Mysql索引与底层实现
Mysql索引与底层实现
以下笔记整理自鲁班学院的课程。
问:数据库中最常见的慢查询优化方法是什么?
答:加索引。
问:为什么加索引能优化慢查询?
答:因为索引其实就是一种优化查询的数据结构,比如Mysql中的索引是通过B+树实现的,B+树可以优化查询的速度,从而利用索引可以快速查找数据,优化查询速度。
问:还有那些数据结构可以提高查询速度?
答:哈希表,完全平衡二叉树、B树、B+树等。
哈希表
哈希表(Hash table,也叫散列表),根据关键码值(key value)直接进行访问的数据结构。它通过把key映射到表中的一个位置来访问记录,以加快查找速度。这个映射函数叫做散列函数,存放记录的数据叫做散列表。
哈希表的做法很简单,其实就是把Key通过一个固定的算法函数(哈希函数)转换成一个整形数字,然后就将该数字对数组长度取余,取余的结果当作下标,将value存储在以该数字为下标的数组空间里。使用哈希表进行查找的时候,再次使用哈希函数对查找的关键码值进行哈希映射,定位到取余结果来获取value。
优点:可直接按key进行查找,效率较高;
缺点:不能进行范围查找!!!
AVL树
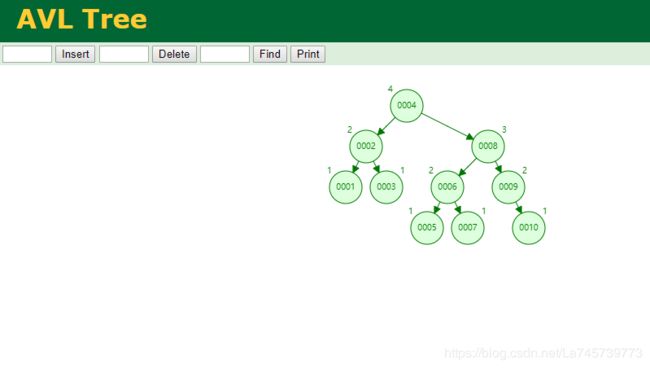
AVL树的每个节包含4个部分:
1、左指针,指向左子树;
2、键值;
3、键值所对应的数据的存储地址;
4、右指针,指向右子树;
如果现在要查找10:
(1)第一次与根4相比,大于4;
(2)第二次与8相比,大于8;
(3)第三次与9相比,大于9;
(4)第四次与10行比,等于10
比较了4次得到查找结果;其效率显然是低于哈希表的,但是由于AVL树是有序的,因此支持范围查找;但是查找次数的增加会导致磁盘I/0的次数增加,从而不可忽视的影响查找效率。
B树
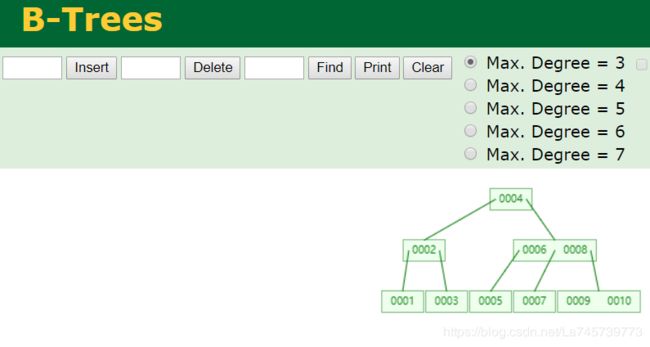
很容易发现,B树的高度要低于AVL树,B树的节点可以存储多个元素;查找10的过程需要比较3次,较AVL树的查找比较次数少1;
B+树

B+树比B树要胖,叶子结点冗余包含了非叶子节点;每个叶子节点增加一个指向相邻叶子节点的指针;
优点:叶子节点有指向相邻叶子节节点的指针,提高了范围查找的效率。
缺点:一个节点存放元素的数量不容易确定?
B+树的优势是什么?
实际上,索引是需要占用存储单元的,当一个表的数据行越多,对应的索引文件也就会越大;索引需要存储在磁盘中,不能够存储在内存中;所以在选择索引的数据结构时应该考虑哪种结构适合从磁盘I/O;
通过上述的图已经可知,B树和B+树的高度一般会低于AVL树,从而查找的效率会高于AVL树;B树和B+树相对于AVL的有点就在于它们可以一个节点存储多个元素,降低树的高度从而提高磁盘I/O效率;
B+树是B树的升级版,只是把非叶子节点冗余到叶子节点,这么做的好处是为了提高范围查找的效率;
磁盘预读和局部性原理
计算机科学中的局部性原理:当一个数据被用到时,其附近的数据通常也会马上被使用。所以操作系统为了提高效率,读取数据时往往不是严格按需读取,而是要预读取所需数据和其附近的数据。操作系统向磁盘读取数据以页为单位,一般操作系统的页大小是4KB。
因此B+树的一个节点最好存储页的倍数最合适。Mysql中B+树的一个节点大小就是1页,mysql自定义了页的大小;
在InnoDB引擎中,页的大小是16K,可以使用命令 **SHOW GLOBAL STATUS like ‘Innodb_page_size’;**查看;
通常B+树的非叶子节点不存储数据(只存储键值),只有叶子节点才存储数据(表的行信息或者表行的地址);而B树的非叶子节点和叶子节点都会存储数据,会导致非叶子节点存储的索引值更少,树的高度会比B+树高,平均查找的I/O效率低。
Mysql中MyISAM和Innodb引擎使用B+树作为索引结构,非叶子节点不存储数据,叶子节点存储数据,一个非叶子节点内能存储更过的key值,树的度变大,I/O效率增加;叶子节点有指向相邻叶子节点的指针,提高了范围查找的效率。
MyISAM引擎中的B+树
MyISAM中的叶子节点的数据区域存储的是数据记录的地址


MYISAM的索引,B+树叶子几点中存放的是数据所在的地址,因此除了建立索引所需要的磁盘I/O外,取数据时还需要一次磁盘I/O,并且主键索引和辅助索引无明显区别。
Mysql中InnoDB引擎中的B+树
Mysql中的InnoDB中主键索引的叶子几点的数据区域存储的是数据记录,辅助索引存储的是主键值。

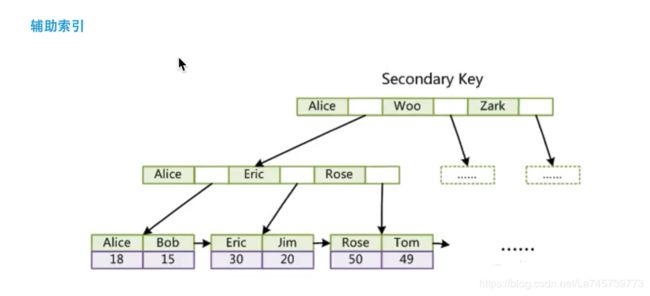
InnoDB中的主键索引和实际数据是绑定在一起的,也就是说InnoDB的一个表一定要有主键索引,如果一个表没有手动建立主键索引,Innodb会查看有没有唯一索引,如果有则选用唯一索引作为主键索引,如果没有唯一索引,会默认建立一个隐藏的主键索引。
因此,Innodb的主键索引比MyISAM的主键索引查询效率要高,少了一次最后取数据的磁盘I./O。在使用Innodb引擎时,最好手动建立主键索引,尽量利用主键索引查询。
Explain 执行计划
Explain + 一个sql语句可以返回一个表,告知此sql语句是否用到了索引。
type字段
type字段提供了判断sql语句是否高效的重要依据。通过type字段,可以判断此次sql语句是全表扫描还是索引扫描。


Key和Key-len字段

索引顺序
假设对一个数据表建立了3个索引(emp_no,title,fromdate),他们按一定的顺序组织成节点,然后组成B+树。

全列匹配
EXPLAIN SELECT * FROM employees.titles WHERE emp_no=‘10001’ AND title=‘Senior Engineer’ AND from_date=‘1986-06-26’;
+----+-------------+--------+-------+---------------+---------+---------+-------------------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+-------+---------------+---------+---------+-------------------+------+-------+
| 1 | SIMPLE | titles | const | PRIMARY | PRIMARY | 59 | const,const,const | 1 | |
+----+-------------+--------+-------+---------------+---------+---------+-------------------+------+---
当按照索引中所有列进行精确匹配(这里精确匹指“=”或“IN”匹配)时,索引可以被用到。
理论上索引对顺序是敏感的,但是由于MySQL的查询优化器会自动调整where子句的条件顺序以使用适合的索引,例如将where中的条件顺序颠倒:
EXPLAIN SELECT * FROM employees.titles WHERE from_date=‘1986-06-26’ AND emp_no=‘10001’ AND title=‘Senior Engineer’;
+----+-------------+--------+-------+---------------+---------+---------+-------------------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+-------+---------------+---------+---------+-------------------+------+-------+
| 1 | SIMPLE | titles | const | PRIMARY | PRIMARY | 59 | const,const,const | 1 | |
+----+-------------+--------+-------+---------------+---------+---------+-------------------+------+-------+
最左前缀匹配
这句sql语句的key_len是56,因为emp_no是int占4字节,title是varchar(50),占52字节,拉丁字符编码;因此,这句查询用到了两个索引;
EXPLAIN SELECT * FROM employees.titles WHERE emp_no = ‘2’ AND title = ‘S’;
这句sql语句的key_len是4,表明只用到了第一个索引,emp_no,但是from_date没有办法使用。一个取巧的方法是,可以把它们中间的索引title也加上,在不改变sql语句愿意的情况下。
EXPLAIN SELECT * FROM employees.titles WHERE emp_no = ‘2’ AND from_date= ‘S’;
不是最左前缀不会触发
EXPLAIN SELECT * FROM employees.titles WHERE from_date='1986-06-26';
+----+-------------+--------+------+---------------+------+---------+------+--------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+------+---------------+------+---------+------+--------+-------------+
| 1 | SIMPLE | titles | ALL | NULL | NULL | NULL | NULL | 443308 | Using where |
+----+-------------+--------+------+---------------+------+---------+------+--------+-------------+

![]()

最左前缀原则:根据索引的顺序,从最左边查找,如果条件能够缩小查询范围,代表索引键是使用的了。

索引选择性越大,越适合建立索引。
![]()
type 类型的解释
| ALL | 全表扫描
| index | 索引全扫描
| range | 索引范围扫描,常用语<,<=,>=,between等操作
| ref | 使用非唯一索引扫描或唯一索引前缀扫描,返回单条记录,常出现在关联查询中
| eq_ref | 类似ref,区别在于使用的是唯一索引,使用主键的关联查询
| const/system | 单条记录,系统会把匹配行中的其他列作为常数处理,如主键或唯一索引查询