生活不易,且行且珍惜
过年从家回到工作的地方,突然感觉到自己身上的担子重了许多
父母的白头发越来越多,身体也大不如从前,看着他们,我还有什么理由不努力
Bloom过滤器简介
Bloom过滤器:Bloom Filter 是用一个 位数组(数组的每个元素不是1就是0) 来表示一个大的元素集合, 而且通过这个数组就可以判断某个元素是不是属于这个集合(具体的介绍内容可以自行到网上查询)
本文主要介绍的基于hadoop实现的一个简单的Bloom过滤器的实验过程:
本文的过程的思路是:
1.先构建相应的相应的Bloom的二进制文件
2.读取相应的二进制文件进行和输入的数据进行比较的过程
3.MapReduce的处理过程比较Bloom二进制文件产生的结果,如果一致的话就输出相应的结果到Map的输出文件中,由reduce过程处理
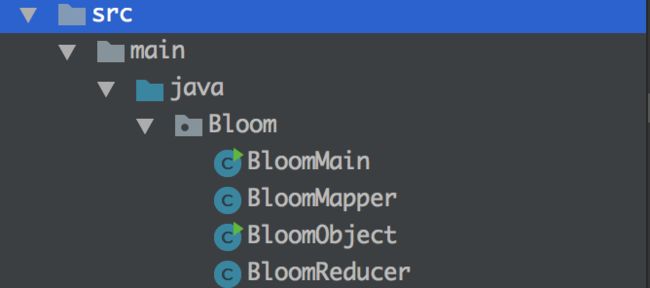 程序目录结构
程序目录结构
Bloom二进制文件产生
BloomObject函数:
其中的main函数执行可以产生相应的二进制文件;
package Bloom;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.util.bloom.BloomFilter;
import org.apache.hadoop.util.bloom.Key;
import org.apache.hadoop.util.hash.Hash;
import java.io.BufferedReader;
import java.io.DataInputStream;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.net.URI;
/*
* bloom的过滤模式,例子是通过筛选出相应的选择地址在候选列表中的交集的集合
* bloom过滤必须要生成一个二进制数据,作为候选选择和处理的数据部分,定义候选的二进制数据结构:
* 哈希函数个数k、二进制数组大小m、字符串数据n 之间存在着相关性,对于给定的m、n,当k=ln(2)*m/n时出错的概率是最小的。本文后面引用网上的数据证明。
* */
public class BloomObject {
//对数据进行转换的函数
public static double k =2.0; //调节二进制数组的相应的参数变量
public static int getBloomSize(int numbersize ,float falsePosError){
int bloomsize = (int)(((-numbersize*(float)Math.log(falsePosError)/(float)Math.pow(Math.log(2),2)))*k);
return bloomsize;
}
//获取hash函数的个数
public static int getBloomHash(float numbersize,float longsize){
int hashsize = (int)(numbersize/longsize*Math.log(2)*k);
return hashsize;
}
/**
* 创建bloom过滤器的数据文件,生成相应的二进制数据文件
* @param fileinput 输入路径
* @param fileoutput 输出路径
* @param errorrate 错误率
* @param numberlong 输入字段长度
* @throws Exception
*/
public static void CreateBloomFile(String fileinput,String fileoutput,float errorrate,int numberlong) throws Exception{
Configuration configuration = new Configuration();
Path inputpath = new Path(fileinput);
Path outputpath = new Path(fileoutput);
FileSystem fileSystem = FileSystem.get(new URI(outputpath.toString()),configuration);
if(fileSystem.exists(outputpath)){
fileSystem.delete(outputpath);
}
//使用hadoop自带的bloom过滤函数
int BloomSize = getBloomSize(numberlong,errorrate);
int BloomHash = getBloomHash(BloomSize,numberlong);
System.out.println("二进制数据的位数-----"+BloomSize);
System.out.println("哈希函数的个数-----"+BloomHash);
BloomFilter bloomFilter = new BloomFilter(BloomSize,BloomHash, Hash.MURMUR_HASH);//定义相应的bloom函数
//把相应的结果存入到相应的输出文件中,正常情况下是hdfs的路径中,也可以是本地路径
//利用hadoop的filesystem的系统的命令把相应的数据存储到hdfs的目录中
FileSystem fileInput = FileSystem.get(new URI(inputpath.toString()),configuration);
String line =null;
for (FileStatus fileStatus:fileInput.listStatus(inputpath)){
//System.out.println(fileStatus.getPath());
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(fileInput.open(fileStatus.getPath())));
while((line=bufferedReader.readLine())!=null){
bloomFilter.add(new Key(line.getBytes("UTF-8"))); //存入到相应的bloom的API的变量中,bloom存放的是二进制的数据因此需要进行转换
System.out.println(line.getBytes("UTF-8"));
}
bufferedReader.close();
}
FSDataOutputStream fsDataOutputStream = fileInput.create(new Path(outputpath+"/bloomtestlog"));
bloomFilter.write(fsDataOutputStream);
//fsDataOutputStream.flush(); //写入到缓存中的数据
fsDataOutputStream.close();
}
public static void main(String[] args) throws Exception {
BloomObject.CreateBloomFile("BloomFile/","BloomFile/outputBloomFile",0.01f,2);
DataInputStream dataInputStream = new DataInputStream(new FileInputStream("BloomFile/outputBloomFile/bloomtestlog"));
BloomFilter filter = new BloomFilter();
filter.readFields(dataInputStream);
dataInputStream.close();
//System.out.println();
//hash函数过多导致即使是不同的数据多次的覆盖之后就会变成0
String str = "/wp-content/uploads/2013/08/ws4.png HTTP/1.1";
if(filter.membershipTest(new Key(str.getBytes("UTF-8")))){
System.out.println(str.getBytes("UTF-8"));
System.out.println("成功匹配二进制文件数据内容,Bloom二进制文件构造成功!");
}
}
}
输出的结果如图:
注意相应的输入文件在相应的目录下只能存在一份数据
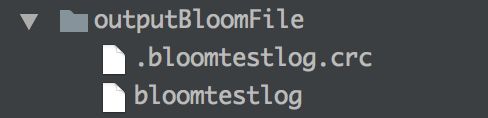
结果图.png
BloomMapper函数:
package Bloom;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.util.bloom.BloomFilter;
import org.apache.hadoop.util.bloom.Key;
import java.io.DataInputStream;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.util.StringTokenizer;
public class BloomMapper {
//bloom过滤器的生成方法,使用mapreduce的方法生成这个过程
//直接读取二进制文件进行存储的过程,设置setup函数获取bloom产生的热点二进制文件的数据进行处理
private static String inputpath;
public static String getInputpath() {
return inputpath;
}
public static void setInputpath(String inputpath) {
BloomMapper.inputpath = inputpath;
}
private static int num=0;
protected static class BloomMapping extends Mapper{
private BloomFilter bloomFilter = new BloomFilter();
//在执行setup函数的时候把相应的产生bloom二进制数据的过程
@Override
public void setup(Context context){
//初始化bloom二进制文件的过程
try{
//调节二进制的数据位数,可以提高过滤的准确性
BloomObject.CreateBloomFile("BloomFile/","BloomFile/outputBloomFile",0.01f,2);
DataInputStream dataInputStream = new DataInputStream(new FileInputStream(BloomMapper.getInputpath()));
bloomFilter.readFields(dataInputStream);
dataInputStream.close();
}catch (Exception e){
e.printStackTrace();
}
}
private Text keyvalue = new Text();
public void map(Object key,Text value,Context context) throws IOException,InterruptedException{
//进行map处理的过程,value为要进行判断的数据结果,如果在value中有对应的选择列表中的数据的话,则提取出结果即可
//对value的每一行的特定位置进行判别,提取数据,以空格区分数据在下标为6的位置上是要进行比较的内容
String[] str = value.toString().split("/");
if(str.length>=4 && str[3]!=" " ){
Key key1= new Key(str[3].getBytes("utf-8"));
keyvalue.set(str[3]);
if(key1.getBytes().length>0) {
if (bloomFilter.membershipTest(key1)) {
context.write(keyvalue, NullWritable.get());
}
}
}
}
}
}
BloomReducer函数没有书写内容,只是使用map函数进行了相应的简单的举例,如果需要reduce的过程可以继续书写相应的过程;
BloomMain函数:
package Bloom;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.net.URI;
public class BloomMain {
public static void main(String[] args) throws Exception{
Configuration configuration = new Configuration();
//需要比对的原始文件的相应的输入路径
Path inputpath = new Path("BloomInputFile/inputfile");
//输出数据文件的路径,这个不需要提前
Path outputpath = new Path("BloomInputFile/outputfile/");
//对bloom的相应的路径进行赋值操作
BloomMapper.setInputpath("BloomFile/outputBloomFile/bloomtestlog");
//做鲁棒性检查
FileSystem fileSystem = FileSystem.get(new URI(outputpath.toString()),configuration);
if(fileSystem.exists(outputpath)){
fileSystem.delete(outputpath,true);
}
Job job = Job.getInstance(configuration,"Bloom");
job.setJarByClass(BloomMain.class);
//把输入和输出路径的相关信息写入到hadoop的相应的变量中
FileInputFormat.setInputPaths(job,inputpath);
FileOutputFormat.setOutputPath(job,outputpath);
//设置map的类
job.setMapperClass(BloomMapper.BloomMapping.class);
//设置map的输出数据类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
//设置reduce输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
//提交job
job.waitForCompletion(true);
}
}
结果如下:
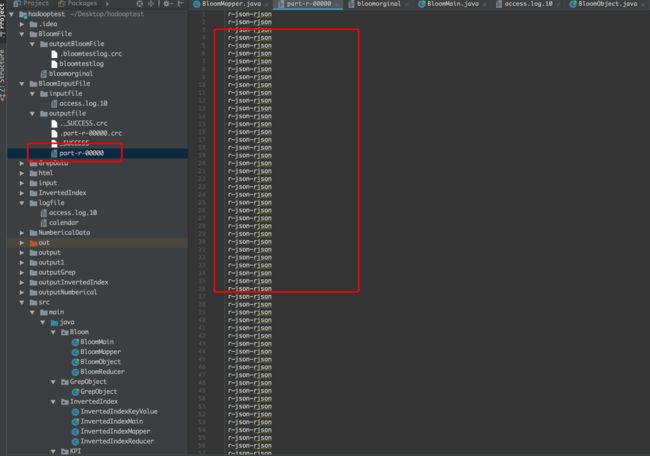
结果
PS:本人才疏学浅,大家一起进步,需要代码的直接留下邮箱,OK