使用JXL分析excel&&调用JAVA爬虫调取搜狗搜索结果数
package com.company;
import jxl.Cell;
import jxl.Workbook;
import jxl.read.biff.BiffException;
import jxl.write.Label;
import jxl.write.WritableSheet;
import jxl.write.WritableWorkbook;
import jxl.write.WriteException;
import jxl.write.biff.RowsExceededException;
import java.io.File;
import java.io.IOException;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Main {
public static void main(String[] args)throws BiffException, IOException, RowsExceededException, WriteException {
WritableWorkbook book;
try {
//获得文件
Workbook wb = Workbook.getWorkbook(new File("C:\\Users\\86189\\Desktop\\学术\\研一下课程\\周三晚上协同社会服务\\scholat_news.xls"));
//打开一个文件的副本,并且指定数据写回到原文件
book = Workbook.createWorkbook(new File ("C:\\Users\\86189\\Desktop\\学术\\研一下课程\\周三晚上协同社会服务\\scholat_news02.xls"), wb);
//获取一个工作表
WritableSheet sheet = book.getSheet(0);
/**
* 查询两人表中数据
*/
double pagerank=excelRequest("汤庸",sheet,8);
sheet.addCell(new Label(15,8,""+pagerank));//c是列r是行
double pagerank2=excelRequest("赵淦森",sheet,9);
sheet.addCell(new Label(15,9,""+pagerank2));//c是列r是行
double pagerank3=excelRequest("李建国",sheet,10);
sheet.addCell(new Label(15,10,""+pagerank3));//c是列r是行
double pagerank4=excelRequest("汤娜",sheet,11);
sheet.addCell(new Label(15,11,""+pagerank4));//c是列r是行
/**
* 查询两人搜狗结果数据
* */
String Tang="https://www.sogou.com/web?query=%E6%B1%A4%E5%BA%B8+%E5%8D%8E%E5%8D%97%E5%B8%88%E8%8C%83%E5%A4%A7%E5%AD%A6&_ast=1586506871&_asf=www.sogou.com&w=01029901&p=40040100&dp=1&cid=&s_from=result_up&sut=2785&sst0=1586506875655&lkt=0%2C0%2C0&sugsuv=00858BAD78ECA3655DC119BEA4265116&sugtime=1586506875655";
String Zhao="https://www.sogou.com/web?query=%E8%B5%B5%E6%B7%A6%E6%A3%AE+%E5%8D%8E%E5%8D%97%E5%B8%88%E8%8C%83%E5%A4%A7%E5%AD%A6&_ast=1586506886&_asf=www.sogou.com&w=01029901&p=40040100&dp=1&cid=&s_from=result_up&sut=2986&sst0=1586506893266&lkt=0%2C0%2C0&sugsuv=00858BAD78ECA3655DC119BEA4265116&sugtime=1586506893266";
String info1 = getSouGouInfo(Tang);
System.out.println(info1);
String info2 = getSouGouInfo(Zhao);
System.out.println(info2);
//只提取结果的数字部分
String regEx="[^0-9]";
Pattern p = Pattern.compile(regEx);
Matcher m1 = p.matcher(info1);
Matcher m2 = p.matcher(info2);
System.out.println( m1.replaceAll("").trim());
System.out.println( m2.replaceAll("").trim());
/*
* 将结果打印至表中search列
* */
int tangHeat=Integer.valueOf(m1.replaceAll("").trim()).intValue();
int zhaoHeat=Integer.valueOf(m2.replaceAll("").trim()).intValue();
sheet.addCell(new Label(16,8,""+m1.replaceAll("").trim()));//c是列r是行
sheet.addCell(new Label(16,9,""+m2.replaceAll("").trim()));//c是列r是行
/*
* 将带有结果的热度打印至表中heat(witchSearch)列
* */
pagerank= (Math.sqrt(tangHeat)+pagerank);
pagerank2= (Math.sqrt(zhaoHeat)+pagerank2);
sheet.addCell(new Label(17,8,""+pagerank));//c是列r是行
sheet.addCell(new Label(17,9,""+pagerank2));//c是列r是行
book.write();
book.close();
} catch (IOException e) {
System.out.println(e);
}
}
/*
* 自动查询Excel内部数据
* */
private static double excelRequest(String P ,WritableSheet sheet,int crow) throws WriteException {
int k1a=0,k1b=0,k2a=0,k2b=0,k3a=0,k3b=0,k4a=0,k4b=0,k5a=0,k5b=0,k6a=0,k6b=0;
String r1,r2,r3,r4,r5,r6;
String c1,c2,c3,c4,c5,c6;
for (int i = 1; i <9110; i++) {
Cell[] cell=sheet.getRow(i);
r1=cell[1].getContents();
r2=cell[2].getContents();
c1=cell[4].getContents();
if(c1.contains("1")==true){
if(r1.contains(P)==true){
k1a++;
}
if(r2.contains(P)==true){
k1b++;
}
}
if(c1.contains("2")==true){
if(r1.contains(P)==true){
k2a++;
}
if(r2.contains(P)==true){
k2b++;
}
}
if(c1.contains("3")==true){
if(r1.contains(P)==true){
k3a++;
}
if(r2.contains(P)==true){
k3b++;
}
}
if(c1.contains("4")==true){
if(r1.contains(P)==true){
k4a++;
}
if(r2.contains(P)==true){
k4b++;
}
}
if(c1.contains("5")==true){
if(r1.contains(P)==true){
k5a++;
}
if(r2.contains(P)==true){
k5b++;
}
}
if(c1.contains("6")==true){
if(r1.contains(P)==true){
k6a++;
}
if(r2.contains(P)==true){
k6b++;
}
}
}
/* r1=sheet.getCell(8,9).getContents();*/
sheet.addCell(new Label(9,crow,""+k1a+","+k1b));//c是列r是行
sheet.addCell(new Label(10,crow,""+k2a+","+k2b));//c是列r是行
sheet.addCell(new Label(11,crow,""+k3a+","+k3b));//c是列r是行
sheet.addCell(new Label(12,crow,""+k4a+","+k4b));//c是列r是行
sheet.addCell(new Label(13,crow,""+k5a+","+k5b));//c是列r是行
sheet.addCell(new Label(14,crow,""+k6a+","+k6b));//c是列r是行
double pagerank=1;
pagerank=(k1a*0.83+k1b*0.73+k2a*0.56+k2b*0.46+k3a*0.56+k3b*0.46+k4a*0.83+k4b*0.73+k5a*0.83+k5b*0.73+k6a*0.21+k6b*0.11);
sheet.addCell(new Label(15,crow,""+pagerank));//c是列r是行
return pagerank;
}
/*
* 通过url获取输入流
* */
private static String httpRequest(String requestUrl) {
StringBuffer buffer = null;
BufferedReader bufferedReader = null;
InputStreamReader inputStreamReader = null;
InputStream inputStream = null;
HttpURLConnection httpUrlConn = null;
try {
// 建立get请求
URL url = new URL(requestUrl);
httpUrlConn = (HttpURLConnection) url.openConnection();
httpUrlConn.setDoInput(true);
httpUrlConn.setRequestMethod("GET");
// 获取输入流
inputStream = httpUrlConn.getInputStream();
inputStreamReader = new InputStreamReader(inputStream, "utf-8");
bufferedReader = new BufferedReader(inputStreamReader);
// 从输入流读取结果
buffer = new StringBuffer();
String str = null;
while ((str = bufferedReader.readLine()) != null) {
buffer.append(str);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
// 释放资源
if(bufferedReader != null) {
try {
bufferedReader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(inputStreamReader != null){
try {
inputStreamReader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(inputStream != null){
try {
inputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(httpUrlConn != null){
httpUrlConn.disconnect();
}
}
return buffer.toString();
}
/*
* 2、获取网页html代码————3、用正则表达式抽取有用的信息
* */
private static String htmlFiter(String html) {
/*
//爬学者网
StringBuffer buffer = new StringBuffer();
String str1 = "";
String str2 = "";
Pattern p = Pattern.compile("(.*)()(.*?)()(.*)");
Matcher m = p.matcher(html);//从整个html网址看有没有p模式的正则
if (m.matches()) {//如果有
System.out.println("++++++++++++");
str1 = m.group(3);//把上面p模式的正则的第三对选出来
// group(int i) i 指的是 正则表达式中 第几对 括号内的 正则表达式 。。而不是指符合条件的第几个字符串。。。。,比如这里面就是第三对括号内.*?的内容
p = Pattern.compile(" (.*)()(.*?)()(.*)");
m = p.matcher(str1);//第三对满足第一次正则的全部内容中看有没有新的模式P的正则
if(m.matches()){//如果有
System.out.println("---------------");
str2 = m.group(3);//还把p中的(.*?)搜寻到的内容打印出来
buffer.append(str2);//把其中内容加到buffer中
}
}
return buffer.toString();
*/
StringBuffer buffer = new StringBuffer();
String str1 = "";
String str2 = "";
Pattern p = Pattern.compile("(.*)()(.*)()(.*)");//(.*)是所有,带上?则不换行
Matcher m = p.matcher(html);//从整个html网址看有没有p模式的正则
if (m.matches()) {//如果有
str1 = m.group(3);//把上面p模式的正则的第三对选出来
System.out.println(str1);
// group(int i) i 指的是 正则表达式中 第几对 括号内的 正则表达式 。。而不是指符合条件的第几个字符串。。。。,比如这里面就是第三对括号内.*?的内容
p = Pattern.compile("(.*)()(.*?)(
)(.*)");
m = p.matcher(str1);//第三对满足第一次正则的括号内查看全部内容中看有没有新的模式P的正则
if(m.matches()){//如果有
str2 = m.group(3);//还把p中的(.*?)搜寻到的内容打印出来
buffer.append("爬取结果:"+str2);//把其中内容加到buffer中
}
}
return buffer.toString();
}
/**
* 对以上两个方法进行封装。
* @return
*/
public static String getSouGouInfo(String a) {
// 调用第一个方法,获取html字符串
String html = httpRequest(a);
// 调用第二个方法,过滤掉无用的信息
System.out.println(html);
String result = htmlFiter(html);
return result;
}
}
输出结果展示:
控制台结果:
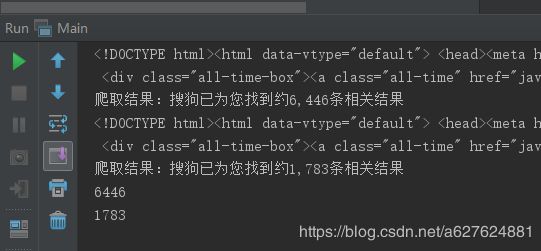
excel结果:
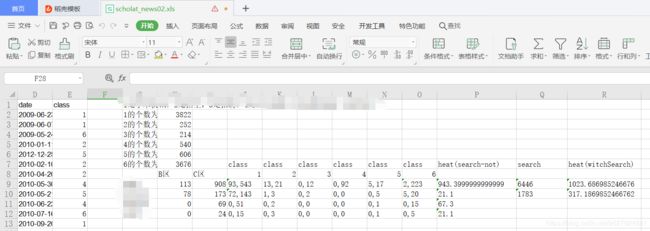
参考文章:
JXL基本操作
JAVA爬取网页内容——使用正则
java mather的group的含义
java从字符串中提取数字