用于视觉问答的统一视觉语言预训练模型《Unified Vision-Language Pre-Training for VQA》
目录
一、文献摘要介绍
二、网络框架介绍
三、实验分析
四、结论
这是视觉问答论文阅读的系列笔记之一,本文有点长,请耐心阅读,定会有收货。如有不足,随时欢迎交流和探讨。
一、文献摘要介绍
This paper presents a unified Vision-Language Pre-training (VLP) model. The model is unified in that (1) it can be finetuned for either vision-language generation (e.g., image captioning) or understanding (e.g., visual question answering) tasks, and (2) it uses a shared multi-layer transformer network for both encoding and decoding, which differs from many existing methods where the encoder and decoder are implemented using separate models. The unified VLP model is pre-trained on a large amount of image-text pairs using the unsupervised learning objectives of two tasks: bidirectional and sequence-to-sequence (seq2seq) masked vision-language prediction. The two tasks differ solely in what context the prediction conditions on. This is controlled by utilizing specific self-attention masks for the shared transformer network. To the best of our knowledge, VLP is the first reported model that achieves state-of-the-art results on both vision-language generation and understanding tasks, as disparate as image captioning and visual question answering, across three challenging benchmark datasets: COCO Captions, Flickr30k Captions, and VQA 2.0.
本文提出了统一的视觉语言预训练(VLP)模型。该模型的统一之处在于:(1)可以针对视觉语言生成(例如,图像描述)或理解(例如,视觉问题)任务进行微调,(2)使用共享的多层transformer网络进行建模编码和解码,这与许多现有方法不同,在现有方法中,使用单独的模型来实现编码器和解码器。在大量的图像-文本对上对统一VLP模型进行了预训练,使用以下两项任务的无监督学习目标:双向和序列对序列(seq2seq)掩码视觉-语言预测。两项任务的区别仅在于预测所基于的上下文。这是通过为共享的transformer网络使用特定的自注意掩码来控制的,下图是作者提出的用于一般视觉语言预训练的统一编码器-解码器模型。
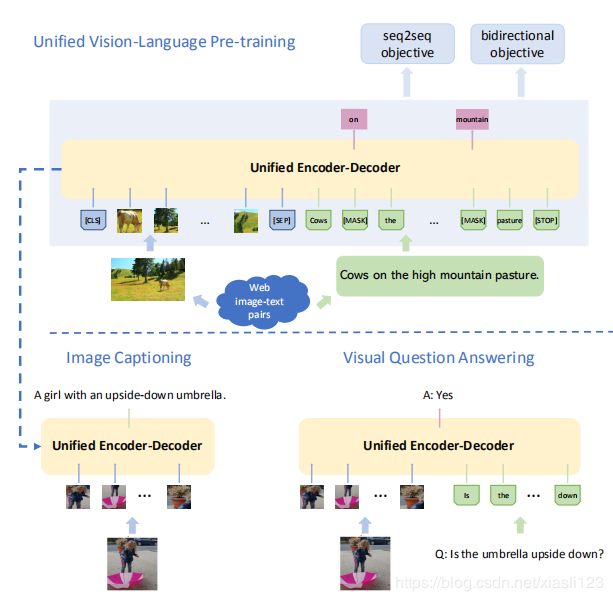

二、网络框架介绍
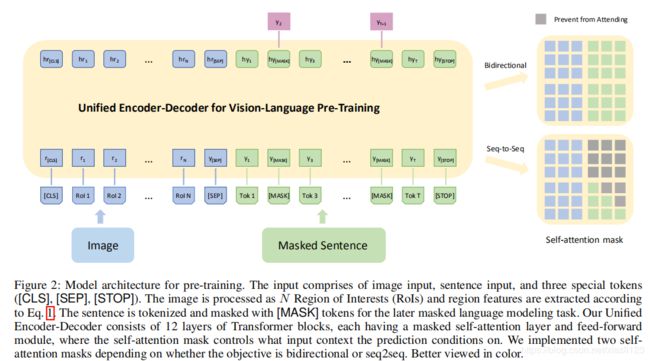
我们将输入图像表示为 ,将关联/目标句子描述(单词)表示为
,将关联/目标句子描述(单词)表示为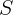 。我们使用现成的物体检测器从图像中提取固定数量的N个物体区域,表示为
。我们使用现成的物体检测器从图像中提取固定数量的N个物体区域,表示为![]() ,相应区域的特征为
,相应区域的特征为![]() ,区域对象标签(概率)为
,区域对象标签(概率)为![]() ,并且区域几何信息为
,并且区域几何信息为![]()
![]() ,其中
,其中 ![]() 是嵌入大小,
是嵌入大小, 表示目标检测器的目标类别数量,o = 5由区域边界框的左上角和右下角坐标的四个值组成( 归一化在0和1之间)和一个相对值(即边界框面积与图像区域之比,也在0和1之间)的值。中的单词表示为
表示目标检测器的目标类别数量,o = 5由区域边界框的左上角和右下角坐标的四个值组成( 归一化在0和1之间)和一个相对值(即边界框面积与图像区域之比,也在0和1之间)的值。中的单词表示为 ![]() 向量,该向量进一步编码为嵌入大小为
向量,该向量进一步编码为嵌入大小为 的单词嵌入:
的单词嵌入:![]() 其中
其中![]() 和
和  表示句子的长度,作者提出的模型如下图2所示。
表示句子的长度,作者提出的模型如下图2所示。
2.1Vision-Language Transformer Network
我们的视觉语言Transformer网络将Transformer编码器和解码器统一为一个模型,如图2(左)所示。模型输入包括类感知区域嵌入,单词嵌入和三个特殊标记。 区域嵌入定义为:
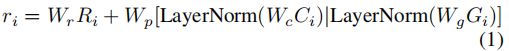
其中![]() 表示特征维度上的连接,LayerNorm表示层规范化。第二项模仿BERT中的位置嵌入,但是添加了额外的区域类别信息,并且
表示特征维度上的连接,LayerNorm表示层规范化。第二项模仿BERT中的位置嵌入,但是添加了额外的区域类别信息,并且![]() 是嵌入权重(省略了偏差项和非线性项)。请注意,这里我们重载了
是嵌入权重(省略了偏差项和非线性项)。请注意,这里我们重载了![]() 的表示法来表示类感知区域嵌入。 另外,我们像BERT一样在ri中添加段嵌入,其中所有区域共享相同的段嵌入,其中值取决于目标(即seq2seq和bidirectional)。
的表示法来表示类感知区域嵌入。 另外,我们像BERT一样在ri中添加段嵌入,其中所有区域共享相同的段嵌入,其中值取决于目标(即seq2seq和bidirectional)。
词嵌入的定义与(Devlin et al.2018)中的定义类似,将![]() 与位置嵌入和段嵌入相加,然后再次将其重载为
与位置嵌入和段嵌入相加,然后再次将其重载为![]() 。 我们定义了三个特殊标记[CLS],[SEP],[STOP],其中[CLS]指示视觉输入的开始,[SEP]标记视觉输入和句子输入之间的边界,[STOP]确定句子的结尾。 [MASK]标记表示被屏蔽的单词。
。 我们定义了三个特殊标记[CLS],[SEP],[STOP],其中[CLS]指示视觉输入的开始,[SEP]标记视觉输入和句子输入之间的边界,[STOP]确定句子的结尾。 [MASK]标记表示被屏蔽的单词。
2.2.Pre-training Objectives
在BERT掩蔽语言建模目标中,15%的输入文本标记首先被替换为一个特殊的[MASK]标记、一个随机标记或原始标记,随机的机会分别等于80%、10%和10%。然后,在模型输出中,来自最后一个Transformer块的隐藏状态被投影到单词可能性,其中以分类问题的形式预测被mask 标记。通过这种重建,模型学习了上下文中的依赖关系,形成了一个语言模型。我们遵循相同的方案,并考虑两个具体目标:BERT中的双向目标(bidirectional)和序列目标的序列(seq2seq)。
如图2(右)所示,这两个目标之间的唯一区别在于self-attention mask。用于双向目标(bidirectional)的掩码允许在视觉模态和语言模态之间无限制地传递消息,而在seq2seq中,将来要预测的单词不能参与这些单词,即满足自回归特性。更正式地说,我们将第一个Transformer块的输入定义为![]()
![]() ,其中
,其中![]() ,然后在不同Transformer级别的编码为
,然后在不同Transformer级别的编码为![]()
![]() 。 我们进一步定义一个self-attention mask为
。 我们进一步定义一个self-attention mask为![]()
![]() ,其中
,其中

为了简单起见,我们假设在self-attention模块中只有一个注意头。然后,![]() 上的自注意力输出可以表示为:
上的自注意力输出可以表示为:
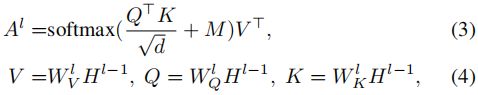
其中![]() 、
、![]() 和
和![]() 是嵌入权重(省略偏置项)。中间变量V,Q和K分别表示值,查询和键,就像在自我注意模块中一样。
是嵌入权重(省略偏置项)。中间变量V,Q和K分别表示值,查询和键,就像在自我注意模块中一样。![]() 由具有残余连接的前馈层进一步编码以形成输出
由具有残余连接的前馈层进一步编码以形成输出![]() 。在预训练期间,我们在两个目标之间交替进行批处理,并且seq2seq和bidirectional比例分别由超参数λ和1-λ确定。
。在预训练期间,我们在两个目标之间交替进行批处理,并且seq2seq和bidirectional比例分别由超参数λ和1-λ确定。
值得注意的是,在实验中,发现将区域类别概率(![]() )合并到区域特征(
)合并到区域特征(![]() )中比使用masked区域分类具有更好的性能。与执行seq2seq训练的方法类似,我们可以以波束搜索的形式将VLP直接应用于序列到序列推理。
)中比使用masked区域分类具有更好的性能。与执行seq2seq训练的方法类似,我们可以以波束搜索的形式将VLP直接应用于序列到序列推理。
三、实验分析
我们将VQA框架化为多标签分类问题,在其中选择前k个最常见的答案作为答案词汇并用作类别标签,将k设置为3129。我们将每个输入图像表示为从在视觉基因组上预先训练的Faster R-CNN 提取的100个对象区域,将fc6层的模型输出作为区域特征(![]() ),将1600个对象类别上的类似然性作为区域对象标签(
),将1600个对象类别上的类似然性作为区域对象标签(![]() )。在[CLS]和[SEP]最后隐藏状态的基础上以元素乘积的方式,学习一个多层感知器(线性+ReLU+线性+Sigmoid),利用交叉熵损失优化模型输出分数。
)。在[CLS]和[SEP]最后隐藏状态的基础上以元素乘积的方式,学习一个多层感知器(线性+ReLU+线性+Sigmoid),利用交叉熵损失优化模型输出分数。
表2 模型在各个数据集上的表现结果
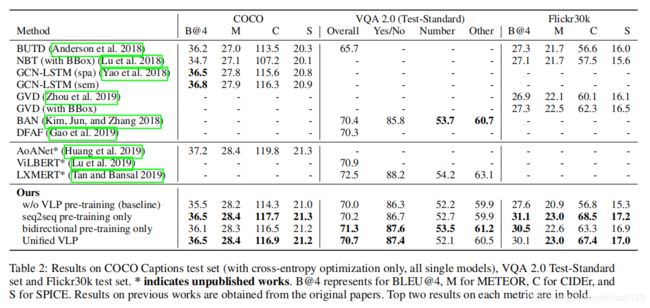
表4:不同水平的预训练对下游任务的影响。
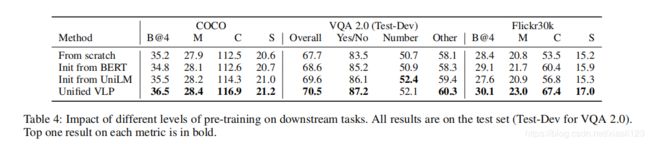
图3:COCO标题和VQA2.0的定性示例。

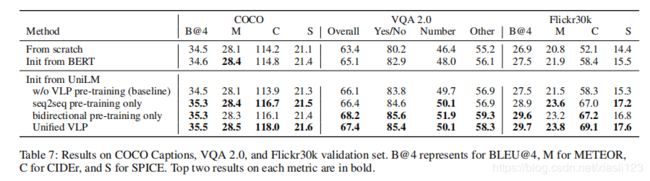
表7:COCO标题、VQA2.0和Flickr30k验证集的结果。
四、结论
This paper presents a unified Vision-Language Pre-training (VLP) model that can be fine-tuned for both vision-language generation and understanding tasks. The model is pretrained on large amounts of image-text pairs based on two objectives: bidirectional and seq2seq vision-language prediction. The two disparate objectives are fulfilled under the same architecture with parameter sharing, avoiding the necessity of having separate pre-trained models for different types of downstream tasks (i.e., generation-based or understanding-based). In our comprehensive experiments on image captioning and VQA tasks, we demonstrate that the large-scale unsupervised pre-training can significantly speed up the learning on downstream tasks and improve model accuracy. Besides, compared to having separate pre-trainedmodels, our unifified model combines the representations learned from different objectives and yields slightly compromised but decent (SotA) accuracy on all the downstream tasks. In our future work, we would like to apply VLP to more downstream tasks, such as text-image grounding and visual dialogue. Methodology-wise, we would want to see how multi-task fine-tuning can be applied to our framework to alleviate interference between different objectives.
本文提出了一个统一的视觉语言预训练(VLP)模型,该模型可以针对视觉语言生成和理解任务进行微调。基于两个目标:双向和seq2seq视觉语言预测,该模型在大量图像-文本对上进行了预训练。这两个不同的目标在相同的架构下通过参数共享得以实现,从而避免了针对不同类型的下游任务(即基于生成或基于理解)使用单独的预训练模型的必要性。在有关图像描述和VQA任务的综合实验中,我们证明了大规模的无监督预训练可以显着加快对下游任务的学习并提高模型准确性。此外,与使用单独的预训练模型相比,我们的未确定模型将从不同目标中学到的表示形式进行了组合,并且在所有下游任务上产生了略微妥协但令人满意的(SotA)准确性。在未来的工作中,我们希望将VLP应用于更多下游任务,例如文本图像基础和视觉对话。在方法论方面,我们希望了解如何将多任务微调应用于我们的框架以减轻不同目标之间的干扰。
本文设计的目标是统一视觉语言预训练,把视觉问答和图像描述上游任务进行统一,下游任务进行微调,就可以完成图像描述和视觉问答任务,该方法还是比较创新的,值得推荐。