python3.6+pyspider实现知乎和v2ex的爬取
PySpider:一个国人编写的强大的网络爬虫系统并带有强大的WebUI。采用Python语言编写,分布式架构,支持多种数据库后端,强大的WebUI支持脚本编辑器,任务监视器,项目管理器以及结果查看器。
条件:安装PySpider和pyMySQL
直接pip3 install 安装即可
然后启动PySpider的话在cmd中直接输入PySpider启动即可
默认的是在127.0.0.1:5000打开,当然也可以自己定义参数,看官方网站即可
http://docs.pyspider.org/en/latest/

你看到的界面可能和我的不一样,因为我的自定义了启动参数
然后就是在PySpider中创建项目,创建完成后,他会辅助你创建基本的框架
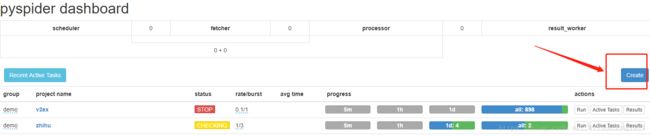
最后就是实现了
其实爬取的过程就是页面解析然后一层一层的解析,知道找到你需要的东西
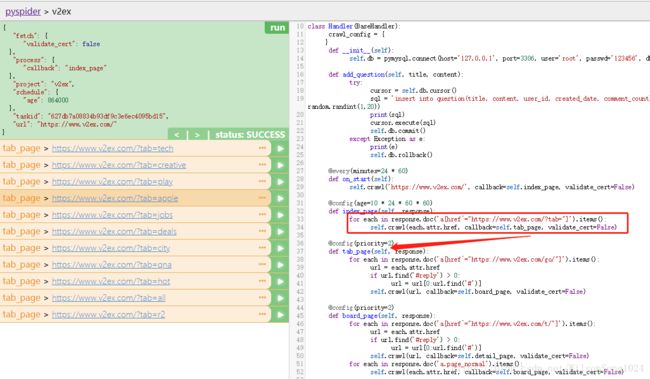
首先执行

第二层
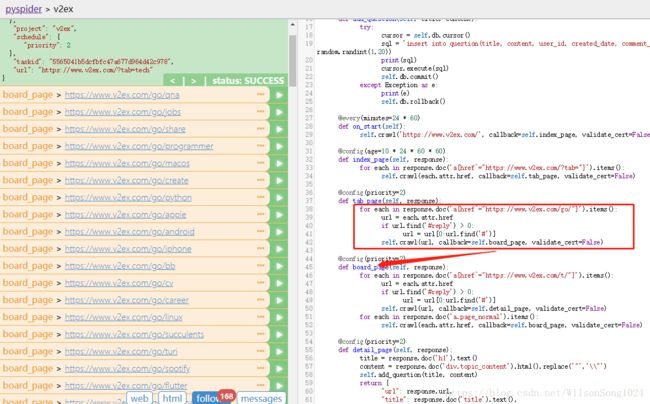
第三层
第四层
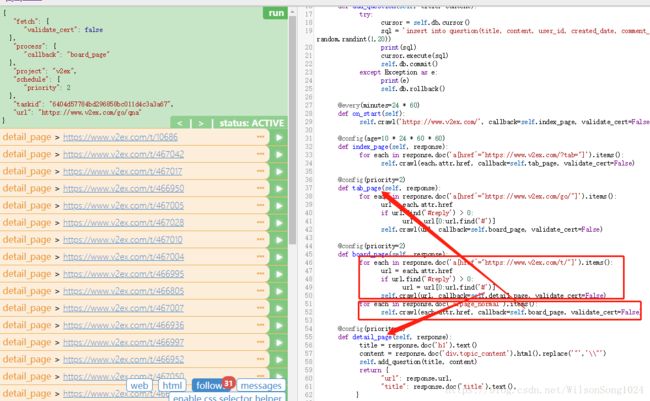
最后解析到我们所需要的页面,找到要爬出的内容,然后解析
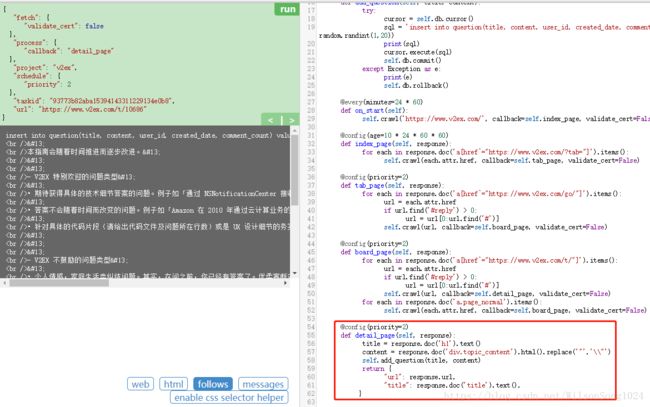
这里的爬虫是解析页面的时候用了CSS选择器,关于CSS选择器可以参考官网,也可以参考这里
http://www.w3school.com.cn/cssref/css_selectors.asp
最后就是整个的代码
其中有一部分是插入数据库的,数据库表的字段根据自己需要进行设计
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2018-06-27 20:17:10
# Project: v2ex
from pyspider.libs.base_handler import *
import random
import pymysql
class Handler(BaseHandler):
crawl_config = {
}
def __init__(self):
self.db = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123456', db='wenda', charset='utf8')
def add_question(self, title, content):
try:
cursor = self.db.cursor()
sql = 'insert into question(title, content, user_id, created_date, comment_count) values("%s", "%s", %d, now(), 0)' %(title, content, random.randint(1,20))
print(sql)
cursor.execute(sql)
self.db.commit()
except Exception as e:
print(e)
self.db.rollback()
@every(minutes=24 * 60)
def on_start(self):
self.crawl('https://www.v2ex.com/', callback=self.index_page, validate_cert=False)
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('a[href^="https://www.v2ex.com/?tab="]').items():
self.crawl(each.attr.href, callback=self.tab_page, validate_cert=False)
@config(priority=2)
def tab_page(self, response):
for each in response.doc('a[href^="https://www.v2ex.com/go/"]').items():
url = each.attr.href
if url.find('#reply') > 0:
url = url[0:url.find('#')]
self.crawl(url, callback=self.board_page, validate_cert=False)
@config(priority=2)
def board_page(self, response):
for each in response.doc('a[href^="https://www.v2ex.com/t/"]').items():
url = each.attr.href
if url.find('#reply') > 0:
url = url[0:url.find('#')]
self.crawl(url, callback=self.detail_page, validate_cert=False)
for each in response.doc('a.page_normal').items():
self.crawl(each.attr.href, callback=self.board_page, validate_cert=False)
@config(priority=2)
def detail_page(self, response):
title = response.doc('h1').text()
content = response.doc('div.topic_content').html().replace('"','\\"')
self.add_question(title, content)
return {
"url": response.url,
"title": response.doc('title').text(),
}爬取知乎
说实话知乎的爬取难度大好多,但是和上述流程差不多
可以参考下面,每有些彻底完成,知乎现在是动态页面,
具体自行完善的时候可以参考下面博客:
https://blog.csdn.net/qq_30242609/article/details/53925298
然后我自己,先写到这,以后慢慢完善
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2018-06-27 21:33:12
# Project: zhihu
from pyspider.libs.base_handler import *
class Handler(BaseHandler):
crawl_config = {
'itag': 'v1',
'headers': {
'User-Agent': 'GoogleBot',
'Host' : 'www.zhihu.com',
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
}
}
@every(minutes=24 * 60)
def on_start(self):
self.crawl('https://www.zhihu.com/topic/19562940/top-answers', callback=self.index_page, validate_cert=False)
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('h2.ContentItem-title>div>a[target=_blank]').items():
self.crawl(each.attr.href, callback=self.detail_page, validate_cert=False)
@config(priority=2)
def detail_page(self, response):
items = response.doc('div.RichContent.RichContent--unescapable').items()
title = response.doc('h1.QuestionHeader-title').text()
html = response.doc('div.QuestionHeader-detail>div.QuestionRichText.QuestionRichText--collapsed').html()
if html == None:
html = ''
content = html.replace('"','\\"')
print(html)
return {
"url": response.url,
"title": response.doc('title').text(),
}