吴恩达Deeplearning.ai 知识点梳理(course 5,week 2)
本周主要讲Word Embeddings,
Word Embedding Intro
Word Representation

之前我们表示word,都是采用one-hot进行表示。这种方式有一个缺点,就是词和词之间是正交的。但是事实上词和词之间是有关系的。举个例子来说,I want a glass of orange ( ),一般就填juice,现在就算我们的language model学会了orange 和juice是一个poplar phrase,但是由于language model并不知道orange和apple是啥关系,也不知道orange和apple的关系,与orange和man/woman/king/queen的关系相比,是不是更近一些,所以很难在apple juice这个phrase上边泛化。这就是用one-hot编码后正交带来的问题。
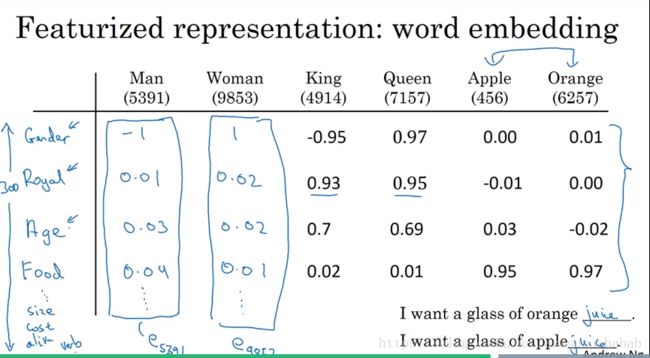
在这种情况下,可以采用另一种表达法:Feature Representation,也就是Word Embedding。它是列举一些通用的Feature,例如Gender,Royal,Age等,给每一个词汇进行一个打分,例如Man的Gender是-1,Woman的Gender是+1,King是-1,Queen是+1,而Apple和Orange则应该为0。在这种表示法下,Apple和Orange之间的相似度则更有机会比Woman和Orange之间的形似度大。
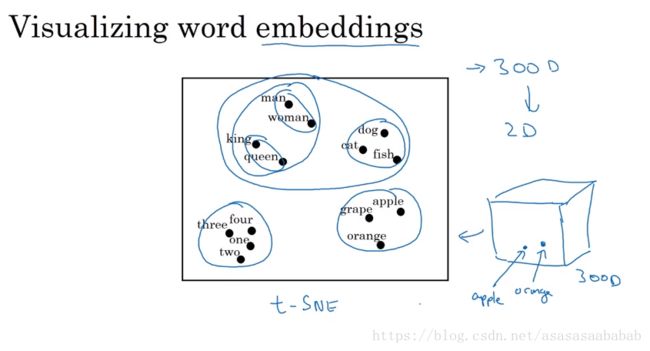
如果我们采用t-SNE的方式把Feature Representation的word降维绘制出来,则会发现他们能够一组一组的聚在一起。同时King和queen之间的差别,与man和woman之间的差别类似。Word Embedding这个词的意思就是将Word潜入到一个Feature空间中。
使用Word Embeddings
使用Word Embeddings的一个例子是姓名检测:
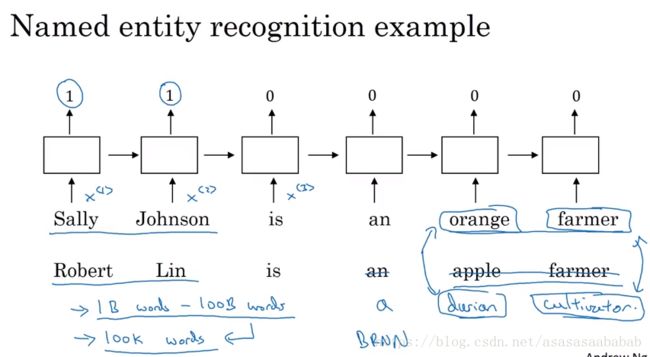
比方说神经网络学习了S J is an orange farmer. Robert Lin is an apple farmer. 假如把apple换成了Duran,farmer换成了cultivator,也许你这个named entity recognition没有训练这个Duran cultivator,甚至有可能压根没见过Duran,cultivator这两个词,但是如果Word Embedding告诉说Duran和orange很像,cultivator和farmer很像,那么这个时候就有可能也会把Robert Lin作为named Entity检测出来。Word Embeding算法本身可能是从一个巨大的语料库里进行学习,例如10亿规模,或者千亿规模的unlabeled的语料库里学习Duran和orange的关系。然后就可以采用word embedding来进行transfer learning。

因此利用word embedding的流程就如同上边所示。
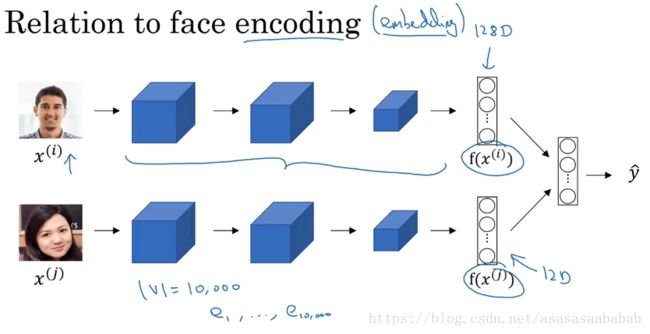
一个和word embedding比较类似的任务是face encoding。这个encoding和embedding其实是一个意思。face encoding其实就是将face经过Siamese network映射到一个vector上,然后进行对比。
Word Embedding 的性质
Word Embedding 有一个很有趣的性质。那就是类比:
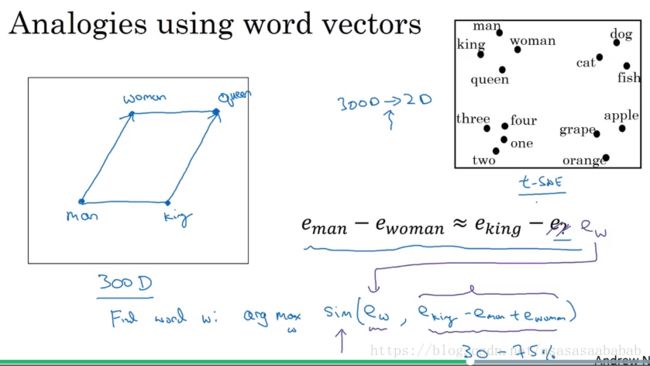
在Feature Space中,woman-man ≈ ≈ king-queen,其实也就是说woman和man的差别主要是在性别上。而king和queen的差别也是主要集中在性别上,因此这两个的差异是相似的。所以可以有类比。一般来说类比的准确率在30%~75%左右。这样我们便可以采用余弦距离来进行相似度的度量:

Formalize Word Embedding Learning
说了这么久,word embedding究竟究竟是如何形式化的呢?
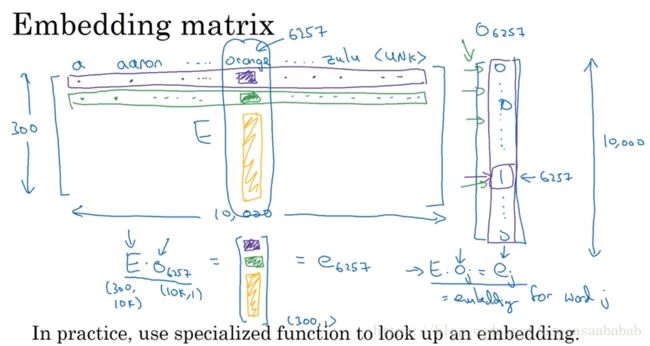
事实上,word embedding learning就是学习一个embedding matrix E E ,这个 E E 将one-hot vector变换到embedding的空间。通常来说,这个 E E 是随机初始化的,然后通过优化得到最终的 E E 。
Word Embedding Learning
Learning Word Embeddings - Language Model
学习word embedding的一个很好的方式就是采用学习language model的方法:
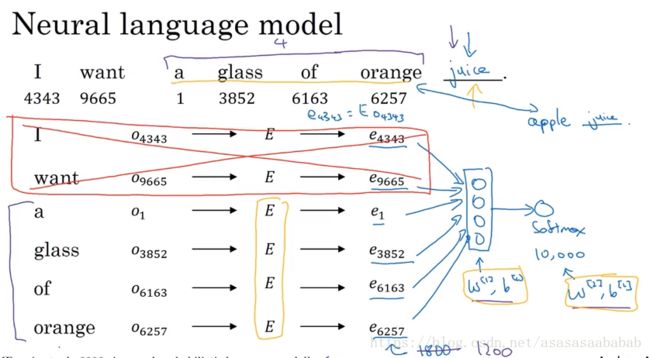
这个方法是先将各个word用E进行投影到embedding的空间,然后stack起来,用一个softmax来预测下一个词是什么。softmax当然也是有自己的w和b。由于整个模型希望用很少的feature,例如300,来表达数万词汇,然后network发现有的时候会出现apple juice,有的时候会出现orange juice,因此会将apple等水果变成比较相似的向量。

进一步,如果是训练language model,那么确实需要用last 4 words,但是如果是学习word embedding,那么就可以把target word附近进行学习,例如前后各4个词,例如a glass of orange ? to go along with. 甚至也可以Last 1 word,例如看到了orange,那下一个词是啥?更神奇的是Nearby 1 word,假如看到了glass,那下一个词是啥?这个叫做skip-gram model。这种nearby 1 word,也可以work很好。
Word2Vec Skip-gram model

正如上边所讲的,Word2Vec Skip-Gram model就找到一个target,然后在context里边随机采样。然后拿去softmax做训练。

就是上图这种。softmax就是softmax,没啥特别的。

但是这个算法的问题是如果真的这么算,这个计算量会非常大,比方说10000个素材,那个分母就得计算10000个,如果是100B,那就不得了了。所以会采用softmax tree的方式,这样就可以logN的复杂度了。另外softmax tree也不是平衡的tree,而是根据出现概率的大小来的。
另外是如何进行contex 采样?因为a啊,the啊,都比容易出现,我们不想每次更新太多a,所以一般不是采用均匀采样的方式,而是采用经验法来balance一下common word和非common word。
Negative Sampling
Negative Sampling和Word2Vec很像,但是大大简化了计算量:

这个是首先采集一个context word,然后从context里边选一个target word,然后再从词典里边随机选4个(large dataset)到20个(small dataset),然后做1,0预测。

所以相比较而言,这个就简单了很多。这个问题相当于在问,我选了一个context word,那么word1是不是target word?word2是不是target word。相比计算10000个word,我们只需要计算5个左右的logistic regression就可以了。
如何进行采样呢?作者给出了建议:

就按照出现的频次取power(*, 3/4)就可以了。
GloVe
GloVe算法在自然语言处理社区也有很多拥趸。GloVe算法非常简单。

首先是计算出target i在context c里边出现的次数。
然后做如下的优化:

其实就是想用 θTiej θ i T e j 预测次数 log(Xi,j) l o g ( X i , j ) ,换个形式 eθTiej e θ i T e j 来预测次数 Xi,j X i , j ,所以也是logistic regression的一种形式。同时由于这里边 θi θ i 和 ej e j 是对称的,所以最后结果就直接去一个平均数就可以了。

值得指出的是,用word embedding学习来的 E E 并不一定对应于我们人能够理解的Feature,很有可能是变换过的。其实就跟CNN选特征一样。我们也不知道到底选了那些特征,为啥选这个特征。
Word Embedding 的应用
情感分类

情感分类最大的问题是数据量不足。因此我们采用word embedding的方式进行:

一个简单的例子就是直接把词汇投射到embedding的空间里,然后vector做一个平均,然后使用softmax做分类,这样能够解决变长的问题。但是一个比较有问题的是,假如一句话里边有一个否定词,然后剩下都是好好好,那很可能也到一个错误的结果。因此这里可以采用RNN的方法:

这样就有更好的曲面能够拟合了。这里需要说明的是,如果lacking换成了absent,由于使用了word embedding,因此也能得到一个很好的效果。
Word Embedding带来的歧视

有的时候Word Embedding会出现一些歧视,比方说Man对应程序猿,Woman对应家庭主妇。其实这个是因为统计概率导致的。但是从公平上讲,Woman应该对应女程序猿。由于AI系统今后可能会指导决策,因此一个中立的AI系统是非常重要的。

消除歧视一般分为3步,第一步是找到bias的方向,比方说 ehe−eshe e h e − e s h e 和 emale−efemale e m a l e − e f e m a l e ,然后求个平均,这样就能到到bias的方向。第二步,使用SVD将有问题的向量投射到垂直于bias的子空间里边,这样就消除了bias。第3步,均衡化,有的时候投射完了,会导致一些词汇距离另一些词汇的距离发生变化,带来新的bias,例如baby sitter距离grandma比grandpa更近,因此要将grandma和grandpa调整一下,使得距离相同。