter table part_book split partition part3 at(‘01-1月-2020’)
into(partition part3 tablespace mytemp1,
partition part4 tablespace mytemp2);
insert into part_book values(1,‘oracle’,39,‘10-1月-2017’);
insert into part_book values(2,‘MySQL’,29,‘10-1月-2018’);
insert into part_book values(3,‘Java’,69,‘10-1月-2019’);
insert into part_book values(4,‘Python’,69,‘10-1月-2020’);
column bookname format a15
select * from part_book;
select * from part_book partition(part1);
select * from part_book partition(part2);
select * from part_book partition(part3);
select * from part_book partition(part4);
例如:如果创建的分区表中没有指定的MAXVALUE值,那么在添加分区时,需要使用ADD
PATITION字句。下面创建一个范围分区表rang_book,根据booktime列指定数据的3个分区
,如下:
1、创建不带MAXVALUE关键词的分区表
create table range_book(bid number(4),
bookname varchar2(30),
booktime date)
partition by range(booktime)
(partition part1 values less than(‘01-1月-2018’) tablespace mytemp1,
partition part2 values less than(‘01-1月-2019’) tablespace mytemp2,
partition part3 values less than(‘01-1月-2020’) tablespace mytemp3);
2、使用ALTER TABLE table_name ADD PARTITION 语句,为range_book表添加一个分区
part4,指定分区值为’01-1月-2021’
alter table range_book add
partition part4 values less than(‘01-1月-2021’);
3、插入测试数据
insert into range_book values(1,‘oracle’,‘10-1月-2017’);
insert into range_book values(2,‘MySQL’,‘10-1月-2018’);
insert into range_book values(3,‘Java’,‘10-1月-2019’);
insert into range_book values(4,‘Python’,‘10-1月-2020’);
4、查询
select * from range_book;
select * from range_book partition(part1);
select * from range_book partition(part2);
select * from range_book partition(part3);
select * from range_book partition(part4);
例如:为range_book表在开始处增加分区。
alter table range_book
split partition part1 at(‘01-1月-2017’) into (partition part5,partition part6);
插入测试数据
insert into range_book values (5,‘hadoop’,‘10-1月-2016’);
查看插入结果
select * from range_book partition(part5);
小总结:范围分区表增加分区:maxvalues(split partition)。没有maxvalue,在最后添加
分区(add partition)
2019-11-21
二、给散列分区表添加分区(hash)
1、格式
alter table table_name add partition partition_name tablespace_name;
2、实践
例如:给之前part_book2创建新分区。
create table part_book2
(Bid number(4),
bookname varchar2(30),
bookprice number(4,2),
booktime date)
partition by hash(bid)
(partition part1 tablespace mytemp1,
partition part2 tablespace mytemp2);
修改语句
alter table part_book2
add partition part3 tablespace mytemp1;
插入测试数据:
insert into part_book2 values(1,‘oracle’,‘99’,‘17-1月-09’);
insert into part_book2 values(2,‘java’,‘87’,‘17-7月-09’);
insert into part_book2 values(3,‘mysql’,‘98’,‘17-8月-10’);
查看表中数据
select * from part_book2;
select * from part_book2 partition(part1);
select * from part_book2 partition(part2);
select * from part_book2 partition(part3);
三、给散列分区表添加分区(list)range区分
alter table table_name add partition part_name values(values) tablespace(tablespace_name);
2、实践
例如:给part_book3添加新分区。
创建part_book3
create table part_book3
(Bid number(4),
bookname varchar2(30),
bookpress varchar2(30),
booktime date)
partition by list(bookpress)
(partition part1 values(‘清华大学出版社’)tablespace mytemp1,
partition part2 values(‘教育出版社’)tablespace mytemp2);
增加新分区
alter table part_book3 add partition part3 values(default) tablespace mytemp3;
insert into part_book3 values(1,‘Oracle’,‘清华大学出版社’,‘19-7月-2017’);
insert into part_book3 values(2,‘Struts’,‘清华大学出版社’,‘29-8月-2018’);
insert into part_book3 values(3,‘SHH’,‘教育出版社’,‘25-10月-2017’);
commit
select * from part_book3;
select * from part_book3 partition(part1);
select * from part_book3 partition(part2);
select * from part_book3 partition(part3);
2019.11.27
一、合并和删除分区
1.合并
(1)格式
ALTER TABLE … MERGE PARTITION 语句
(2)实践
例如:将range_book分区表中part5和part6分区合并到一起
创建表空间
CREATE TABLESPACE mytemp1
dataFILE ’
d:\data\mytemp1.dbf’
SIZE 10M
AUTOEXTEND ON NEXT 2M MAXSIZE 20M;
CREATE TABLESPACE mytemp2
dataFILE ‘d:\data\mytemp2.dbf’
SIZE 10M
AUTOEXTEND ON NEXT 2M MAXSIZE 20M;
CREATE TABLESPACE mytemp3
dataFILE ‘d:\data\mytemp3.dbf’
SIZE 10M
AUTOEXTEND ON NEXT 2M MAXSIZE 20M;
创建数据表
create table range_book
(bid number(4),
bookname varchar2(30),
booktime date)
partition by range(booktime)
(partition part1 values less than(‘01-1月-2018’)
tablespace mytemp1,
partition part2 values less than(‘01-1月-2019’)
tablespace mytemp2,
partition part3 values less than(‘01-1月-2020’)
tablespace mytemp3);
2、使用ALTER TABLE table_name ADD PARTITION 语句,为range_book表添加一个分区
part4,指定分区值为’01-1月-2021’
alter table range_book add
partition part4 values less than(‘01-1月-2021’);
例如:为range_book表在开始处增加分区。
alter table range_book
split partition part1 at(‘01-1月-2017’) into (partition
part5,partition part6);
表空间的合并
ALTER TABLE range_book
MERGE PARTITIONS part5,part6 INTO PARTITION part1;
2.删除分区
(1)格式
删除分区,需要使用ALERT TABLE … DROP PARTITION 语句
(2)实践
例如:删除范围分区表range_book中的part1分区,如下:
alter table range_book drop partition part1;
课本第三章
二、单行函LOWER和UPPER
(1)功能:大小写转换函数
(2)格式:
LOWER(参数1)
参数1:原意字符串或者是字符串数据类型列标题
UPPER(参数1)
参数1:原意字符串或者是字符串数据类型列标题
(3)实践
例如:将‘ABC’转换为小写。
select lower (‘ABC’)
from dual;
例如:将emp数据表中ename下面的数据转换位大写输出
select upper(ename)
from emp;
2.INITCAP
(1)功能:
转换字符串首字母大写,其余全部小写
(2)INITCAP(参数1)
参数1:原意字符串或者是字符串数据类型列标题
(3)参数
例如:将 my love java字符串首字母大写,其余小写转换。
select initcap(‘my love java’)
from dual;
3.CONCAT
(1)功能:将两个字符串连接
(2)格式
CONCAT(参数1,参数2)
参数1:原意字符串或者是字符串数据类型列标题
参数2:原意字符串或者是字符串数据类型列标题
(3)实践
例如:将my和sql两个字符串连接到一起。
select concat (‘my’,‘sql’)
from dual;
例如:将ename和job列标题下面的数据连接到一起
select concat(ename,job)
from emp;
4.SUBSTR
(1)截取字符串
(2)格式
SUBSTR(参数1,参数2,参数3)
参数1:原意字符串或者是字符串数据类型列标题
参数2:截取字符串的起始位。 ‘n’
参数3:截取字符串的结束位。 ‘m’
例如:在mysqlcount字符串从第二位截取到第五位。
select substr(‘mysqlcount’,2,5)
from dual;
5.LENGTH
功能:计算字符串长度
LENGTH(参数1)
参数1:原意字符串或者是字符串数据类型列标题
(3)实践计算每个员工列标题字符串长度
select length(ename)
from emp;
6.INSTR
(1)功能:查找字符的位置
(2)格式
instr(参数1,参数2)
参数1:原意字符串或者是字符串数据类型列标题
参数2:原意字符串或者是字符串数据类型列标题
select instr(‘my love java’,‘j’)
from dual;
7.LPAD和RPAD
(1)功能:让原义字符串或者是字符串类型列标题下的数据按照指定宽度输出,在宽度不
满足指定要求时在原义字符串或者是字符串类型列标题下数据的左边或者右边加入占位符
(2)格式
LPAD(参数1,参数2,参数3)
RPAD(参数1,参数2,参数3)
参数1:原意字符串或者是字符串数据类型列标题
参数2:指定输出的宽度
参数3:指定占位符
例如:以10个字符宽度输出每个员工月工资,不满足宽度要求的在左边加*做站位
select ename,lpad(sal,10,’*’)
from emp;
2019-11-28
1.trim
(1)功能:字符截取
(2)格式:trim(参数1 from 参数2)
(3)实践
例如:将s从ssmith字符串中截掉
select trim(‘s’ from ‘ssmith’)
from dual;
二、数值函数
1.ROUND
(1)功能:四舍五入到指定的小数位
(2)格式:round(参数1,参数2)
参数1:数值数据和数值型列标题
参数2:截取的小数位,以个位数为原点,取值为0.
整数部分:-1 … -n .小数部分:1 … n。
(3)实践
例如:92.123保留小数位2,92.156保留小数位2,7835.62
保留在整数部分的十位。
select round(92.123),round(92.156,2),
round(7835.62,-1)
from dual;
2.TRUNC
(1)功能:四舍五入到指定的小数位
(2)格式:trunc(参数1,参数2)
参数1:数值数据和数值型列标题
参数2:截取的小数位,以个位数为原点,取值为0.
整数部分:-1 … -n .小数部分:1 … n。
(3)实践
例如:92.123保留小数位2,92.156保留小数位2,7835.62
保留在整数部分的十位。
select trunc(92.123),trunc(92.156,2),
trunc(7835.62,-1)
from dual;
3.MOD
(1)功能:取余数
(2)mod(参数1,参数2)
参数1:数值数据和数值型列标题
参数2:数值数据和数值型列标题
(3)实践
例如:在emp数据表中将奖金做取余计算
select ename,mod(sal,nvl(comm,2))
from emp;
三、日期函数
1.sysdate
(1)功能:返回一个系统时间
(2)实践
select sysdate
from dual;
2.months_between
(1)功能:计算两个日期之间相差几个月
(2)格式:months_between(参数1,参数2)
参数1:日期数据和日期型列标题
参数2:日期数据和日期型列标题
(3)实践
例如:2019-8月-07和2017-6月-17之间有几个月
select months_between(‘17-6月-2017’,‘7-8月-2019’)
from dual;
3.add_months
(1)功能:在当前日期的基础上增加月份
(2)格式:add_months(参数1,参数2)
参数1:日期数据和日期型列标题
参数2:增加月份的数值
(3)实践
例如:计算当前系统时间增加三个月以后的时间
select add_months(sysdate,3)
from dual;
4.next_day
(1)功能:指定日期之后的某天
例如:计算基于2019年12月5日的下一个周三的日期。
(2)格式
next_day(参数1,参数2)
参数1:日期数据和日期型列标题
参数2:星期几。例如:(星期一 … 星期日) 和 FRIDAY 等。
(3)实践
例如:计算当前系统时间下一个周三的日期
select next_day(sysdate,‘星期三’)
from dual;
例如:计算2020年2月3日的下一个周四的日期。
select next_day(‘3-2月-2020’,‘星期四’)
from dual;
5.last_day
(1)功能:返回某个月的最后一天
(2)格式
last_day(参数1)
参数1:日期数据和日期型列标题
(3)实践
例如:计算当前系统时间这个月的最后一天的日期
select last_day(sysdate)
from dual;
6.round
(1)对日期进行四舍五入截取
(2)round(参数1,参数2)
参数1:日期数据和日期型列标题
参数2:截取年月日
7.trunc
1)对日期进行四舍五入截取
(2)trunc(参数1,参数2)
参数1:日期数据和日期型列标题
参数2:截取年月日
2019-12-2
一、TO_CHAR(日期型数据到字符型数据转换)
1.格式
to_char('参数1,‘fmt’)
参数1:原以日期或者日期型列标题或者日期型函数。
fmt:日期数据的元素
MONTH:完整的月份
MM:双位月份的数字
YEAR:完整的年份。
YYYY:四位数年份
DD:双位数某月的某一天
DAY:星期几的完整英文表示
HH:小时
SS:秒
具体:课本P41
fm:消除前导零或者是空格
2.实践
例如:显示系统时间,时间格式如:03 8月 2020小时:分钟:秒 pm
select to_char(sysdate,‘fm DD MONTH YYYY fmHH:MI:SS PM’)
from dual;
select to_char(sysdate,‘fmDD/MM/YEAR’)
from dual;
select ename,to_char(HIREDATE,‘fm DAY’)
from emp;
二、to_char(数值型数据中)
1.格式
to_char(‘参数1’,‘fmt’)
参数1:原以日期或者日期型列标题或者日期型函数。
fmt:数据元素
fm:清除前导零或者空格
9:数字
0:数据0
,:千位符
.:小数点
$:美元符
参阅p43 表3-4
select ename,to_char(sal,‘fmL9,999.00’)
from emp;
三、to_date
1.功能:将字符型数据转换为数值型数据
2、格式:
to_date(‘参数1’,‘fmt’)
参数1:原以日期或者日期型列标题或者日期型函数。
fmt:日期数据的元素
MONTH:完整的月份
MM:双位月份的数字
YEAR:完整的年份。
YYYY:四位数年份
DD:双位数某月的某一天
DAY:星期几的完整英文表示
HH:小时
SS:秒
参阅 p41 表3-3
3、实践
例如:1987年7月13日入职员工信息。
select ename,hiredate
from emp
where hiredate=to_date(‘7月 13,1987’,‘MONTH DD,YYYY’);
四、to_number
1、功能将字符串转换为数值型数据
2.格式:
to_number(‘参数1’,‘fmt’)
fmt:数据元素
fm:清除前导零或者空格
9:数字
0:数据0
,:千位符
.:小数点
$:美元符
参阅p43 表3-4
3.实践
例如 将’409’转换为数值型数据’409’
select to_number(‘409’,‘fm99,999.00’)
from dual;
五、DECODE条件函数
1.功能:局域数据值为条件完成不同的计算。
2.格式
DECODE(col/expression,search1,result1
[,search2,result2,…,]
[,default])
col:列标题
expression:表达式
search1~searchn:条件
result1~resultn: 结果
default:默认值
3.实践
例如:按照员工的工种,给员工涨工资。
工资方案:
如果是ANALYS则工资涨10%;
如果是CLERK则工资增加15%;
如果MANAGER则工资增加20%;
其他员工不涨工资。
select ename,job,sal,decode(job,‘MANAGER’,sal1.2,
‘CLERK’,sal1.15,
‘ANALYS’,sal*1.1,
SAL)LASTSALARY
from emp;
2019.12.3
例如:按照员工的工资收入,计算员工应该缴纳的税金
税金方案:
1000以下的工资比用缴纳税金
1000~2000 缴纳税金0.01
2000~3000 缴纳税金0.02
3000~4000 缴纳税金0.03
4000~5000 缴纳税金0.04
5000~6000 缴纳税金0.05
6000~7000 缴纳税金0.06
select ename,sal,decode(trunc(sal/1000),1,sal0.01,
2,sal0.02,
3,sal0.03,
4,sal0.04,
5,sal0.05,
6,sal0.06,
0)taxsal
from emp;
一、多表连接
1.分类
等值连接、非等值连接、外部链接、自连接
(1)等值连接
语法一:
select table1.column,table2.column
from table_name1 join table_name2 on 连接条件
语法二:
select table1.column,table2.column
from table1,table2
where table1.column1 = table2.column2;
例如:查看每个员工的工作地点。
select emp.ename,dept.loc
from emp,dept
where emp.deptno = dept.deptno;
jion on 语句的形式
select emp.ename,dept.loc
from emp join dept
on emp.deptno = dept.deptno;
(2)非等值连接:连接之中使用个的运算符,不是"="运算符;
例如:计算每个员工的收入等级
select emp.ename,emp.sal,salgrade.grade
from emp,salgrade
where emp.sal between salgrade.losal and salgrade.hisal;
表别名
select e.ename,e.sal,s.grade
from emp e,salgrade s
where e.sal between s.losal and s.hisal;
(3)笛卡尔积连接(无条件连接)
select *
from emp,dept;
注意:笛卡尔积连接只用于数据的压力测试。其他情况不允许出现。
(4)自连接
数据自己连接自己
例如:查询每个员工上级主管人员的姓名。
select employee.ename,manager.ename
from emp employee,emp manager
where employee.mgr = manager.empno;
组函数和分组统计
一、组函数
sum,avg,count,max,min
二、分组统计
1、语法
注意:
不进行组函数运算的其他列标题必须写入group by 子句中。
select deptno,sum(sal)
from emp
group by deptno;
2019-12-9
子查询(在多重数据集合体查询过程中,建议使用多表连接。而简单的数据使用子查询)

2、分类
行的角度
单行子查询(< > =)
(1)实践
例如:显示和雇员7369从事同一工作并且工资大于雇员7876的雇员的姓
名和工作
select ename,job
from emp
where job=(
select job
from emp
where empno = 7369)
and sal > (select sal
from emp
where empno =7876);
例如:查询收入最低的员工姓名、工种、和收入
select ename,job,sal
from emp
where sal = (select min(sal)
from emp
);
例如:显示部门内最低工资比20部门内最低工资要高的部门编号及部门内最低工作
select deptno,min(sal)
from emp
having min(sal) > (select min(sal) --用having min(sal) 有运算
from emp
where deptno = 20)
group by deptno;
多行子查询(All any in)
any > 大于最小值 any < 小于最大值
all > 大于最大值 all < 小于最小值
例如:查找比JOB为CLERK收入少的而公种不是CLERK的员工代码,员工姓名,公
种和收入。
第一步:查找job为CLERK的员工收入
select sal
from emp
第二步:收入比(800,1100,950,1300)低,而工种不是CLERK员工信息
select empno,ename,job,sal
from emp
where sal < any( select sal —any 小于最大值
from emp
where job=‘CLERK’)
and job <> ‘CLERK’;
区分all
select empno,ename,job,sal
from emp
where sal < any( select sal —all小于最小值
from emp
where job=‘CLERK’)
and job <> ‘CLERK’;
例如:查询比三个部门平均工资都高的员工编号,员工姓名,工种和收入。
select empno,ename,job,sal
from emp
where sal > all (
select avg(sal)
from emp
group by deptno);
区分any
select empno,ename,job,sal
from emp
where sal > any (
select avg(sal)
from emp
group by deptno);
列的角度
1.定义
单列子查询:子查询语句返回单列标题,
多列子查询:子查询语句返回多列标题
多列子查询在处理的过程中,成对多列子查询和非成对多列子查询
2.实践
修改CLARK的薪水和奖金
update emp
set sal=1500,comm=300
where ename=‘CLARK’;
修改SMITH薪水和奖金
update emp
set sal = 1600,comm=300
where ename = ‘SMITH’;
例如:从emp数据表中查询出30部门中任意一个雇员的薪水和佣金相同的雇员,并显示其姓名,部门编号,薪水和佣金。
select ename,deptno,sal,comm
from emp
where (sal,comm) in (select sal,comm
from emp
where deptno=30)
and deptno <> 30;
非成对多列子查询
例如:从emp表中查找出和30部门中任意一个雇员的薪水、佣金相同的雇员,并显示其姓名、部门编号、薪水和佣金。
select ename,deptno,sal,comm
from emp
where sal in (select sal
from emp
where deptno = 30)
and comm in (select comm
from emp
where deptno=30)
and deptno <>30;
四、在子查询出现空值

单列子查询
多列子查询
2019-12-12
五、在from之举中应用子查询
查询大于所在部门平均工资的雇员的姓名、工资、部门编号以及所在部门的平均工资。
第一步:查询所在部门的平均工资
select avg(sal)
from emp
group by deptno
第二步:将子查询结果作为数据表和emp数据表做多表连接
select e.ename,e.sal,e.deptno,a.avsal
from emp e,(select deptno,avg(sal) avsal
from emp
group by deptno) a
where e.deptno=a.deptno
and e.sal>a.avsal;
替代变量
&
&&
define accept
SQL环境
查询结果的查询页眉页脚
设置一页显示多少行
一行显示多少字符
pagesize
ttitle
btitle
column等等
一、使用&替代变量
1、格式
&替代变量名
2、实践
例如:根据输入的员工代码查询员工信息
select ename,sal,empno
from emp
where empno = &emp_no;
如果使用sql命令反复运行: /
方法二:将此方法放在脚本中。使用@、START语句来运行脚本
比如在D盘中,放入脚本test.txt
@d:\test.txt
start d:\test.txt
注意:针对字符串或日期型数据,一定要加单引号 ‘’ ,还要注意相关字母的大小写
例如:通过员工姓名查看运功的基本信息
select ename from emp where ename = ‘&ename’;

select empno,ename,job,&column_name
from emp
where &condition
order by &order_colum;
2019-12-16
一、&&
注意:& 和 && 的区别
通过实践证明,每次在使用&的时候需要重新给变量赋值。使用&&完成替代变量定义之后,只能进行一次变量赋值。
select ename,empno
from emp
where empno = &column_num;
2、格式
&&替代变量名
3、实践
例如将上例中的员工编号替代变量,修改为&&完成定义。
select ename,empno
from emp
where empno = &&column_num;
二、define和accept
1、功能
define:创建一个字符型用户变量
accept:读取用户输入并将其保存在变量中
(1)格式
ACCEPT variable [detatype][FORMAT format]
[PROMPT text]{HIDE}
variable:变量名
detatype:数据类型
format:格式
hide:隐文显示
(2)实践
例如:将替代变量输出提示以,‘请输入职工编号’标题显示。
首先创建脚本
第二步在脚本文件中将以下语句编辑到文件中
ACCEPT column_num PROMPT ‘请输入员工编号’
select ename,empno
from emp
where empno=&column_num;
第三步在命令行中调用执行文件
@ d:\test.txt
define 变量名 [=赋值数据]
(2)实践
例如:定义一个全局变量并在任何查询中反复使用
第一:定义全局变量并赋值(define)
define deptmentname=‘SALES’;
第二步:尝试n次使用全局变量
select deptno
from dept
where dname = ‘&deptmentname’;
再进行查询
select loc
from dept
where dname=’&deptmentname’;
取消定义全局变量(undefine)
undefine deptmentname’;
测试
select deptno
from dept
where dname = ‘&deptmentname’;
定制SQL*Plus环境
set system_variable value
system_variable: 系统环境变量名称。全部软件中都是已经提前定义好的。
比如:linesize、pagesize、HEADING。参阅课本p101-p103
value: 环境变量的数据值
例如:设置单行显示的长度为40个字符
set linesize 40;
SQL*Plus格式化命令
一、COLUMN[column option]
1.功能:设置列标题格式。 比如:列别名、列别名显示在两行中

3、实践
例如:修改显示列标题名称
column loc heading location
select loc
from dept;

format 格式元素。
格式元素,比如An列标题宽度,9数字等,阅读课本P105。
例如:设置员工收入输出数据格式,如$1,200.
column sal format ‘$9,999’
select sal
from emp;
关于其他实践参阅课本P104
二、break命令
1、功能:设置断点
2.命令格式

3、实践
查询每个部门员工每种工种员工总收入。
BREAK ON DEPTNO
select deptno,job,sum(sal)
from emp
group by deptno,job
order by deptno;
三、TTITLE标题和BTITLE脚注
1、格式
TTITLE [text | OFF | ON]
BTITLE [text | OFF | ON]
2、实践
例如:给上列添加标题‘信息与艺术学院’,脚注‘软件技术专业部’
BREAK ON DEPTNO
TTITLE ‘信息与艺术学院’
BTITLE ‘软件技术专业部’
select deptno,job,sum(sal)
from emp
group by deptno,job
order by deptno;
2019.12.18
一、视图
1、视图和表、查询区别
视图是基于数据表根据一定条件创建的静态对象。这个静态对象保存着查询语句。
2、功能:
第一:查看数据
第二:数据的增删改
3、格式

OR REPLACE: 修改视图。
FORCE: 判断基表是否存在,不管基表是否存在都会创建视图。
NOFORCE: 判断基表是否存在,如果基表不存在,视图对象是无法完成视图创建的。
subquery: 子查询
WITH CHECK OPTION [CONSTRAINT constraint]: 检查约束。
WITH READ ONLY: 只读。
4、实践
例如:创建基于emp数据表创建20部门员工信息的视图empview20.
create view empview20 as
select * from emp
where empno = 20;
select * from empview20;
例如:创建每个部门员工的最高收入,运功最低收入和员工的平均收入视图
create view salview
(name,minsal,maxsal,avgsal)
as
select d.dname,min(e.sal),max(e.sal),avg(e.sal)
from emp e,dept d
where e.deptno = d.deptno
group by d.dname;
2019-12-19
一、with check option
1.场景:视图有一个重要的作用是做数据的增删改,
如果用户对视图所做的增删改的数据取值范围有要求的话。在这样情况下
我们使用with check option完成视图的创建。
2、实践
例如:基于部门编号为20的条件,创建视图。视图中可以查看20部门的员工信息,
并且要求将来通过此视图插入(修改)数据的时候必修满足部门编号为20的员工信息才可以
放入数据表中。
create view empvu20
as
select *
from emp
where deptno = 20
with check option constraint empvu20_ck;
测试此选项功能:
尝试修改SMITH员工的部门编号修改为40.
update empvu20
set deptno = 40
where ename=‘SMITH’
对比测试:
create view empvu201
as
select *
from emp
where deptno = 20;
尝试修改SMITH员工的部门编号修改为40.
update empvu201
set deptno = 40
where ename=‘SMITH’
通过上述两组测试,得到如果在创建视图加入with check option之后,数据的插入和修改
操作必须满足检查约束的要求
例如根据工资收入达与5000创建视图empsalview,并加入约束可选项。
尝试测试是否能添加收入2000的员工信息。
create view empsalview
as select * from emp
where sal > 5000
with check option constraint empsalview_ck;
insert into empsalview(empno,sal) values(1000,2000);
insert into empsalview(empno,sal) values(1000,6930);
二、with read only
1.功能:在创建视图的过程中添加了 with read only 这个可选项的话,那么这个视图只能
查看数据而不能做数据的增删改操作了
2.实践
例如:在创建视图的时候添加with read only 可选项。
create view empvu202
as
select *
from emp
where deptno = 20
with read only;
再次修改是否可以通过此视图,修改数据?
修改ford,收入4000.
update empvu202
set sal=4000
where ename=‘FORD’;
第十二章
其他数据库对象
一、序列
1.功能:产生关键字值
2.格式:

3.实践
例如:创建一个以91开始的序列,序列步长为1,最大值为100,循环,不分配存储内存。
CREATE SEQUENCE dept_deptno
INCREMENT BY 1
START WITH 91
MAXVALUE 100
NOCACHE
NOCYCLE;
4、nextval和currval伪列
(1)格式
序列名.nextval
序列名.currval
(2)注意
使用伪列获取数值,应该先使用nextval,再使用currval。
(3)实践
例如:使用currval获取序列数据值
select dept_deptno.currval
from dual;
例如:使用nextval获取序列数据值
select dept_deptno.nextval
from dual;
例如:使用currval获取序列数据值
select dept_deptno.currval
from dual;
通过以上三个案例的运用,得到currval伪列必须放在nextval伪列之后才能正常执行
例如:使用currval插入一条新记录dept。(91,‘FOR’,‘SHANGHAI’)
insert into dept values(dept_deptno.currval,‘FOR’,‘SHANGHAI’);
例如:使用nextval插入一条新纪录dept。(92,‘MAR’,‘JINAN’)
insert into dept values(dept_deptno.nextval,‘MAR’,‘JINAN’);
二、索引
1、场景:提高检索效率。loc为DALLAS的部门信息
2、两种方式:自动创建和手动创建。当您再表中定义了primary key 或 unique 约束,
索引晕自动咋包含该约束的列上创建
3、格式
create index table|(column,…column)
4、实践
例如:为了提高对EMP表的ENAME的查询速度,创建索引。
create INDEX emp_ename_idx
ON emp(ename)
5、索引删除 drop
6、使用数据字典索引
三、同义词
1.场景:给数据库中对象命别名
from emp e,dept d
2、格式
CREATE [PUBLIC] SYNINYM synonym
FOR object;
public:公共,公开
synonym:同义词名称
object:对象名。
3.实践
例如得emp数据表命别名, e
create public synonym e
for emp
测试使用别名查询emp数据表中的相关数据
select ename,empno
from e;
2019-12-25
一、PL/SQL结构


declare
v_empno emp.empno%TYPE;
v_ename emp.ename%TYPE;
cursor emp_cursor is
select empno,ename
from emp;
begin
open emp_cursor;
for i in 1…10 loop
FETCH emp_cursor into v_empno,v_ename;
DBMS_OUTPUT.PUT_LINE(‘职工编号’||v_empno||‘和职工姓名’||v_ename);
end loop;
end;
/