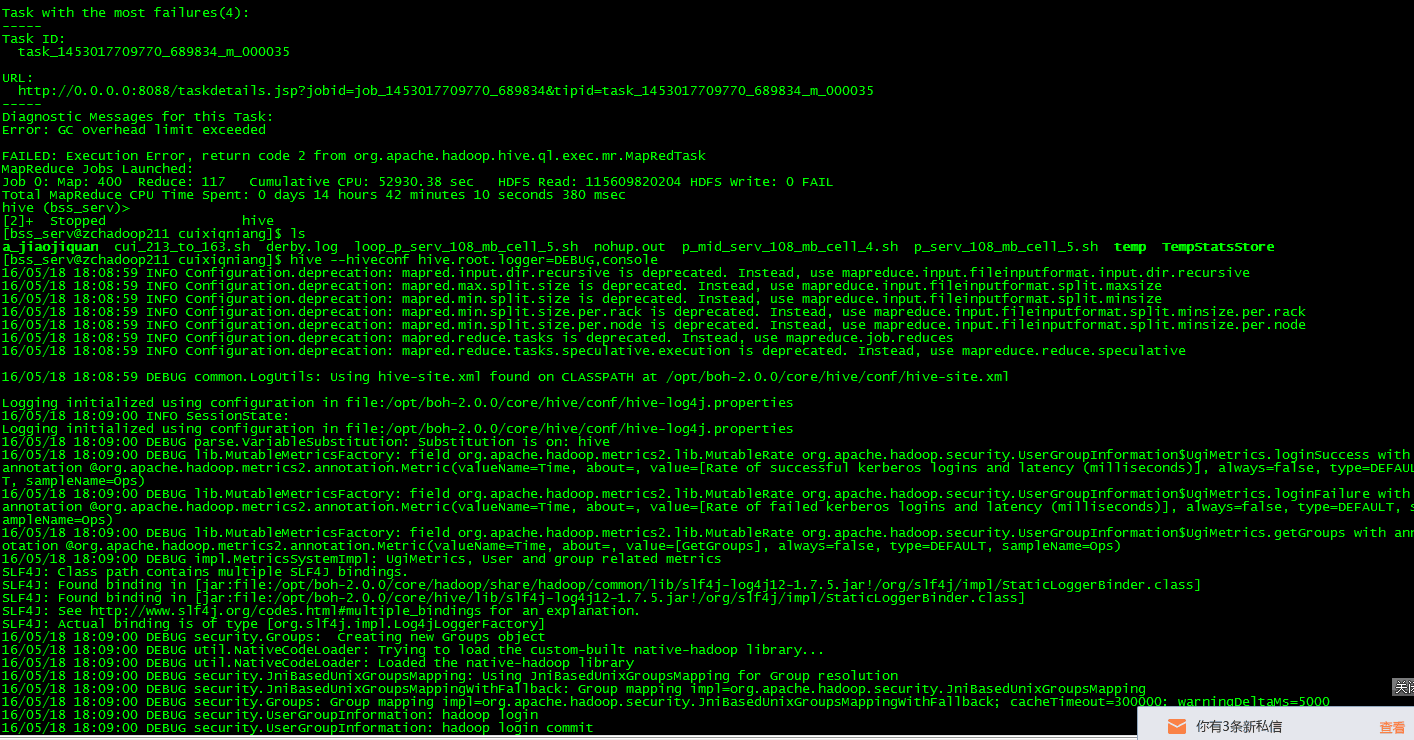
原因分析:在执行hive shell的时候map任务阶段执行到99%,而reduce节点只执行到33%人后就出现了上面的错误。
自我解释:
(1)上面的情况说明,在map阶段执行结束的时候,当垃圾回收器在回收map阶段所产生的对象,因为数据倾斜的原因所导致对象过大,所以不能顺利的回收map阶段所产生的垃圾。
(2)从具体的报错信息可以看出,stage-1已经执行了将近99%,也就是说,在map阶段执行结束的时候,如果在map阶段发生了聚合,虽然会提升效率,但是会使用更加多的内存,如果垃圾回收器压力很大,那么reduce task一直处于waiting状态,之所以这样,是因为container一直需要被回收却回收不了。
一般数据倾斜的解决思路:
增加map任务的堆内存大小并设置标记-清理垃圾回收器:
set mapreduce.map.java.opts=-Xmx3072m -XX:+UseConcMarkSweepGC;(注意: mapreduce.map.memory.mb=4096;必须小于这个值)
set hive.groupby.skewindata =true;(当选项设定为 true,生成的查询计划会有两个 MR Job。第一个 MR Job 中,Map 的输出结果集合会随机分布到 Reduce 中,每个 Reduce 做部分聚合操作,并输出结果,这样处理的结果是相同的 Group By Key 有可能被分发到不同的 Reduce 中,从而达到负载均衡的目的;第二个 MR Job 再根据预处理的数据结果按照 Group By Key 分布到 Reduce 中(这个过程可以保证相同的 Group By Key 被分布到同一个 Reduce 中),最后完成最终的聚合操作。)
sethive.optimize.skewjoin=true;(如果是join 过程出现倾斜应该设置为true)
如果上面的方法解决不了当前数据倾斜的问题就使用下面的方法:
hive.map.aggr=false;(禁用在map中会做部分聚集操作,这样map阶段使用的内存降低,但效率会降低,如果上面的方法能解决问题,不建议使用这种方法)