云计算基础(三):HDFS+MapReduce
HDFS开发基础;
HDFS分布式存储应用开发;
MapReduce开发基础;
MapReduce编程模型应用;
Map和Reduce作业机制和应用;
HadoopI/O开发;
MapReduce应用程序开发;
1、Hadoop分布式环境配置
克隆已配置好hadoop和java环境的虚拟机,并重命名主机名已做区分。

查看两台机器的IP地址
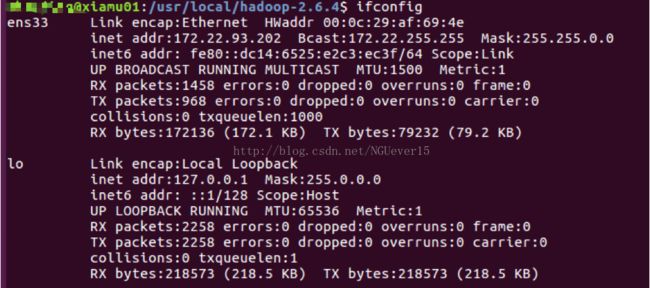
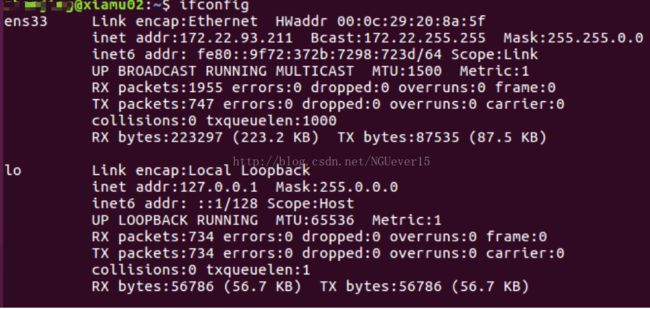
开始正式的分布式配置之前,选定xiamu01为master,xiamu02为 slave。
接着,在master上开启hadoop
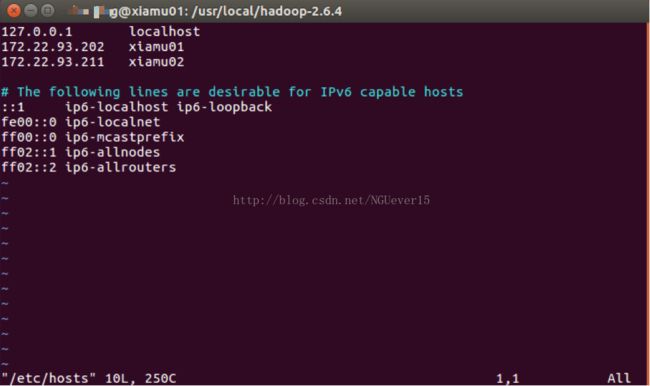
通过下面两条指令锡膏hostname以及,两个节点的名称与对应ip的关系
sudo vim/etc/hostname
sudo vim/etc/hosts
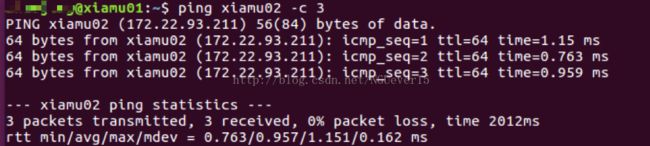
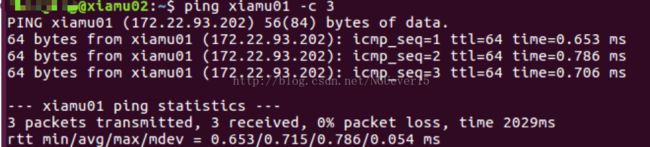
检测是否能够相互ping 通
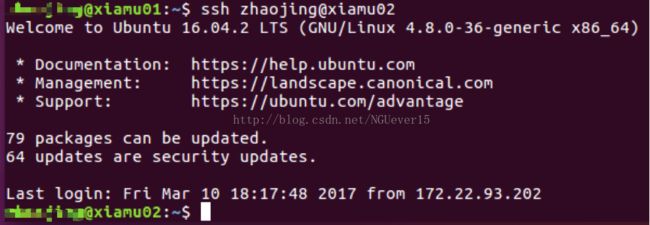
接下来实现免密钥登陆,效果如下:

配置PATH变量
执行vim ~/.bashrc,加入一行:
exportPATH=$PATH:/usr/local/Hadoop-2.6.4/bin:/usr/local/Hadoop-2.6.4/sbin
修改/usr/local/Hadoop-2.6.4/etc/Hadoop路径下的slaves文件,内容改为xiamu02。
配置core-site.xml文件内容如下:
fs.defaultFS
hdfs://xiamu01:9000
hadoop.tmp.dir
file:/usr/local/Hadoop-2.6.4/tmp
Abase forother temporary directories.
配置hdfs-site.xml文件内容如下:
dfs.namenode.secondary.http-address
xiamu01:50090
dfs.replication
1
dfs.namenode.name.dir
file:/usr/local/Hadoop-2.6.4/tmp/dfs/name
dfs.datanode.data.dir
file:/usr/local/Hadoop-2.6.4/tmp/dfs/data
配置mapred-site.xml文件内容如下:
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
xiamu01:10020
mapreduce.jobhistory.webapp.address
xiamu01:19888
配置yarn-site.xml文件内容如下:
yarn.resourcemanager.hostname
xiamu01
yarn.nodemanager.aux-services
mapreduce_shuffle
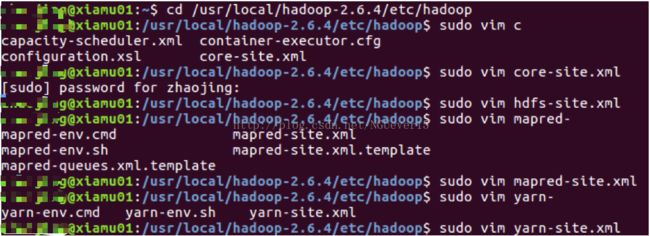
配置好后,将 Master 上的 /usr/local/Hadoop 文件夹复制到各个节点上。因为之前有跑过伪分布式模式,建议在切换到集群模式前先删除之前的临时文件。在 Master 节点上执行:
cd /usr/local
sudo rm -r./hadoop/tmp # 删除 Hadoop 临时文件
sudo rm -r./hadoop/logs/* # 删除日志文件
tar -zcf~/hadoop.master.tar.gz ./hadoop # 先压缩再复制
cd ~
scp./hadoop.master.tar.gz Slave1:/home/Hadoop
在slave上执行:
sudo rm -r/usr/local/hadoop # 删掉旧的(如果存在)
sudo tar -zxf~/hadoop.master.tar.gz -C /usr/local
sudo chown -Rhadoop /usr/local/Hadoop
首次启动需要先在 Master 节点执行 NameNode 的格式化:
hdfs namenode–format
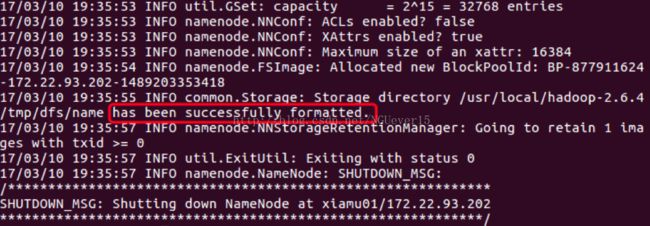
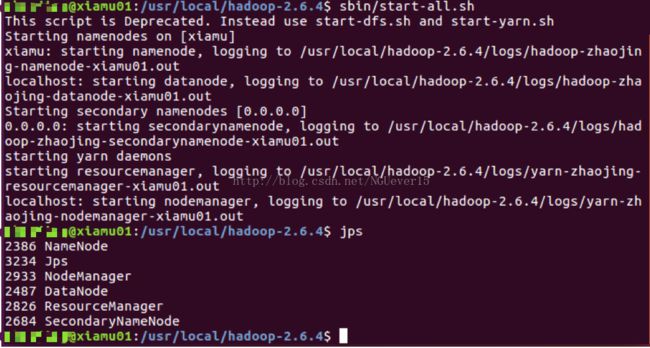
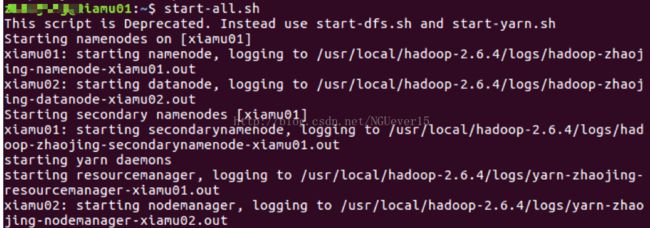
接着可以启动 hadoop 了,启动需要在 Master 节点上进行:
start-all.sh
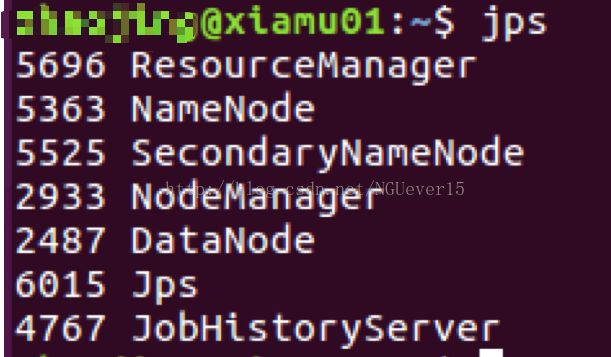
通过命令 jps 可以查看各个节点所启动的进程。在 Master 节点上可以看到 NameNode、ResourceManager、SecondrryNameNode、JobHistoryServer 进程,如下图所示:
在 Slave 节点可以看到 DataNode 和 NodeManager 进程,如下图所示
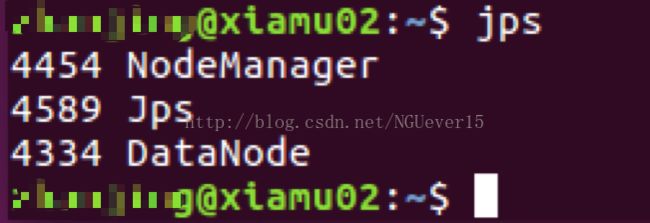
由此,hadoop分布式配置完毕。
2、ubuntu环境下eclipse的安装以及hadoop插件的配置
下载hadoop-eclipse-plugin-2.6.4.jar插件,并放到eclipse/p lugins下
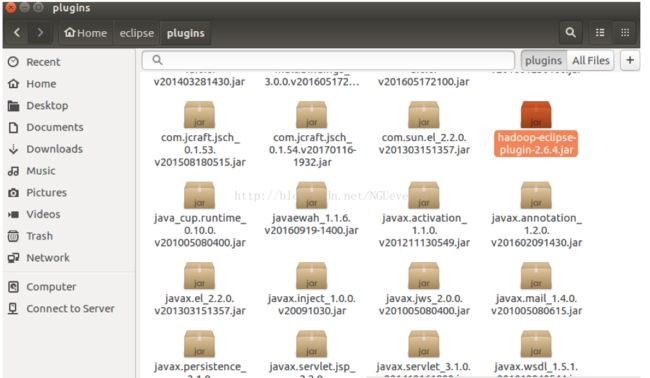
重启eclipse
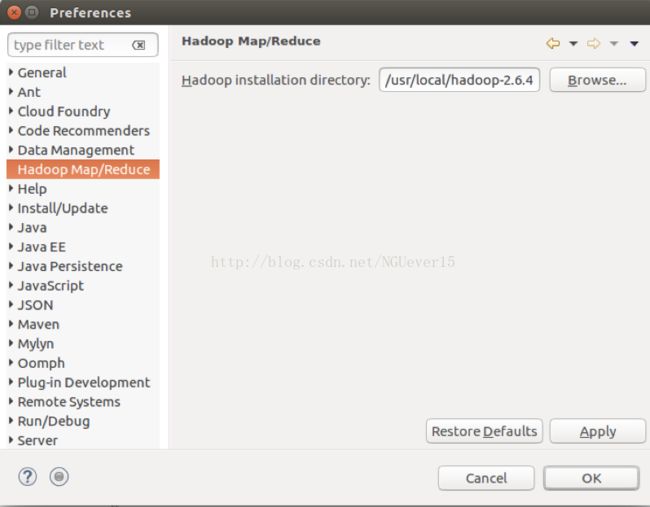
在eclipse菜单中window下选择preferences,选择hadoop map/reduce 将hadoop的安装目录填写到文本框或者点击browser寻找用户名下hadoop的文件,选中并确定。
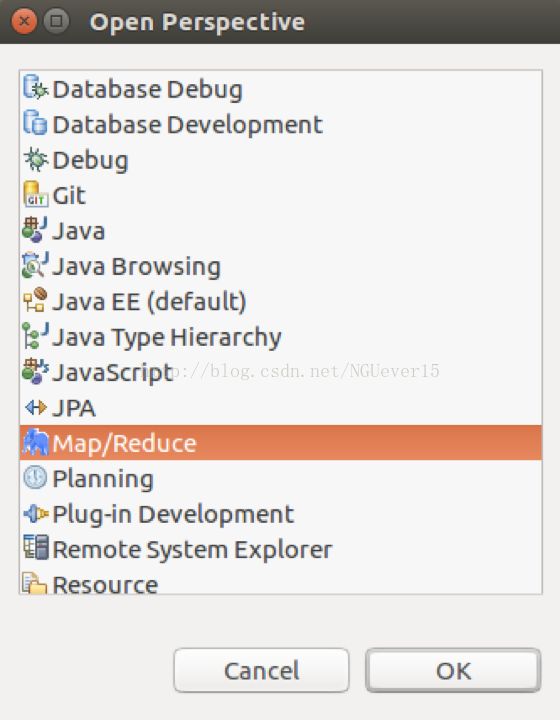
在window菜单下选择open perspective,选中map/reduce,并确定。
在window菜单下选择show view,并选中map/reduse tools中的map/reduce locations,然后确定。
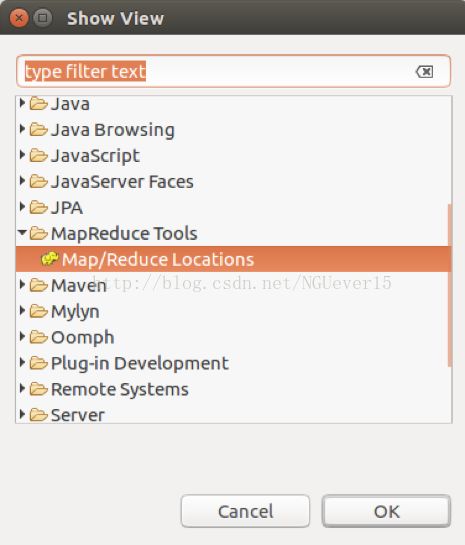
右击map/reducelocations窗体选择new Hadoop location,在弹出的对话框中修改map/reduce master中的port为:9000;DFS master中的port为:9000,在location name起名为hadoop

3、进行MapReduce应用程序开发
在Eclipse中创建MapReduce项目
点击 File 菜单,选择 Map/Reduce Project。
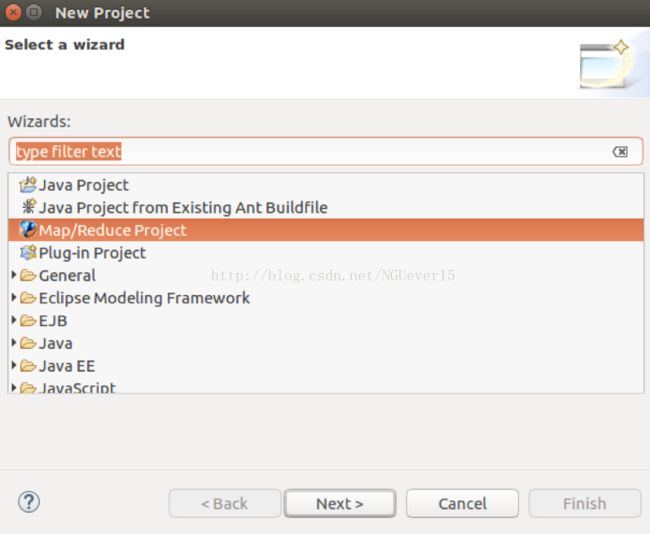
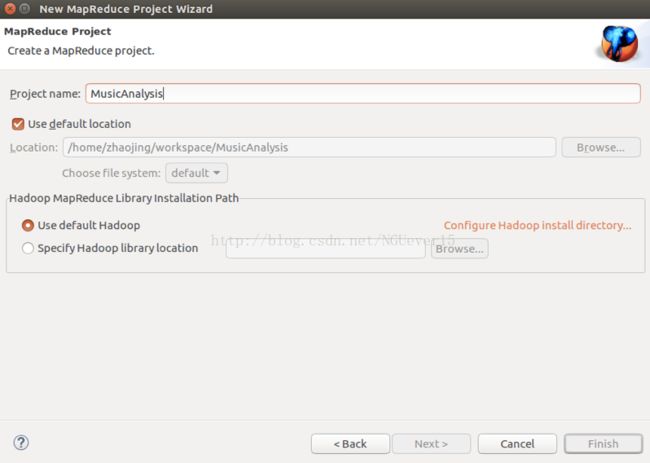
填写MapReduce 工程的名字为 MusicAnalysis。
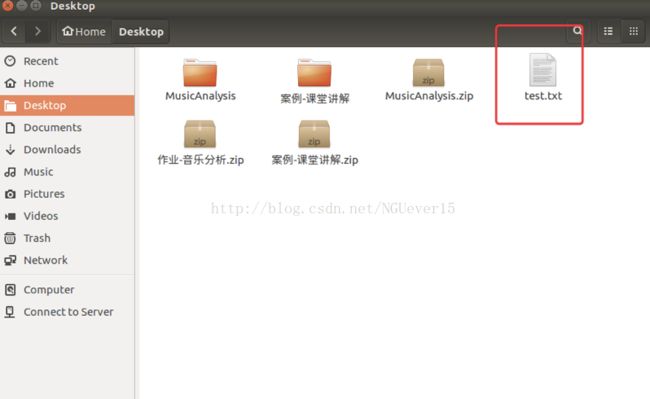
在桌面创建文件test.txt作为上传的目标文件。
通过下面的这段代码,实现文件上传
package hadoop.hdfs;
import java.io.File;
import java.io.IOException;
import java.net.URISyntaxException;
import java.security.InvalidKeyException;
import java.security.NoSuchAlgorithmException;
import javax.crypto.BadPaddingException;
import javax.crypto.IllegalBlockSizeException;
import javax.crypto.NoSuchPaddingException;
import org.apache.hadoop.fs.Path;
public class testHDFS {
@SuppressWarnings("static-access")
public static voidmain(String[] args) throws InvalidKeyException, NoSuchAlgorithmException,NoSuchPaddingException,
ClassNotFoundException,IllegalBlockSizeException, BadPaddingException, URISyntaxException, IOException{
File file = newFile("/home/username/Desktop/test.txt");
Path path = newPath("/user/username/input/test.txt");
new HDFS().upload(file,path);
}
}需要注意的是一下两行代码:
File file = new File("/home/username/Desktop/test.txt");
Path path = newPath("/user/username/input/test.txt");
new HDFS().upload(file,path);一定要保证两条路径的有效性。
编码完成后,在eclipse中点击run。
运行结束之后,可以在hadoop分布式文件系统上看到刚才上传的文件test.txt。表示文件上传成功。

音乐分析的实验代码如下:
package hadoop.hdfs;
import java.io.IOException;
import java.util.HashSet;
import java.util.Set;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
public class MA {
public static classListenMap extends Mapper {
IntWritable trackId = new IntWritable();
IntWritable userId = newIntWritable();
IntWritable count = newIntWritable();
public voidmap(LongWritable key, Text value, Context context) throws IOException,InterruptedException {
String[] parts = value.toString().split("[|]");
trackId.set(Integer.parseInt(parts[1]));
userId.set(Integer.parseInt(parts[0]));
count.set(1);
if (parts.length == 5){
context.write(trackId,count);// 相同用户的收听次数纳入计算
} else {}
}
}
public static class ListenReduceextends Reducer {
IntWritable result = newIntWritable();
public voidreduce(IntWritable trackId, Iterable userIds, Contextcontext)
throws IOException,InterruptedException {
SetuserIdSet = new HashSet();
@SuppressWarnings("unused")
int sum = 0;
for (IntWritable userId: userIds) {
userIdSet.add(userId.get());
sum++;
}
result.set(sum);
IntWritable size = new IntWritable(userIdSet.size());
context.write(trackId,result);
}
}
@SuppressWarnings("unused")
public static voidmain(String[] args) throws IllegalArgumentException, IOException,ClassNotFoundException, InterruptedException {
Configuration conf = newConfiguration();
Job job =Job.getInstance(conf, "Unique listeners per track");
job.setJarByClass(MA.class);
job.setMapperClass(ListenMap.class);
job.setReducerClass(ListenReduce.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job,new Path("/home/username/Desktop/test2.txt"));
FileOutputFormat.setOutputPath(job,new Path("/home/username/Desktop/result2"));
System.exit(job.waitForCompletion(true)? 0 : 1);
org.apache.hadoop.mapreduce.Counterscounters = job.getCounters();
}
} 
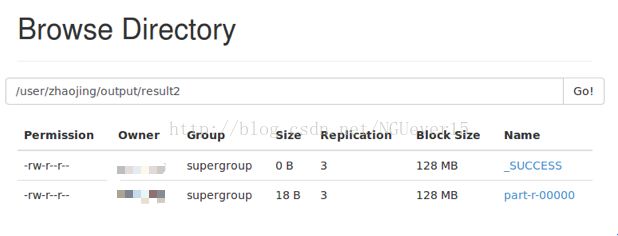
也可以将运行结果输出的文件上传到hadoop 分布式文件系统中。只需要将目的路径改为以下的路径即可。
hdfs://172.16.75.132:9000/user/username/output/result
运行之后可以在hadoop 分布式文件系统中看到输出的结果文件。

在上面的代码实现中,相同用户的收听次数纳入计算。下面我们改写代码实现相同用户的收听次数不纳入计算
package hadoop.hdfs;
import java.io.IOException;
import java.util.HashSet;
import java.util.Set;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
public class MA {
public static classListenMap extends Mapper {
IntWritable trackId = newIntWritable();
IntWritable userId = newIntWritable();
IntWritable count = newIntWritable();
public voidmap(LongWritable key, Text value, Context context) throws IOException,InterruptedException {
String[] parts =value.toString().split("[|]"); trackId.set(Integer.parseInt(parts[1]));
userId.set(Integer.parseInt(parts[0]));
count.set(1);
if (parts.length == 5){
context.write(trackId,userId); //相同用户的收听次数不纳入计算
} else {}
}
}
public static classListenReduce extends Reducer {
IntWritable result = newIntWritable();
public voidreduce(IntWritable trackId, Iterable userIds, Contextcontext)
throws IOException,InterruptedException {
SetuserIdSet = new HashSet();
@SuppressWarnings("unused")
int sum = 0;
for (IntWritable userId: userIds) {
userIdSet.add(userId.get());
}
result.set(sum);
IntWritable size = newIntWritable(userIdSet.size());
context.write(trackId, size);
}
}
@SuppressWarnings("unused")
public static voidmain(String[] args) throws IllegalArgumentException, IOException,ClassNotFoundException, InterruptedException {
Configuration conf = newConfiguration();
Job job = Job.getInstance(conf,"Unique listeners per track");
job.setJarByClass(MA.class);
job.setMapperClass(ListenMap.class);
job.setReducerClass(ListenReduce.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job,new Path("/home/username/Desktop/test2.txt"));
FileOutputFormat.setOutputPath(job,new Path("/home/username/Desktop/result2"));
System.exit(job.waitForCompletion(true)? 0 : 1);
org.apache.hadoop.mapreduce.Counterscounters = job.getCounters();
}
} 运行成功之后,可以在指定的本地路径查看输出的运行结果文件。
也可以将运行结果输出的文件上传到hadoop 分布式文件系统中。只需要将目的路径改为以下的路径即可。
hdfs://172.16.75.132:9000/user/username/output/result2
运行之后可以在hadoop 分布式文件系统中看到输出的结果文件。