Re:从零开始的DS生活 轻松从0基础写出链表LRU算法
引言:Re:从零开始的DS生活 轻松从0写出链表LRU算法,作为Re:0专题的第一篇,本文从ds概念说起,详细介绍了顺序表(数组)和链表的相关知识与源码解析,并配合LRU链表实战,文内有大量练习,适合点赞+收藏。有什么错误希望大家直接指出~友情链接:Re:从零开始的DS生活 轻松从0基础写出Huffman树与红黑树、Re:从零开始的DS生活 轻松从0基础实现多种队列
导读(有基础的同学可以通过以下直接跳转到感兴趣的地方)
线性表之顺序表(数组)
不给命题组面子之顺序表概念及特性
吊打面试官之Java ArrayList源码crud简析(内附ArrayList源码解读)
LeetCode题目练习
线性表之链表
链表的定义及种类(单链表、双链表、循环链表、静态链表、带哨兵的双向链表)
LeetCode题目练习
顺序表和链表的总结与对比
线性表面试题总结
链表实现LRU算法
内存缓存淘汰算法(缓存算法、页面置换算法)
数据结构概述
作为Data Structures开篇,首先我们聊聊下面这四个问题:1、为什么需要学习数据结构? 2、什么是数据结构? 3、数据结构包含哪些内容?4、怎样学习数据结构?
为什么需要学习数据结构,举个例子,我塞牙了,要用到牙签这“数据结构”,当然你用指甲也行,只不过“性能”没那么好;我想去旅游,当然可以走路去,只不过“速度”没开车那么快。在实际开发中数据结构都在我们使用的“轮子”里,虽然多数不需要我们造轮子,但是我们至少要知道为什么轮子是圆的,当然最重要的一点是考试、考研以及面试的时候也会被问到。
那什么是数据结构,下面这段代码数据结构吗?
public class Person {
String head;
String body;
String arm;
String leg;
}该Person类还不能称为数据结构,为什么呢,因为数据结构 是相互之间存在一种或多种特定关系的元素的集合,数据结构包括逻辑结构、存储结构、数据的运算 。而Person只能称为数据元素(一个数据元素可以由若干个数据项组成)。
数据结构包含的内容也叫数据结构的三要素:逻辑结构:是指数据对象中数据元素之间的相互关系,主要有线性结构,集合结构、树形结构、图状结构。存储结构:数据结构在计算机中的表示主要有顺序存储,链式存储,索引存储,散列存储。以及数据的运算。
 、
、
现在对数据结构已经有了初步的了解,那么研究那些内容呢?线性表、队列、堆栈、树、图论、排序和查找。
线性表之顺序表(数组)
线性表 是具有相同数据结构类型的n(n≥0)个数据元素的有序序列,n为表长,当n=0时为空表。包括顺序存储和链式存储。
顺序表 线性表的顺序存储有称顺序表。它使用一组地址连续的存储单元依次存储线性表中的数据元素,从而使逻辑上相邻的两个元素在物理位置上也相邻。
不给命题组面子之顺序表概念及特性
品一下会发现,这不就是数组么,实现是的没有错,但是别急,下面介绍他的特性,可以看下图,a1是a2的前驱,ai+1 是ai的后继,a1没有前驱,an没有后继 。

假设线性表的元素是Object,则线性表的顺序存储结构怎么实现呢?
// 顺序表的类型定义
public class ArrayList extends AbstractList
implements List, RandomAccess, Cloneable, java.io.Serializable {
private static final Object[] EMPTY_ELEMENTDATA = {}; // 顺序表的元素
private int size; // 顺序表的当前长度
} 因为顺序表逻辑上相邻的两个元素在物理位置上也相邻,所以说①可以通过首地址和元素序号在时间O(1)内找到指定元素;
②顺序表的存储密度更高,每个节点只存数据元素;③插入和删除操作需要移动大量元素。掌握理论知识,下面学习具体操作。
吊打面试官之Java ArrayList源码crud简析(内附ArrayList源码解读)
新增数据(新增数据至尾部):①数组容量检查,想要的最小容量+1(保证资源不会被浪费),如果最小容量>数组缓冲区当前长度(最小容量 - 数组长度)时进行扩容,②对数组进行复制处理,并将index后的元素位移一个位置③将元素e放在size的位置上,并且size++。时间复杂度O(n)。
/**
* 将指定元素插入到列表中的指定位置。将当前位于该位置的元素(如果有的话)和随后的任何元素向右移动(将一个元素添加到它们的索引中)。
*
* @param index index at which the specified element is to be inserted
* 要插入指定元素的索引(即将插入元素的位置)
* @param element element to be inserted 即将插入的元素
* @throws IndexOutOfBoundsException {@inheritDoc} 如果索引超出size
*/
public void add(int index, E element) {
//越界检查
rangeCheckForAdd(index);
//确认list容量,如果不够,容量加1。注意:只加1,保证资源不被浪费
ensureCapacityInternal(size + 1); // Increments modCount!!
// 对数组进行复制处理,目的就是空出index的位置插入element,并将index后的元素位移一个位置
//在插入元素之前,要先将index之后的元素都往后移一位
//arraycopy(原数组,源数组中的起始位置,目标数组,目标数据中的起始位置,要复制的数组元素的数量)
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
//将指定的index位置赋值为element
elementData[index] = element;
//实际容量+1
size++;
}
private void rangeCheckForAdd(int index) {
if (index > size || index < 0)//插入的位置不能大于size 和小于0,如果是就报越界异常
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}读取操作(查找操作):①先是判断一下有没有越界(索引小于0或者大于等于数组实际长度,错误信息返回索引和数组的实际长度)②通过数组下标来获取元素。时间复杂度O(1)
/**
* 返回list中指定位置的元素
*
* @param index index of the element to return 要返回的元素的索引
* @return the element at the specified position in this list
* 位于list中指定位置的元素
* @throws IndexOutOfBoundsException {@inheritDoc}
*/
public E get(int index) {
rangeCheck(index);//越界检查
return elementData(index);//返回索引为index的元素
}
/**
* 检查指定索引是否在范围内。如果不在,抛出一个运行时异常。
* 这个方法不检查索引是否为负数,它总是在数组访问之前立即优先使用,
* 如果给出的索引index>=size,抛出一个越界异常
*/
private void rangeCheck(int index) {
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
private String outOfBoundsMsg(int index) {
return "Index: " + index + ", Size: " + size;
}
// Positional Access Operations 位置访问操作
// 返回索引为index的元素
@SuppressWarnings("unchecked")
E elementData(int index) {
return (E) elementData[index];
}更新操作(根据index修改数据):①检查索引是否越界。如果参数指定索引index>=size,抛出一个越界异常②记录被替换的元素(旧值)③替换元素(新值)④返回被替换的元素。时间复杂度O(1)
/**
* 用指定的元素替换列表中指定位置的元素。
* @param index index of the element to replace 要替换的元素的索引
* @param element element to be stored at the specified position 要存储在指定位置的元素
* @return the element previously at the specified position 先前位于指定位置的元素(返回被替换的元素)
* @throws IndexOutOfBoundsException {@inheritDoc} 如果参数指定索引index>=size,抛出一个越界异常
*/
public E set(int index, E element) {
//检查索引是否越界。如果参数指定索引index>=size,抛出一个越界异常
rangeCheck(index);
//记录被替换的元素(旧值)
E oldValue = elementData(index);
//替换元素(新值)
elementData[index] = element;
//返回被替换的元素
return oldValue;
}
删除操作(根据index删除数据):①检查索引是否越界。如果参数指定索引index>=size,抛出一个越界异常 ②结构性修改次数+1 ③记录索引处的元素④如果有需要左移的元素,就移动(移动后,该删除的元素就已经被覆盖了)。时间复杂度O(n)。
/**
* 删除list中位置为指定索引index的元素
* 索引之后的元素向左移一位
*
* @param index the index of the element to be removed 被删除元素的索引
* @return the element that was removed from the list 被删除的元素
* @throws IndexOutOfBoundsException {@inheritDoc} 如果参数指定索引index>=size,抛出一个越界异常
*/
public E remove(int index) {
//检查索引是否越界。如果参数指定索引index>=size,抛出一个越界异常
rangeCheck(index);
//结构性修改次数+1
modCount++;
//记录索引处的元素
E oldValue = elementData(index);
// 删除指定元素后,需要左移的元素个数
int numMoved = size - index - 1;
//如果有需要左移的元素,就移动(移动后,该删除的元素就已经被覆盖了)
if (numMoved > 0)
System.arraycopy(elementData, index + 1, elementData, index, numMoved);
// size减一,然后将索引为size-1处的元素置为null。为了让GC起作用,必须显式的为最后一个位置赋null值
elementData[--size] = null; // clear to let GC do its work
//返回被删除的元素
return oldValue;进阶之顺序表(数组)LeetCode题目练习
26. 删除排序数组中的重复项
35. 搜索插入位置
34. 在排序数组中查找元素的第一个和最后一个位置
线性表之链表
链表:线性表的链式存储结构的特点是用一组任意的存储单元存储线性表的数据元素,这组存储单元可以是连续的,也可以是不连续的。
链表的定义及种类(单链表、双链表、循环链表、静态链表、带哨兵的双向链表)
单链表:指通过一组任意的存储单元来存储线性表中的数据元素。为了建立数据元素之间的线性关系,对每个链表结点除存放元素自身的信息外,还需要存放一个指向其后继的指针。
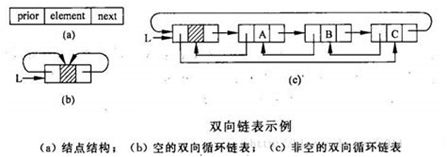
双链表:单链表节点中只有一个指向其后继的指针,使单链表只能从头结点一次顺序地向后遍历,为了克服上述缺点,双链表结点中有两个指针prior和next,分别指向其前驱和后继结点。
静态链表:实质上是一维数组的存储方式,所以它在物理位置上的存储,但它是用游标来指向下一个数据的,所以根据它的下标来获取数据。
public class Node { // 单链表定义
E data; //创建一个存储数据的属性
Node next; //创建存储下一个节点地址的属性
}
public class Node { // 双链表定义
E data; //创建一个存储数据的属性
Node prev; //创建存储上一个节点地址的属性
Node next; //创建存储下一个节点地址的属性
}
public class Node{ // 静态链表定义
int data;
int cur;
}
// 使用 Node[] linkList = null; linkList[i] = new Node(); 循环单链表:循环单链表和单链表的区别在于,表中最后一个结点不是NULL,而是改为指向头结点,从而形成一个环。(循环链表可在任意一点开始遍历整个链表,一般情况不设置头指针,仅设尾指针,若r为尾指针,r->next 或 r.next 即为头指针)
循环双链表:头结点的prior指针指向表尾结点,表尾结点的next指针指向头结点。
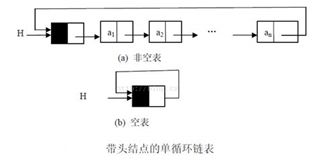
通过上述定义,我们对链表有了初步了解,下面分别采用头插法和尾插法建立单链表
public class Node {
Object data; //创建一个存储数据的属性
Node next; //创建存储下一个节点地址的属性
int length = 0;
/**
* 逆向创建一个链表-头插法是将新形成的节点的下一个赋值为header,再把新形成的节点地址传给header即将header向前移动
*
* @param temp 添加的数据
* @return 链表第一个节点地址
*/
public Node add(Integer temp) {
Node newnode, header; //定义链表的节点
header = null; //header永远存储第一个节点的地址,tailer永远存储最后一个节点的地址
newnode = new Node(); // 创建一个临时节点
newnode.data = temp; //为属性赋值
//判断当前链表是否第一次赋值
if (header == null) {
header = newnode;
} else {
newnode.next = header; //将新节点连接到链表的头部
header = newnode; //header永远存储第一个节点的地址
}
//长度
length++;
return header;
}
/**
* 创建一个链表-尾插法相对于头插法有些许不同 因为要返回头,头不能动,所以需要一个tailer来记录最后一个值 tailer右移
*
* @param temp 添加的数据
* @return 链表第一个节点地址
*/
public static Node creat(Integer temp) {
Node newnode, header, tailer; // 定义链表的节点
header = tailer = null; // header永远存储第一个节点的地址,tailer永远存储最后一个节点的地址
newnode = new Node();// 创建一个临时节点
newnode.data = temp; // 为属性赋值
//判断当前链表是否第一次赋值
if (header == null) {
header = tailer = newnode;
} else {
tailer.next = newnode; // 将新节点连接到链表的尾部
tailer = newnode; // tailer永远存储最后一个节点的地址
}
//长度
length++;
return header;
}
}上述代码包括单链表的添加,单链表的删除代码如下:
// 方法一-直接删除p结点
p.data = p.next.data; // 令p和p.next的数据对调
p.next = p.next.next; // 将p指向p.next的下一个
// 方法二-查找删除节点的前驱结点q
q = getElem(list, i-1); // 遍历链表查找删除位置的前驱
q.next = p.next; // 令q为p结点的后继
p.next = null; // GC回收
双链表添加和删除:
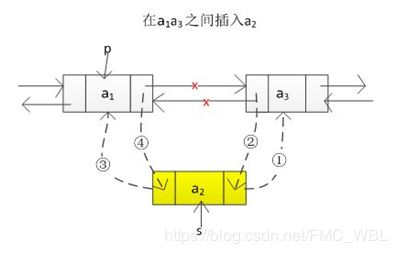
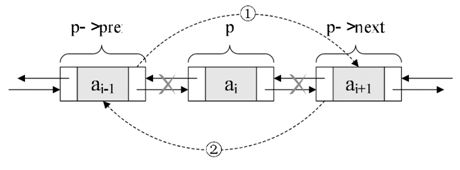
// 图一将s结点插入到P结点后
s.next = p.next;
p.next.prev = s;
s.prev = p;
p.next = s;
// 图二删除结点
p.next.prev = p.prev;
p.pre.next = p.next; 带哨兵的双向链表
带哨兵节点的链表,需要额外的一个节点,但插入和删除等操作不需要额外的判断;不带哨兵节点,在处理链表为空时需要判断(后续LRU代码中有体现)
带哨兵节点的链表,插入或删除时,不论操作的位置,表头都不变,不需要额外的判断;不带哨兵节点的链表,插入或删除操作发生在第一个节点时,表头指针都要变化,需要额外的处理。(原理如图所示)
/**
* 带哨兵的双向链表
*
* @author fmc
* @date 2020/5/1-19:19
*/
public class DoubleLinkedList {
private Node nil; // 哨兵节点
public DoubleLinkedList() {
nil = new Node(null); // NIL节点的key值没有实际的意义
nil.pre = nil; // NIL.next指向自己
nil.next = nil; // NIL.pre也指向自己
}
// 当添加了若干个节点之后,NIL.next指向头节点,而NIL.pre则指向尾节点;
public void insert(Object o) {
Node e = new Node(o);
e.next = nil.next; // ① 如果是第一次插入,nil的next指向第一个节点,如果是n(n>1)次,新e的后继指向前一个插入节点(老e)
nil.next.pre = e; // ② 如果是第一次插入,nil的pre指向头结点,如果是n(n>1)次,老e的前驱指向新e
nil.next = e; // ③ nil节点next 指向新插入的节点(尾结点)
e.pre = nil; // ④ 新插入的节点的前驱指向 哨兵节点
}
// 查询
public Node search(Object o) {
Node e = nil.next;
while (e != nil && e.key != o) { // 从nil节点开始遍历
e = nil.next; // 向后查询
}
return e;
}
// 删除
public void delete(Object o) {
Node e = search(o);
e.pre.next = e.next;
e.next.pre = e.pre;
}
// 节点定义为双链
public class Node {
public Object key;
private Node pre;
private Node next;
public Node(Object x) {
this.key = x;
}
}
}
进阶之链表LeetCode题目练习
21. 合并两个有序链表
24. 两两交换链表中的节点
138. 复制带随机指针的链表
顺序表和链表的总结与对比
|
|
优点 |
缺点 |
应用 |
| 顺序表 |
存储空间连续 允许随机访问 尾插,尾删方便 |
插入效率低 删除效率低 长度固定 |
ArrayList |
| 单链表 |
随意进行增删改 插入效率高 删除效率高 长度可以随意修改 |
内存不连续 不能随机查找
|
Android: MessageQueue JavaEE: HashMap Redis |
| 双链表 |
随意进行增删改 插入效率高 删除效率高 长度可以随意修改 查找效率比单链表快一倍 |
内存不连续 不能随机查找,但是效率比单链表快一倍
|
LinkedList
|
线性表面试题总结
一、ArrayList的大小是如何自动增加的?
二、什么情况下你会使用ArrayList?
三、在索引中ArrayList的增加或者删除某个对象的运行过程?效率很低吗?解释一下为什么?
四、ArrayList如何顺序删除节点。
五、ArrayList的遍历方法。
六、手写一个单链表,并且实现单链表元素的逆置,(a0, a1,a2,a3,..an)-> (an,an-1,… a1, a0),算法的空间复杂度和时间复杂度经可能低。
七、手写双向链表, 实现增删改查,同时对比自己的LinkList 和源码Linkedlist的异同点。
八、对比源码Arraylist 和LinkedList 的优缺点区别。
------------------------------------------------------------------------------------
你以为到这里就结束了吗,从零开始的DS生活 轻松从0基础写出链表LRU算法的实战篇正式开始
简单介绍一下什么是LRU算法
链表实现LRU算法
首先需要大概了解什么是缓存?
缓存分两种,硬件缓存(cpu缓存:位于CPU与内存之间的临时存储器。 解决CPU速度和内存速度的速度差异问题。)与软件缓存(内存缓存、数据库缓存、网络缓存)。那什么是内存缓存呢?预先将数据写到了容器(list,map,set)等数据存储单元中,就是软件内存缓存。
内存缓存淘汰算法(缓存算法、页面置换算法)
比如我们在登录网页时,网页就可以缓存一些用户信息;比如我们在写界面代码的时候,可能就会遇到界面的绘制是基于一些缓存算法的。当我们给定一个有限的空间,来设计一个算法用于更新和访问里面的数据是多用一下三种方法。
LRU(The Least Recently Used),最近最久未使用算法。如果一个数据在最近一段时间没有被访问到,那么可以认为在将来它被访问的可能性也很小。因此,当空间满时,最久没有访问的数据最先被置换(淘汰)。
FIFO(First in First out),先进先出。即如果一个数据是最先进入的,那么可以认为在将来它被访问的可能性很小。空间满的时候,最先进入的数据会被最早置换(淘汰)掉。
LFU(Least Frequently Used ),最近最少使用算法。如果一个数据在最近一段时间很少被访问到,那么可以认为在将来它被访问的可能性也很小。因此,当空间满时,最小频率访问的数据最先被淘汰。
其中,LRU(The Least Recently Used)如果使用链表实现,可推断出需要大致三步完成
①新数据插入到链表头部
②当缓存命中(即缓存数据被访问),数据要移到表头
③当链表满的时候,将链表尾部的数据丢弃
public class LruLinkedList {
//节点的信息
class Node {
T data;
Node next;
public Node(T data, Node node) {
this.data = data;
this.next = node;
}
}
Node list; // 保存链表
int size; // 链表有多少个节点
int memory_size; // 用于限定内存空间大小,也就是缓存的大小
static final int DEFAULT_CAP = 5;
public LruLinkedList() {
this(DEFAULT_CAP);
}
public LruLinkedList(int default_memory_size) {
memory_size = default_memory_size;
}
// LRU添加节点
public void lruPut(T data) {
if (size >= memory_size) {
removeLast();
put(data);
} else {
put(data);
}
}
// 在头部添加节点
public void put(T data) {
Node head = list;
Node curNode = new Node(data, list);
list = curNode;
size++;
}
// LRU删除
public T lruRemove() {
return removeLast();
}
// LRU访问
public T lruGet(int index) {
checkPositionIndex(index);
Node node = list;
Node pre = list;
for (int i = 0; i < index; i++) {
pre = node;
node = node.next;
}
T resultData = node.data;
// 将访问的节点移到表头
pre.next = node.next;
Node head = list;
node.next = head;
list = node;
return resultData;
}
public T removeLast() {
if (list != null) {
Node node = list;
Node cur = list;
while (cur.next != null) {
node = cur;
cur = cur.next;
}
node.next = null;
size--;
return cur.data;
}
return null;
}
// 检测index是否在链表范围以内
public void checkPositionIndex(int index) {
if (!(index >= 0 && index <= size)) {
throw new IndexOutOfBoundsException("index: " + index + ", size: " + size);
}
}
} 总结
本文从ds概念说起,详细介绍了顺序表(数组)和链表的相关知识与源码解析,并配合LRU链表实战,文内有大量练习,适合点赞+收藏。
有什么错误希望大家直接指出~

参考链接及书籍:
https://blog.csdn.net/joob000/article/details/81196165
https://blog.csdn.net/u010250240/article/details/89762912
《数据结构考研复习指导》
《操作系统考研复习指导》