区块链既然本质是数据库. 其基础单元是区块(Block).
区块
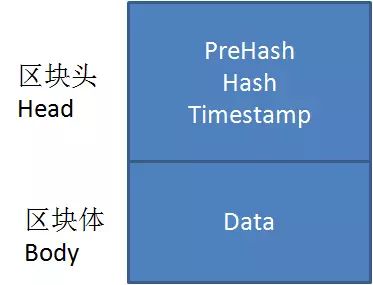
一个区块分为两大部分:
1、区块头
区块头里面存储着区块的头信息,包含上一个区块的哈希值(PreHash),本区块体的哈希值(Hash),以及时间戳(TimeStamp)等等。
2、区块体
区块体存储着这个区块的详细数据(Data),这个数据包含若干行记录,可以是交易信息,也可以是其他某种信息。
MD5是一种典型的哈希算法, 可以将任意长度的明文转化为128bit长的字符串. 而区块链中使用的哈希算法是更复杂的SHA256算法, 哈希值有256bit长.
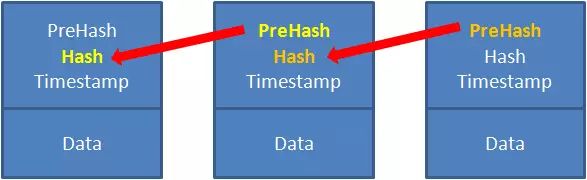
不同区块之间通过Hash进行关联, 形成一个类似于链表的结构.
挖矿
既然区块链是一个链状结构,就必然存在链条的头节点(第一个区块)和尾节点(最后一个区块)。一旦有人计算出区块链最新数据信息的哈希值,相当于对最新的交易记录进行打包,新的区块会被创建出来,衔接在区块链的末尾。
新区块头的Hash就是刚刚计算出的哈希值,PreHash等于上一个区块的Hash。区块体的Data存储的是打包前的交易记录,这部分数据信息已经变得不可修改。
这个计算Hash值,创建新区块的过程就叫做挖矿。

为什么挖矿那么难?
计算哈希值究竟难在哪里?咱们以比特币为例, 来做一个最粗浅的解释,哈希值计算的公式如下:
Hash = SHA-256(最后一个区块的Hash + 新区块基本信息 + 交易记录信息 + 随机数)
其中,交易记录信息也是一串哈希值,它的计算涉及到一个数据结构 Merkle Tree。有兴趣的小伙伴可以查阅相关资料,我们暂时不做展开介绍。
这里关键的计算难点在于随机数的生成。猥琐的区块链发明者为了增大Hash的计算难度,要求Hash结果的前72bit必须都是0,这个几率实在是太小太小。
由于(最后一个区块的Hash + 新区块基本信息 + 交易记录信息)是固定的,所以能否获得符合要求的Hash,完全取决于随机数的值。挖矿者必须经过海量计算,反复生成随机数进行“撞大运”一般的尝试,才有可能得到正确的Hash,从而挖矿成功。
同时,区块头内还包含着一个动态的难度系数,当全世界的硬件计算能力越来越快的时候,区块链的难度系数也会水涨船高,使得全网平均每10分钟才能产生出一个新区块。
比特币
比特币(BitCoin)的概念最初由中本聪于2008年提出,而后根据这一思路设计发布了开源软件以及建构其上的P2P网络。比特币是一种P2P形式的数字货币。点对点的传输意味着一个去中心化的支付系统。
P2P网络
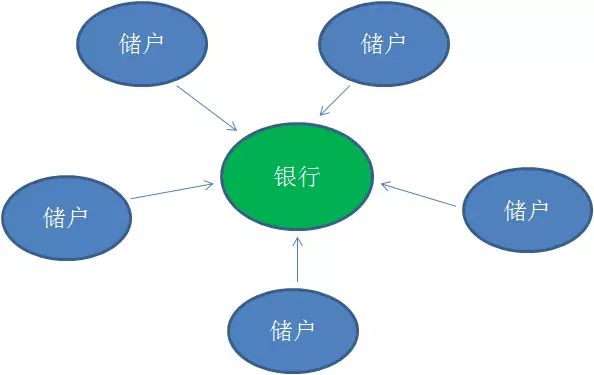
传统的货币都是由中央银行统一发行,所有的个人储蓄也是由银行统一管理,这是典型的中心化系统。
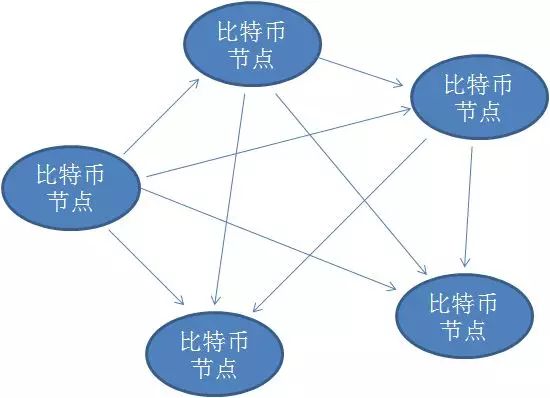
而比特币则是部署在一个全世界众多对等节点组成的去中心化网络之上。每一个节点都有资格对这种数字货币进行记录和发行。
至于比特币底层的数据存储,正是基于了区块链技术。比特币的每一笔交易,都对应了区块体数据中的一行,简单的示意如下:

交易记录的每一行都包含时间戳、交易明细、数字签名。
表格中只是为了方便理解。实际存储的交易明细是匿名的,只会记录支付方和收款方的钱包地址。
至于数字签名呢,可以理解为每一条单笔交易的防伪标识,由非对称加密算法所生成。
比特币协议规定,挖到新区块的矿工将获得奖励,从2008年起是50个比特币,然后每4年减半,目前2018年是12.5个比特币。
区块链的优势:
1、去中心化
区块链不依赖于某个中心节点,整个系统的数据由全网所有对等节点共同维护,都可以进行数据的存储和检验。这样一来,除非攻击者黑掉全网半数以上的节点,否则整个系统是不会遭到破坏的。
2、信息不可篡改
区块内的数据是无法被篡改的。一旦数据遭到篡改哪怕一丁点,整个区块对应的哈希值就会随之改变,不再是一个有效的哈希值,后面链接的区块也会随之断裂。
区块链的劣势:
1、过度消耗能源
想要生成一个新的区块,必须要大量服务器资源进行大量无谓的尝试性计算,严重耗费电能。
2、信息的网络延迟
以比特币为例,任何一笔交易数据都需要同步到其他所有节点,同步过程中难免会受到网络传输延迟的影响,带来较长的耗时。
参考
- 用最通俗易懂的方式打开区块链!
- 阮一峰|区块链入门教程
疑问
- 在茫茫多的区块中, 本区块是如何通过preHash找到上一个区块的?
- 如果两个block的prehash一样, 就会导致分叉, 如何避免分叉?
- 比特币挖矿的时候,
Hash = SHA-256(最后一个区块的Hash + 新区块基本信息 + 交易记录信息 + 随机数)新区块基本信息和交易记录信息都是什么?