java解析json文件并保存到mysql数据库
一、数据是从“聚合数据”这个网站获取的,点我下载json文件,访问相应的地址,就返回很长的json格式的数据。因为不太了解json数据格式,我自己另外加了双引号(其实值的部分可以是数字类型的,不用引号)添加后如下图所示:

可以看出来数据是有很多行的,因为中间的部分格式比较统一,所以我再截个开头部分的图片吧,如下图所示:

这个json文件的结构也不是很复杂,最外层的大括号(大括号表示对象)里面有四个键,分别是resultcode、reason、result、error_code,其中呢,我只关心result里面的数据,所以我要把result里面的省市县数据保存到数据库当中。
二、解析这个json文件数据需要4种jar包,分别是:
①“mysql数据库驱动jar包”
②“阿里巴巴数据库连接池druid驱动jar包”
③“JdbcTemplate相关jar包”
④“fastjson”
点击我下载所需jar包和druid的配置文件。
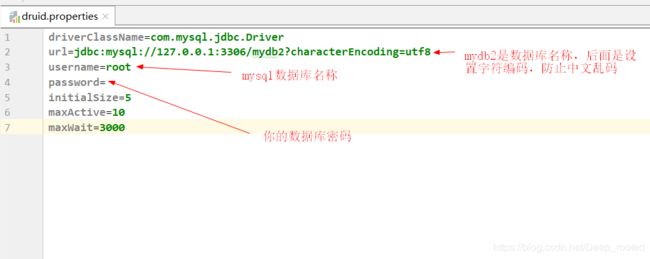
其中呢,druid配置文件需要你自己修改,如下图所示:
三、另外还需要一个JDBCUtils这么一个工具类,没特殊需要的话,不用修改,代码如下:
package bao;
import com.alibaba.druid.pool.DruidDataSourceFactory;
import javax.sql.DataSource;
import java.io.IOException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.Properties;
/**
* Druid连接池的工具类
*/
public class JDBCUtils {
//1.定义成员变量 DataSource
private static DataSource ds ;
static{
try {
//1.加载配置文件
Properties pro = new Properties();
pro.load(JDBCUtils.class.getClassLoader().getResourceAsStream("druid.properties"));
//2.获取DataSource
ds = DruidDataSourceFactory.createDataSource(pro);
} catch (IOException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 获取连接
*/
public static Connection getConnection() throws SQLException {
return ds.getConnection();
}
/**
* 释放资源
*/
public static void close(Statement stmt,Connection conn){
/* if(stmt != null){
try {
stmt.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(conn != null){
try {
conn.close();//归还连接
} catch (SQLException e) {
e.printStackTrace();
}
}*/
close(null,stmt,conn);
}
public static void close(ResultSet rs , Statement stmt, Connection conn){
if(rs != null){
try {
rs.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(stmt != null){
try {
stmt.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(conn != null){
try {
conn.close();//归还连接
} catch (SQLException e) {
e.printStackTrace();
}
}
}
/**
* 获取连接池方法
*/
public static DataSource getDataSource(){
return ds;
}
}
四、给省市县数据写一个实体类。用IntelliJ IDEA写一个标准java实体类还是很快速的,因为可以用快捷键快速插入常见的setter、getter等方法。实体类代码如下:
package bao;
public class CityBean
{
private int id;
private String province;
private String city;
private String district;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getProvince() {
return province;
}
public void setProvince(String province) {
this.province = province;
}
public String getCity() {
return city;
}
public void setCity(String city) {
this.city = city;
}
public String getDistrict() {
return district;
}
public void setDistrict(String district) {
this.district = district;
}
@Override
public String toString() {
return "CityBean{" +
"id=" + id +
", province='" + province + '\'' +
", city='" + city + '\'' +
", district='" + district + '\'' +
'}';
}
}
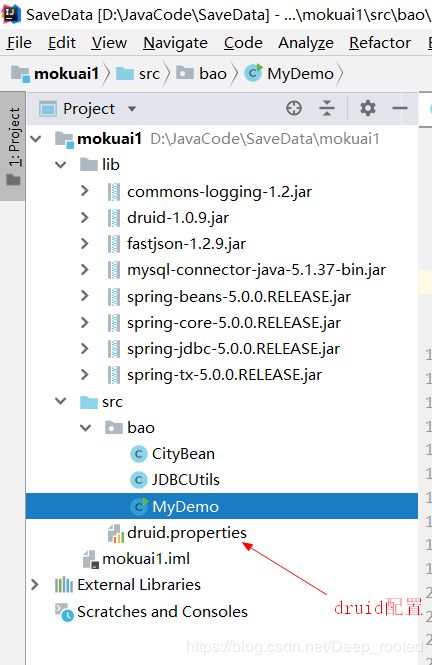
五、项目的结构如下图所示,其中druid配置文件我是放在src目录下的。
六、main方法入口所在的类MyDemo的代码如下:
package bao;
import com.alibaba.fastjson.JSONReader;
import org.springframework.jdbc.core.JdbcTemplate;
import java.io.FileReader;
public class MyDemo
{
public static void main(String[] args) throws Exception
{
JdbcTemplate template=new JdbcTemplate(JDBCUtils.getDataSource());
String sql="insert into city values (?,?,?,?)";//定义sql
JSONReader reader=new JSONReader(new FileReader("D:\\mydata.txt"));
reader.startObject();//开始解析最外层的对象
while (reader.hasNext())//遍历最外层的对象
{
String key = reader.readString(); //读取键的值
if(key.equals("resultcode"))
{
String zhi=reader.readObject().toString();
System.out.println("resultcode为:"+zhi);
}
else if(key.equals("reason"))
{
String zhi=reader.readObject().toString();
System.out.println("reason为:"+zhi);
}
else if(key.equals("result"))
{
reader.startArray();//开始解析数组
while (reader.hasNext())//遍历数组
{
CityBean cityBean=new CityBean();//创建city对象
reader.startObject();//开始解析最内层的对象
while (reader.hasNext())//遍历最内层的对象
{
String jian=reader.readString();
String zhi=reader.readObject().toString();
//封装对象,给对象设置属性值
if(jian.equals("id"))
{
cityBean.setId(Integer.parseInt(zhi));
}
if (jian.equals("province"))
{
cityBean.setProvince(zhi);
}
if(jian.equals("city"))
{
cityBean.setCity(zhi);
}
if(jian.equals("district"))
{
cityBean.setDistrict(zhi);
}
}
template.update(sql,cityBean.getId(),cityBean.getProvince(),cityBean.getCity(),cityBean.getDistrict());//执行sql
reader.endObject();
}
reader.endArray();
}
else if (key.equals("error_code"))
{
String zhi=reader.readObject().toString();
System.out.println("error_code为:"+zhi);
}
}
reader.endObject();//结束解析最外层的对象
}
}
七、运行结果如下图:

用SQLyog图形化工具查看结果,看看数据是否已保存到数据库,如下图所示:
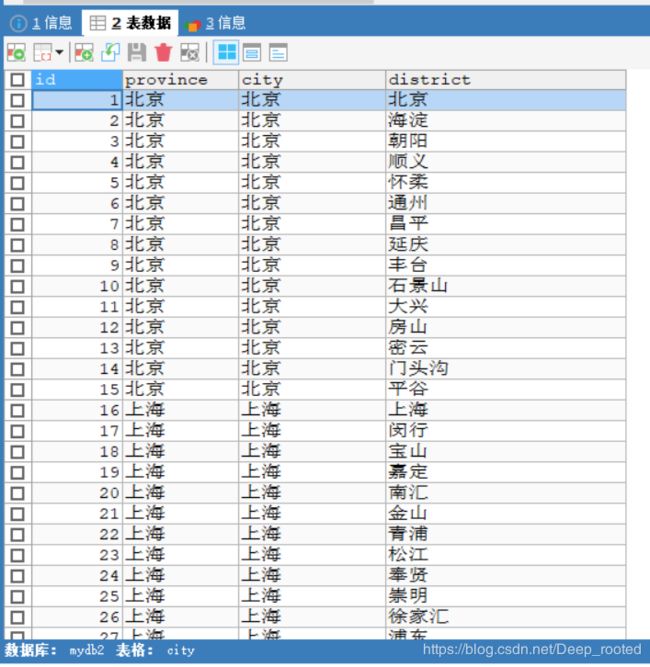

从上面两幅图可以看出来,数据库中已经保存了2594条数据。其实呢,这两千多条的数据不是一下子就保存完的,我的的电脑解析并保存这些数据大概需要一两分钟的时间。
八、最后的分析和说明
- 数据库操作方面,你只需关心sql语句如何写就ok了,其他方面不用关心,因为用了相关的jar包。
- 对于fastjson,有东西需要额外说明:
①: reader.startObject();//开始解析对象
②: reader.startArray();//开始解析数组
③: reader.endObject();//结束解析对象
④: reader.endtArray();//结束解析数组
⑤:reader.readString();//读取键的名称
⑥:reader.readObject().toString();//读取键值对的“值”部分
⑦: while (reader.hasNext())//在这里呢,是用来遍历一个对象或者是数组的。观察上面的解析代码,你会发现这么一个规律:先声明一下自己要解析的是对象还是数组,然后就开始用while循环去遍历对象或者是数组。
稍微了解javascript的都知道,json里面,大括号表示对象,中括号表示数组。有人可能会说,while循环里面嵌套了那么多的while循环,这也太难阅读了。我要说,的确难以阅读,但是,写起来却非常简单。因为在写之前,你只需要明确你要遍历的是一个对象还是数组就OK了,别忘了在遍历之前使用startObject()或者是startArray()哦! - 写这个解析代码我还遇到了一个问题,就是刚开始的时候我只会将一列的数据插入到数据库表当中。解决问题的办法是我在睡着之前突然想到的,第二天一醒来就马上动手实践了一下,没想到思路居然是正确的,成功地将每一列的数据插入到了数据库表当中。具体思路如下:
①:在遍历数组对象的while循环里面,new一个对象
CityBean cityBean=new CityBean();//创建cityBean对象
②:然后又进入了一个while循环,在这个时候,需要循环4次,才能将表格的一行数据(一个元组)给取出来。这时就需要根据键名,给cityBean对象设置对应的属性值。
③:最内层的while循环结束之后,cityBean对象就完整地设置好了4个属性:id、province、city、district。
④这个时候,就可以执行下面的sql语句了,
String sql="insert into city values (?,?,?,?)";
下面是给sql语句的每一个问号,指定相应的值:
template.update(sql,cityBean.getId(),cityBean.getProvince(),cityBean.getCity(),cityBean.getDistrict());//执行sql