JAVA8中Stream API中常用方法用法
一、流的简介(Stream)
Stream通过函数式编程方式通过流水线的方式对集合类数据进行内部迭代处理。
- 流只能遍历一次
List title = Arrays.asList("Java8", "In", "Action");
Stream s = title.stream();
s.forEach(System.out::println);
s.forEach(System.out::println);
- 内部迭代和外部迭代的区别
//集合通过for-each来进行外部迭代
List names = new ArrayList<>();
for(Dish d: menu){ //显示的迭代菜单列表
names.add(d.getName()); //将提取的名添加了集合中
}
//内部迭代
menu.stream
.map(Dish::getName())//通过getName方法来参数化map
.collect(toList());
- 流的操作分为中间操作,终端操作
中间操作:在执行的时候会返回一个流,如(filter,map,sorted等),多个中间操作连接成一条流水线,在遇到终端操作的时候,一次性全部处理
map (mapToInt, flatMap 等)、 filter、 distinct、 sorted、 peek、 skip、 parallel、 sequential、 unordered
终端操作:会从流水线中返回结果(foreach,collect等)
forEach、 forEachOrdered、 toArray、 reduce、 collect、 min、 max、 count、iterator
短路:anyMatch、 allMatch、 noneMatch、 findFirst、 findAny、 limit
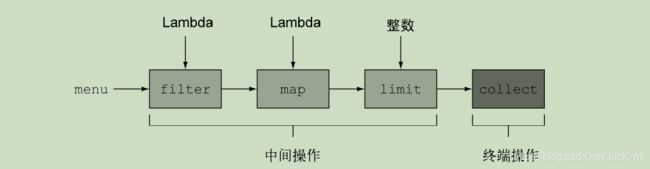
下面得一些方法用法测试都将用一下实体测试:
//以菜单类为例:
public class Dish {
private final String name;
private final boolean vegetarian;
private final int calories;
private final Type type;
private final CaloricLevel caloricLevel;
public Dish(String name, boolean vegetarian, int calories, Type type,CaloricLevel caloricLevel) {
this.name = name;
this.vegetarian = vegetarian;
this.calories = calories;
this.type = type;
this.caloricLevel = caloricLevel;
}
public String getName() {
return name;
}
public boolean isVegetarian() {
return vegetarian;
}
public int getCalories() {
return calories;
}
public Type getType() {
return type;
}
public CaloricLevel getCaloricLevel(){
return caloricLevel;
}
@Override
public String toString() {
return name;
}
public enum Type { MEAT, FISH, OTHER }
public enum CaloricLevel { DIET,NORMAL,FAT}
}
List menu = Arrays.asList(
new Dish("pork", false, 800, Dish.Type.MEAT,null),
new Dish("beef", false, 700, Dish.Type.MEAT,null),
new Dish("chicken", false, 400, Dish.Type.MEAT,null),
new Dish("french fries", true, 530, Dish.Type.OTHER,null),
new Dish("rice", true, 350, Dish.Type.OTHER,null),
new Dish("season fruit", true, 120, Dish.Type.OTHER,null),
new Dish("pizza", true, 550, Dish.Type.OTHER,null),
new Dish("prawns", false, 300, Dish.Type.FISH,null),
new Dish("salmon", false, 450, Dish.Type.FISH,null) );
二、流的一些常用的函数用法介绍
filter:遍历数据用来检查元素时使用,接受一个谓词(一个返回boolean的函数)作为参数, 并返回一符合谓词的元素流。
//检查是否是素菜
List dishes = menu.stream().filter(Dish::isVegetarian).collect(toList());

distinct:用来去除在筛选数据中的重复数据。
List numbers = Arrays.asList(1, 2, 1, 3, 3, 2, 4);
numbers.stream()
.filter(i -> i % 2 == 0)
.distinct()
.forEach(System.out::println);
//结果:2 4
skip:跳过的前n个数据的流,如果流中的元素不足n个,那么将返回一个空流。
List numbers = Arrays.asList(1, 2, 1, 3, 3, 2, 4);
numbers.stream()
.filter(i -> i % 2 == 0)
.skip(2)
.forEach(System.out::println);
//结果:4
limit:从流中获取前n个数据 。
List numbers = Arrays.asList(1, 2, 1, 3, 3, 2, 4);
numbers.stream()
.filter(i -> i % 2 == 0)
.limit(2)
.forEach(System.out::println);
//结果: 2 2
peek:查看每个值,同时可以操作流。
menu.stream().map(Dish::getCalories).peek(p -> {
System.out.println(p);
}).collect(toList());
map:生成一个一对一映射,将接受函数的结果映射到map中。
//获取菜单中菜的名称
List dishNames = menu.stream()
.map(Dish::getName)
.collect(toList());
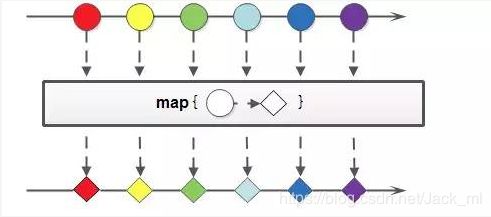
flatmap:顾名思义,跟map有点相似,把一个流中的每个值都换成另一个流,然后把所有的流连接起来成为一个流。
String[] arrayOfWords = {"Goodbye", "World"};
Stream streamOfwords = Arrays.stream(arrayOfWords);
List uniqueCharacters =
words.stream()
.map(w -> w.split("")) //将每个单词转换为由其字母构成的数组
.flatMap(Arrays::stream) //将各个生成的流扁平化成一个流
.distinct()
.collect(Collectors.toList());
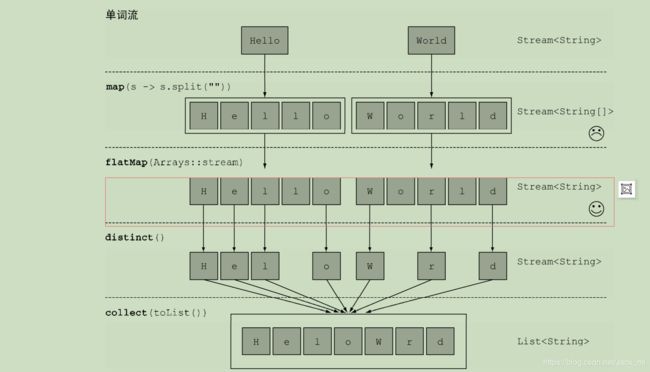
reduce:归约操作,类似于递归,将数值进行累加。
List integers = Arrays.asList(1, 2, 3, 4, 5);
//reduce使用 归约
//统计数组中的总和
Integer integer1 = integers.stream()
.reduce(0, (n, n1) -> (n + n1));
//计算数组中的最大值
Integer integer2 = integers.stream().reduce((x, y) -> x < y ? x : y).get();
Optional integer3 = integers.stream().reduce(Integer::max);
colllect:触发流的归约操作,生成一个列表,map等数据结构。例如:toList(),toSet(),toMap(),自定义等。
//toList
List dishes = menu.stream().filter(Dish::isVegetarian).collect(toList());
//toSet
Set set = menu.stream().filter(Dish::isVegetarian).collect(toSet());
//toMap
Map dishMap = menu.stream().collect(toMap(Dish::getName, Dish::getCalories));
自定义collect:
首先我们先了解一下Collector接口:在这里插入代码片
public interface Collector {
Supplier supplier();
BiConsumer accumulator();
Function finisher();
BinaryOperator combiner();
Set characteristics();
}
T是流中要收集的项目的泛型。
A是累加器的类型,累加器是在收集过程中用于累积部分结果的对象。
R是收集操作得到的对象(通常但并不一定是集合)的类型。
supplier():用来创建新的容器
accumulator():累加器,将元素累加到容器中
finisher():对容器应用做转换,方便累加器对象转换成整个集合操作的最终结果,如果不需要转换,只需返回identity()函数
combiner():将所有累加器中的子操作进行合并,在并行处理的时候会划分成多个部分来进行处理
characteristics():
UNORDERED——归约结果不受流中项目的遍历和累积顺序的影响
CONCURRENT——accumulator函数可以从多个线程同时调用,且该收集器可以并行归约流
IDENTITY_FINISH——这表明完成器方法返回的函数是一个恒等函数,可以跳过。这种情况下,累加器对象将会直接用作归约过程的最终结果。
//自定义collect
List collect = Stream.of("1", "2", "3", "4").collect(Collectors.reducing(new ArrayList()//创建容器
, x -> Arrays.asList(x),//将元素累加
(y, z) -> {
y.add(z + "");
return y; //将元素合并
}));
maxBy:计算最大值.
//查询菜单中热量最大值
Optional dish = menu.stream().collect(maxBy(Comparator.comparingInt(Dish::getCalories)));
System.out.println(dish);
minBy:计算流中的最小值(与minBy用法一致)
summingInt:汇总操作,用来计算总数,最大值,最小值,平均值.
IntSummaryStatistics summaryStatistics = menu.stream().collect(summarizingInt(Dish::getCalories));
System.out.println(summaryStatistics.toString());//可通过get方法获取单个数据
join:用于将字符串进行拼接.
//join将字符串拼接
String s = menu.stream().map(Dish::getName).collect(joining(","));
System.out.println(s);
reducing: 归约操作,和reduce一样用法,只是在collect中。
//归约,查询菜的总热量
Integer total = menu.stream().collect(
reducing(0, Dish::getCalories, (s1, s2) -> (s1 + s2)));
groupingBy:分组,比如说:将某种物品按照类型进行分组。
//将菜单按照菜的类型进行分组
Map> map = menu.stream().collect(groupingBy(Dish::getType));
System.out.println(map.keySet());
在groupingBy中支持多级分组,产生的数据类似于树形结构
Map>> list = menu.stream().collect(groupingBy(Dish::getType,
groupingBy(dish1 -> {
if (dish1.getCalories() <= 400) {
return Dish.CaloricLevel.DIET;
} else if (dish1.getCalories() <= 700) {
return Dish.CaloricLevel.NORMAL;
} else {
return Dish.CaloricLevel.FAT;
}
})));
按子组收集数据:查询每个菜单类型中,热量最高的菜
Map> map1 =
menu.stream().collect(
groupingBy(Dish::getType,
maxBy(Comparator.comparingInt(Dish::getCalories))));
collectingAndThen:收集器返回类型的转换。
//返回的是Optional
Map> map1 =
menu.stream().collect(
groupingBy(Dish::getType,
maxBy(Comparator.comparingInt(Dish::getCalories))));
//将Optional 转换成Dish实体
Map map2 =
menu.stream().collect(
groupingBy(Dish::getType,
collectingAndThen(
maxBy(Comparator.comparingInt(Dish::getCalories)), Optional::get)));
partitioningBy:按分区进行分组,返回的是boolean类型,所以最多分成:true,false两组。
//把菜单按照素食和非素食分组
Map> map3 = menu.stream().collect(
partitioningBy(Dish::isVegetarian));
parallel:将顺序执行操作转换成并行操作,与将Stream替换成parallelStream类似。
在并发执行中,影响性能的因素:数据大小、源数据结构、值是否装箱、可用的CPU核数量,以及处理每个元素所花的时间。
//测试性能 我的电脑是i7700HQ 2.6HZ
public class ParallelStreams {
/**
* @methodDescription 通过流来进行遍历
* @param @long n
* @return
* @exception
* @date 2019/4/10 9:50
*/
public static long sequentialSum(long n){
return Stream.iterate(1L,i -> i+1)
.limit(n).reduce(0L,Long::sum);
}
/**
* @methodDescription 通过并行流进行遍历
* @param @long n
* @return long
* @exception null
* @date 2019/4/10 9:48
*/
public static long parallelSum(long n){
return Stream.iterate(1L,i ->i+1)
.limit(n).parallel().reduce(0L,Long::sum);
}
/**
* @methodDescription for循环
* @param * @param null
* @return
* @exception
* @date 2019/4/10 10:00
*/
public static long iterativeSum(long n) {
long result = 0;
for (long i = 1L; i <= n; i++) {
result += i;
}
return result;
}
/**
* @methodDescription 使用LongStream
* @param @long n
* @return long
* @exception
* @date 2019/4/10 10:01
*/
public static long rangedSum(long n) {
return LongStream.rangeClosed(1, n)
.reduce(0L, Long::sum);
}
/**
* @methodDescription 将LongStream流使用并行
* @param @long n
* @return long
* @exception
* @date 2019/4/10 10:01
*/
public static long parallelRangedSum(long n) {
return LongStream.rangeClosed(1, n)
.parallel()
.reduce(0L, Long::sum);
}
public static long measureSumPerf(Function adder, long n) {
long fastest = Long.MAX_VALUE;
for (int i = 0; i < 10; i++) {
long start = System.nanoTime();
long sum = adder.apply(n);
long duration = (System.nanoTime() - start) / 1_000_000;
System.out.println("Result: " + sum);
if (duration < fastest) {
fastest = duration;
}
}
return fastest;
}
//需要对基本数据类型进行装箱和拆箱
//Sequential sum done in:98 msecs
System.out.println("Sequential sum done in:" +
measureSumPerf(ParallelStreams::sequentialSum, 10_000_000) + " msecs");
//for循环底层不需要对原始的数据类型进行装箱和拆箱
//iterativeSum sum done in:2 msecs
System.out.println("iterativeSum sum done in:" +
measureSumPerf(ParallelStreams::iterativeSum, 10_000_000) + " msecs");
//iterate生成的是装箱的对象,必须拆箱成数字才能求和,很难把iterate分成多个独立块来并行执行
//parallelSum sum done in:312 msecs
System.out.println("parallelSum sum done in:" +
measureSumPerf(ParallelStreams::parallelSum, 10_000_000) + " msecs");
//使用longStream 来解决装箱和拆箱的问题
//rangedSum sum done in:4 msecs
System.out.println("rangedSum sum done in:" +
measureSumPerf(ParallelStreams::rangedSum, 10_000_000) + " msecs");
//使用多种处理方式来处理,顺序 和并行
//parallelRangedSum sum done in:1 msecs
System.out.println("Sequential sum done in:" +
measureSumPerf(ParallelStreams::parallelRangedSum, 10_000_000) + " msecs");
Optional:核心库中的数据类型,用来取代null
of(T):通过静态工厂初始化Optional实例
ofNullable(T):T不能为空,否则初始化报错
isPresent():判断是否为空
orElse(T):给null赋默认值
//如果dish1不为空,则打印名称,否则打印none
Dish dish1 = new Dish();
Optional optional = Optional.of(dish1);
System.out.println(optional.isPresent()?optional.get().getName():"none");
//如果值为空,返回-
System.out.println(Optional.ofNullable(null).orElse("-"));
System.out.println(Optional.ofNullable(1).orElse(2));