1.NameNode启动过程
- 加载FSImage;
- 回放EditLog;
- 执行CheckPoint(非必须步骤,结合实际情况和参数确定,后续详述);
- 收集所有DataNode的注册和数据块汇报。
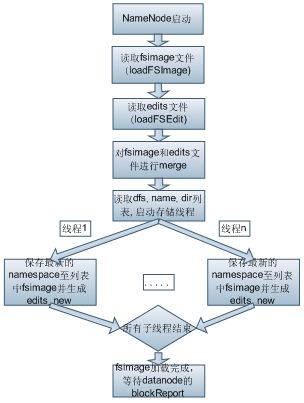
采用多线程写入fsimage,能够有效的提升fsimage加载速度,从而缩短NameNode启动速度。如果NameSpace存在大量文件,使得fsimage文件巨大,则这种时间缩短会更加明显。
重启过程尽可能避免出现CheckPoint。触发CheckPoint有两种情况:时间周期或HDFS写操作事务数,分别通过参数dfs.namenode.checkpoint.period和dfs.namenode.checkpoint.txns控制,默认值分别是3600s和1,000,000,即默认情况下一个小时或者写操作的事务数超过1,000,000触发一次CheckPoint。为了避免在重启过程中频繁执行CheckPoint,可以适当调大dfs.namenode.checkpoint.txns,建议值10,000,000 ~ 20,000,000,带来的影响是EditLog文件累计的个数会稍有增加。从实践经验上看,对一个有亿级别元数据量的NameNode,回放一个EditLog文件(默认1,000,000写操作事务)时间在秒级,但是执行一次CheckPoint时间通常在分钟级别,综合权衡减少CheckPoint次数和增加EditLog文件数收益比较明显。
2.Service RPC port
NameNode默认使用8020端口侦听所有的RPC请求(HDP版本),包括客户端数据请求,DataNode心跳和block上报,ZKFC模块监控检查和切换控制。当集群规模越和RPC请求来越大时,RPC请求响应时间也变得越来越长。
NameNode也给DataNode提供了专用的Service RPC port用于上报数据块和心跳状态,这样可以减少和客户端应用程序RPC队列请求的竞争。这个端口默认没有开启,需要手动配置参数。
Service RPC port另外也用于NameNode HA模块的ZKFC健康检查和auto failover 控制。
3.Namenode数据不断积累造成的问题
1、启动时间变长。NameNode的启动过程可以分成FsImage数据加载、editlogs回放、Checkpoint、DataNode的BlockReport几个阶段。数据规模较小时,启动时间可以控制在~10min以内,当元数据规模达到5亿(Namespace中INode数超过2亿,Block数接近3亿),FsImage文件大小将接近到20GB,加载FsImage数据就需要~14min,Checkpoint需要~6min,再加上其它阶段整个重启过程将持续~50min,极端情况甚至超过60min,虽然经过多轮优化重启过程已经能够稳定在~30min,但也非常耗时。如果数据规模继续增加,启动过程将同步增加。
2、性能开始下降。HDFS文件系统的所有元数据相关操作基本上均在NameNode端完成,当数据规模的增加致内存占用变大后,元数据的增删改查性能会出现下降,且这种下降趋势会因规模效应及复杂的处理逻辑被放大,相对复杂的RPC请求(如addblock)性能下降更加明显。
3、NameNode JVM FGC(Full GC)风险较高。主要体现在两个方面:(1)FGC频率增加;(2)FGC时间增加且风险不可控。针对NameNode的应用场景,目前看CMS内存回收算法比较主流,正常情况下,对超过100GB内存进行回收处理时,可以控制到秒级别的停顿时间,但是如果回收失败被降级到串行内存回收时,应用的停顿时间将达到数百秒,这对应用本身是致命的。
4、超大JVM Heap Size调试问题。如果线上集群性能表现变差,不得不通过分析内存才能得到结论时,会成为一件异常困难的事情。且不说Dump本身极其费时费力,Dump超大内存时存在极大概率使NameNode不可服务。
4.目前namenode使用了ha的部署模式,但系统会经常出现ha的自动切换(namenode节点其实正常)。经过调研发现可能的原因如下:
-
HealthMonitor check本地namenode的rpc端口时超时,导致HealthMonitor认为namenode挂掉。
-
zk上的session timeout,导致丢掉当前持有的active锁(temp节点),引起自动切换。
下面的优化将针对1)和2)调整相应的超时参数,看是否起效。修改core-site.xml