Redis
Redis
文章目录
- Redis
- 一.NoSQL数据库
- (一)产生Redis 命令背景
- (二)NoSQL数据库简介
- 二.Redis基本介绍
- (一)Redis的特性
- (二)redis的适用场景
- 三.Redis数据类型与命名
- (一)Redis中的数据类型
- (二)Redis 操作命令(熟悉)
- 四Redis的javaAPI操作
- (一)String字符串操作
- (二)Hash列表操作
- (三)List集合操作
- (四)Set集合操作
- 五.Redis的持久化
- (一)RDB方案(默认)
- (二)RDB方案
- (三)Redis缓存击穿★★
- (四)Redis缓存雪崩★★
- 六.Redis的四种架构
- (一)单机版本
- (二)Replication架构
- (三)Sentinel模式
- (四)Redis集群模式
一.NoSQL数据库
(一)产生Redis 命令背景
随着Web2.0的时代的到来,用户访问量大幅度提升,同时产生了大量的用户数据。加上后来的智能移动设备的普及,所有的互联网平台都面临了巨大的性能挑战。包括web服务器CPU及内存压力,数据库服务器IO压力等。
关于如何解决Web服务器的负载压力,其中最常用的一种方式就是使用nginx实现web集群的服务转发以及服务拆分等等。但是这样也会存在问题,后端服务器的多个tomcat之间如何解决session共享的问题,以及session存放的问题等等。
为了解决session存放的问题,也有多种解决方案
-
方案一:存放在cookie里面。不安全,否定
-
方案二:存放在文件或者数据库当中。速度慢
-
方案三:session复制。大量session冗余,节点浪费大
-
方案四:使用NoSQL缓存数据库。例如redis或者memcache等,完美解决
(二)NoSQL数据库简介
NoSQL,泛指非关系型的数据库。随着互联网web2.0网站的兴起,传统的关系数据库在应付web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题。
1.NoSQL的适应场景
-
对数据高并发的读写
-
海量数据的读写
-
对数据高可扩展性的
-
速度够快,能够快速的存取数据
2.NoSQL不适用场景
-
需要事务支持
-
基于sql的结构化查询存储,处理复杂的关系,需要即席查询(用户自定义查询条件的查询)。
3.Nosql数据库的简介
- Memcache:基本上很少人用了。
- Redis:覆盖memcache的所有的功能,基本上替代了memcache,可以快速的存取数据,所有的数据都是在内存当中,存放数据量的大小,取决于内存大小。
- MongoDB:nosql数据库,数据主要是存储在内存当中,如果内存不够,数据可以落地到磁盘里面去,而且MongoDB支持sql语句的查询,是最像关系型数据库的非关系型数据库。
- Hbase:列式数据库存储,可以有上亿条数据,可以有上百万列等等都可以做到轻松的数据的查询,是大数据领域里面一个非常重要的非关系型数据库,原型是2006年Google发表BigTable论文。
二.Redis基本介绍
(一)Redis的特性
- 高效性:Redis读取的速度是110000次/S,写的速度是81000次/S。
- 原子性:对每一条数据操作要么成功,要么失败。
- 支持多种数据结构:string(字符串);list(列表);hash(哈希),set(集合);zset(有序集合)。
- 稳定性:redis支持各种架构,主从复制,哨兵模式,redis集群。
- 其他特性:支持过期时间,支持事务,消息订阅。
(二)redis的适用场景
- 获取最新的N个数据
- 获取最新榜单的topN
- 需要精确设置过期时间的应用 可对数据设置过期的时间,多长时间之后,数据就会自动删除掉
- 计数器的应用:利用INCR,DECR命令来构建计数器系统,数据来一次就累加一次
- 数据去重(Uniq操作):可以对数据进行去重操作
- 实时系统:Pub/Sub系统可以构建实时的消息系统
- 构建消息队列:你发送一个消息,我来接受这个消息即可
- 构建队列系统:通过redis来构建先进先出的数据的队列
- 数据缓存:将一些比较频繁使用的热数据 缓存到内存里面去
三.Redis数据类型与命名
(一)Redis中的数据类型
- string 字符串,类似于Java的字符串,同时支持数值类型的操作。
- list 列表类似于 ArrayList 。
- hash 类似于HashMap 类似于hash散列表,对应key,value对的数据类型。
- set 类似于hashSet 对数据进行去重,不会对数据进行排序操作。
- zset 类似于 linkedHashSet 对数据进行排序操作。
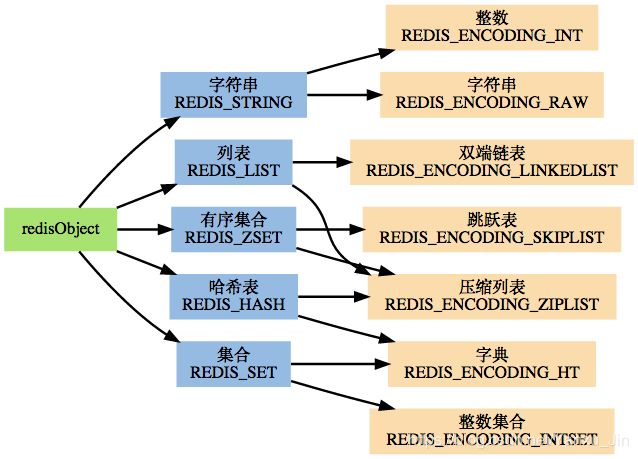
(二)Redis 操作命令(熟悉)
启动并进入Redis客户端:
#node01启动Redis
cd /export/servers/redis-3.2.8
src/redis-server redis.conf
#连接并进入Redis客户端
cd /export/servers/redis-3.2.8
src/redis-cli -h node01
Redis的对Key和对几种数据类型的操作请参阅以下网址:
https://www.runoob.com/redis/redis-intro.html
四Redis的javaAPI操作
创建Maven工程
<dependencies>
<dependency>
<groupId>redis.clientsgroupId>
<artifactId>jedisartifactId>
<version>2.9.0version>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-compiler-pluginartifactId>
<version>3.0version>
<configuration>
<source>1.8source>
<target>1.8target>
<encoding>UTF-8encoding>
configuration>
plugin>
plugins>
build>
编写RedisJDBC工具类
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
public class Redis_JDBC_Utils {
//工作当中,数据库连接池对象,一般都是写成单例对象
private static JedisPool jedisPool;
public static Jedis getJedis(){
//获取redis的数据库连接池对象
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
jedisPoolConfig.setMaxWaitMillis(3000);//获取一个客户端的连接最大等待时间3s
jedisPoolConfig.setMinIdle(10);//设置客户端连接数最小空闲数
jedisPoolConfig.setMaxIdle(20);//设置客户端连接数最大空闲数
jedisPoolConfig.setMaxTotal(50); //设置客户端最大连接数为50 个
jedisPool = new JedisPool(jedisPoolConfig, "node01", 6379);
return jedisPool.getResource();
}
}
(一)String字符串操作
import cn.com.vivo.utils.Redis_JDBC_Utils;
import redis.clients.jedis.Jedis;
//String字符串的操作
public class JedisStrOperate {
public static void main(String[] args) {
//获取客户端操作对象
Jedis jedis = Redis_JDBC_Utils.getJedis();
//设置指定 key 的值
jedis.set("hello2","1");
//获取指定 key 的值
String rs1 = jedis.get("hello2");
//设置数据的key过期时间: 3秒
jedis.setex("hello",3,"world2");
//将数据往上累加1
jedis.incr("hello2");//当前结果为 2
jedis.incrBy("hello2",2);//当前结果为 4
//将数据值减1
jedis.decr("hello2");//当前结果为 3
jedis.decrBy("hellow",2);//当前结果为 1
String rs2 = jedis.get("hello2");
System.out.println("hello2_rs1: "+rs1);
System.out.println("hello2_rs2: "+rs2);
//将客户端连接对象还回到连接池里面去
jedis.close();
}
}
(二)Hash列表操作
import cn.com.vivo.utils.Redis_JDBC_Utils;
import redis.clients.jedis.Jedis;
import java.util.List;
import java.util.Set;
public class JedisHashOperate {
public static void main(String[] args) {
//获取客户端操作对象
Jedis jedis = Redis_JDBC_Utils.getJedis();
//设置值
jedis.hset("hset1","field1","value1");
jedis.hset("hset1","field2","value2");
jedis.hset("hset1","field3","value3");
//获取field的值
String rs = jedis.hget("hset1", "field1");//获取1个字段的值
System.out.println(rs);
//获取key的所有的field值
Set<String> rs_fields = jedis.hkeys("hset1");//获取所有fields的值
for (String s : rs_fields) {
System.out.println(s);
}
//删除某一个字段值
Long hdel = jedis.hdel("hset1", "field1");
//获取所有的value值
List<String> rs_values = jedis.hvals("hset1");
for (String s : rs_values) {
System.out.println(s);
}
//将客户端连接对象还回到连接池里面去
jedis.close();
}
}
(三)List集合操作
import cn.com.vivo.utils.Redis_JDBC_Utils;
import redis.clients.jedis.Jedis;
import java.util.List;
public class JedisListOperate {
public static void main(String[] args) {
//获取客户端操作对象
Jedis jedis = Redis_JDBC_Utils.getJedis();
jedis.del("list","list1");
//从左边进行插入数据
jedis.lpush("list", "value1", "value2", "value2");
//从右边进行插入数据
jedis.rpush("list", "value3", "value4", "value5");
//获取list集合中的所有值
List<String> rsList = jedis.lrange("list", 0, -1);
System.out.println(rsList);
//从左边弹出数据
String rs_left = jedis.lpop("list");
System.out.println("左边弹出的结果为: "+rs_left);
//从右边弹出数据
String rs_right = jedis.rpop("list");
System.out.println("右边弹出的结果为: "+rs_right);
System.out.println("弹出操作会删除list中的元素: "+ jedis.lrange("list",0,-1));
/*移出并获取列表的第一个元素, 如果列表没有元素会阻塞列表的其他操作
直到等待超时或发现可弹出元素为止。*/
List<String> rs = jedis.blpop(3,"list1");//单位秒
System.out.println("阻塞队列操作"+rs);
//移除列表的最后一个元素,并将该元素添加到另一个列表并返回
String rpoplpush = jedis.rpoplpush("list", "list1");
System.out.println("list1列表:"+jedis.lrange("list1",0,-1));
//将客户端连接对象还回到连接池里面去
jedis.close();
}
}
(四)Set集合操作
import cn.com.vivo.utils.Redis_JDBC_Utils;
import redis.clients.jedis.Jedis;
import java.util.Set;
public class JedisSetOperate {
public static void main(String[] args) {
//获取客户端操作对象
Jedis jedis = Redis_JDBC_Utils.getJedis();
jedis.del("set1","set2");
//set集合添加值, 可去重
jedis.sadd("set1","小明","小明","小红","小华");
//获取set集合的值
Set<String> set1 = jedis.smembers("set1");
System.out.println(set1);
//求两集合的差集(set1减去与set2中相同的元素)
jedis.sadd("set2","小华","小李");
Set<String> set_diff = jedis.sdiff("set1", "set2");
System.out.println("两集合的差集为: "+set_diff);
//求两集合的并集
jedis.sadd("set2","小华","小李");
Set<String> set_union = jedis.sunion("set1", "set2");
System.out.println("两集合的并集为: "+set_union);
//set集合当中元素移动
jedis.smove("set1", "set2", "小明");
System.out.println("set1移出'小明'元素后"+jedis.smembers("set1"));
System.out.println("set2移入'小明'元素后"+jedis.smembers("set2"));
//将客户端连接对象还回到连接池里面去
jedis.close();
}
}
五.Redis的持久化
由于redis是一个内存数据库,所有的数据都是保存在内存当中的,内存当中的数据极易丢失,所以redis的数据持久化就显得尤为重要。在redis当中,提供了两种数据持久化的方式,分别为RDB以及AOF,且redis默认开启的数据持久化方式为RDB方式,接下来我们就分别来看下两种方式的配置吧。
(一)RDB方案(默认)
Redis会定期保存数据快照至一个rbd文件中,并在启动时自动加载rdb文件,恢复之前保存的数据。可以在redis.conf配置文件中配置Redis进行快照保存的时机。
格式: save [seconds] [changes] 可配置多条
例如: save 60 100
含义: 在60秒内如果发生了100次数据修改,则进行一次RDB快照保存
RDB方案优点:
- 对性能影响最小。Redis在保存RDB快照时会fork出子进程进行,几乎不影响Redis处理客户端请求的效率。(fock 分叉)
- 可靠性高。每次快照会生成一个完整的数据快照文件,所以可以辅以其他手段保存多个时间点的快照,可作为非常可靠的灾难恢复手段。
- 数据恢复比AOF快。
RDB方案缺点:
- 快照是定期生成的,所以在Redis crash时或多或少会丢失一部分数据。
- 如果数据集非常大且CPU不够强(比如单核CPU),Redis在fork子进程时可能会消耗相对较长的时间,影响Redis对外提供服务的能力。
(二)RDB方案
采用AOF持久方式时,Redis会把每一个写请求都记录在一个日志文件里。在Redis重启时,会把AOF文件中记录的所有写操作顺序执行一遍,确保数据恢复到最新。AOF默认是关闭的,如要开启,需要在redis.conf中配置。
AOF提供了三种fsync(异步)配置:
首先要配置使用AOF功能: appendonly yes,然后选下面三个配置中的一种。
appendfsync no:不进行fsync,将flush文件的时机交给OS(操作系统)决定,速度最快
appendfsync always:每写入一条日志就进行一次fsync操作,数据安全性最高,但速度最慢
appendfsync everysec:折中的做法,交由后台线程每秒fsync一次,实际生产中常用用
AOF Rewrite功能:
因为所有的操作都会记录,必定会出现一些无用的日志,这会让AOF文件过大,也会让数据恢复的时间过长。因此,Redis提供了AOF rewrite功能,可以重写AOF文件,只保留能够把数据恢复到最新状态的最小写操作集。可以在redis.conf配置定期自动进行:
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
上面两行配置的含义是:Redis在每次AOF rewrite时,会记录完成rewrite后的AOF日志大小,当AOF日志大小在该基础上增长了100%后,自动进行AOF rewrite。同时如果增长的大小没有达到64mb,则不会进行rewrite。
AOF优点:
- 最安全。在启用appendfsync always时,任何已写入的数据都不会丢失,使用在启用appendfsync everysec也至多只会丢失1秒的数据。AOF文件在发生断电等问题时也不会损坏,即使出现了某条日志只写入了一半的情况,也可以使用redis-check-aof工具轻松修复。
- 易读,可修改。在进行了某些错误的数据清除操作后,只要AOF文件没有rewrite,就可以把AOF文件备份出来,把错误的命令删除,然后恢复数据。
AOF的缺点:
- AOF文件通常比RDB文件更大。
- 性能消耗比RDB高,每一次AOF Rewrite都需要Redis主进程进行fork操作。
- 数据恢复速度比RDB慢。
(三)Redis缓存击穿★★
缓存击穿,是指用户请求的Key的数据不在Redis的缓存当中,最终只能去后端的数据库中查找请求的数据。当这种请求特别多是会对后端数据库造成很大的压力。产生的原因可能是我们设置的Key不合理,没有将所有的热点Key缓存到Redis当中来。我们可以使用Redis计数器,每次查询数据的Key都可以通过计数器来记录,判断哪些数据是热点Key数据,保存到Redis里面去。
(四)Redis缓存雪崩★★
缓存雪崩一般是由于Redis突然宕机了,所有的缓存数据全部失效,用户所有的查询请求只能由后端的数据库中来执行。我们可以通过改进Redis的架构来解决,见下一章。
六.Redis的四种架构
(一)单机版本
仅使用一台服务器,直接安装一个Redis就可以了。通过持久化功能,Redis保证了即使在服务器重启的情况下也不会损失(或少量损失)数据,因为持久化会把内存中数据保存到硬盘上,重启会从硬盘上加载数据。 但是由于数据是存储在一台服务器上的,如果这台服务器出现硬盘故障等问题,也会导致数据丢失。
(二)Replication架构
Replication(主从复制)架构避免了单点故障导致数据丢失的问题,通过执行SLAVEOF命令或者设置slaveof选项,让一个服务器去复制(replicate)另一个服务器中的数据,我们称被复制的服务器为主服务器(master),而对主服务器进行复制的服务器则被称为从服务器(slave)。主从复制架构的主节点(master)支持读写操作,从节点(slave)只支持读取操作,主从复制架构不具备自动容错和恢复功能,主机从机的宕机都会导致前端部分读写请求失败,需要等待机器重启或者手动切换前端的IP才能恢复。
(三)Sentinel模式
Sentinel(哨兵)是Redis 的高可用性解决方案:由一个或多个Sentinel 实例 组成的Sentinel 系统可以监视任意多个主服务器,以及这些主服务器属下的所有从服务器,并在被监视的主服务器进入下线状态时,自动将下线主服务器属下的某个从服务器升级为新的主服务器。

一台主节点,多台从节点,但是启动哨兵监控程序,可以监控主节点宕机问题,实现主节点故障自动转移。
(四)Redis集群模式
以上三种模式都没有实现Redis的横向扩展的问题。
Redis集群专门用于解决redis横向扩展的问题。数据可以在多个Redis节点间自动分配的。Redis集群并不支持同时处理多个键的 Redis 命令,因为这需要在多个节点间移动数据,会降低redis集群的性能,在高负载的情况下可能会导致不可预料的错误。Redis集群在分区期间也能提供一定程度的可用性,即当某些节点发生故障或无法通信时,集群能够继续运行。

Redis 集群的优势:
- Redis可以使用所有机器的内存,变相扩展性能;
- 缓存永不宕机:启动集群,永远让集群的一部分起作用。主节点失效了子节点能迅速改变角色成为主节点,整个集群的部分节点发生故障或无法通信的情况下能够继续处理命令;
- 使Redis的计算能力通过简单地增加服务器得到成倍提升,Redis的网络带宽也会随着计算机和网卡的增加而成倍增长;
- Redis集群没有中心节点,不会因为某个节点成为整个集群的性能瓶颈;异步处理数据,实现快速读写。
- 异步处理数据,实现快速读写。