论文浅尝 | Iterative Cross-Lingual Entity Alignment Based on TransC
论文笔记整理:谭亦鸣,东南大学博士。

来源:IEICE TRANSACTIONS on Information and Systems, 2020, 103(5): 1002-1005.
链接:
https://www.jstage.jst.go.jp/article/transinf/E103.D/5/E103.D_2019DAL0001/_pdf
介绍
这篇论文关注的任务是跨语言实体对齐,目标是将不同语言知识库中具有相同语义的实体相匹配。作者认为不同语言的知识图谱可能具备相同的本体划分,这一点对于实体对齐来说可能起到作用。(在作者的了解范围里,目前还没有实体对齐工作是基于本体信息的,但是多语言知识图谱如DBpedia,是先构建了统一的本体划分,然后再遵循这一划分构建各个语言版本的知识图谱,如下图)
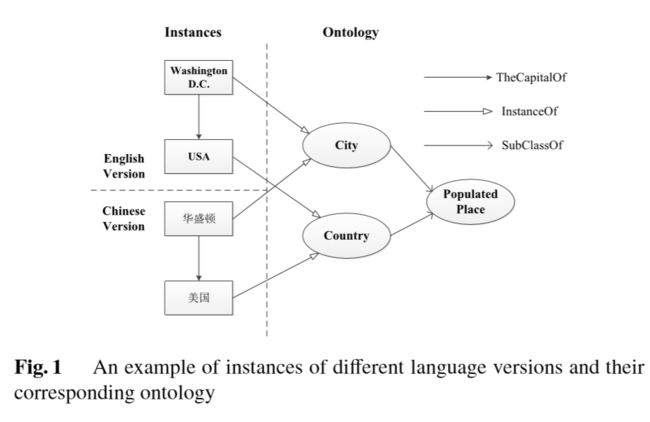
为了验证这一猜测,本文提出了一个基于TransC的embedding模型:首先由TransC以及参数共享模型将图谱中所有的实体和关系映射到一个共享的低维语义空间;之后模型迭代通过reinitalization以及soft alignment(软对齐)策略提升实体对齐的性能。
实验结果显示,相对于benchmark算法,本文方法可以有效的利用本体信息,从而得到更好的结果。
P.S. 需要说明的是,本文使用到的本体间关系只有“SubclassOf”这一个。
模型
模型整体可以分为三个部分:
a. Knowledge embedding part
首先是对实例的embedding:TransE被用于对三元组中的实体和关系进行embedding,投影到一个低维空间中
之后是对实体的InstanceOf三元组的embedding:这种三元组的构成为(实体,InstanceOf,实体对应的本体类型),TransC将每个类型对应的向量建模为一个球型空间s(p,m),其中p表示球心,m表示球的半径,对于一个InstanceOf三元组,其对应的energy function为:

其中e为e的向量表示。
整体三元组的得分计算为:

最后是SubClassOf triple embedding:这个部分主要是反应不同类型的本体之间的相对位置,因此计算的方式通过球形空间的相对位置来衡量,即:

b. Joint embedding part
本文使用的参数共享模型基于MTransE(IJCAI 2017)构成,其目的是基于ILLs(DBpedia提供的已知多语言实体对齐),将已知对齐实体embedding,在训练过程中强制对等。
c. Alignment part
为了弥补标注数据(已知对齐)的不足,这一步的普遍方案是使用训练得到的模型对未标注数据进行对齐标注,然后使用新的标注数据作为训练集迭代的更新模型,但是这种过程必然引入错误对齐。作者提出了两个策略处理这个问题:
1)Reinitialization
在每轮迭代中,首先训练multilingual knowledge embedding直至验证集上的效果边差,而后对于那些embedding相似性高于预设阈值的实体对,将具有最高相似性的样本选入ILLs,构成新的标注集。之后对knowledge做重新初始化,并且开始新的迭代训练。
2)Soft Alignment
3)对于更新的标注集中的实体对,这里参照Soft Alignmen(IJCAI 2017)定义的得分函数:
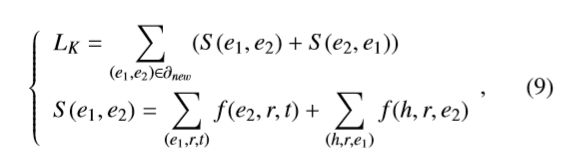
对于不同语言的KG1和KG2,更新的标注集不会被用于参数共享模型,而是仅仅用于对齐训练
实验
实验数据:
作者基于DBpedia构建了一个多语言知识图谱,包含英-法以及英-德两种语言对。
其构建过程为:首先随机的从ILLs中抽取1000个实体对,而后利用这些实体对在ILLs中找到其他包含对齐实体的三元组(但是不在1000样本中,例如A-B对齐,借助ILLs找到(A, r1, C),(B, r2, D),其中,C和D在ILLs中是对齐实体,这些将被用于测试模型的对齐性能)
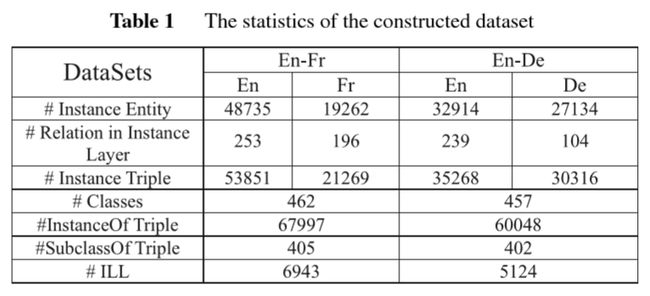
数据集的统计信息如下表所示
实验结果:
跨语言实体对齐实验结果如下表,其中Ps-TransC(RE+SA)是本文方法,其他Ps为本文方法的变体,作为对照组,参考的其他方法为LM(Linear Mapping)以及MTransE。

OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。