kaggle | 基于k-means和KNN的语音性别识别
kaggle | 基于k-means和KNN的语音性别识别
- 1 背景说明
- 2 算法原理
- 2.1 什么是KNN
- 2.2 为什么要kmeans+KNN
- 3 代码实现
- 3.1 文件目录
- 3.2 核心代码
- 4 实验与结果分析
- 5 后记
概要: 本实验是在实验“kaggle|基于朴素贝叶斯分类器的语音性别识别”和实验“算法|k-means聚类”的基础上进行的,把k-means聚类应用到语音性别识别问题中去,并同时使用KNN识别算法。有关数据集和kmeans的内容可以先看我的上两篇博文,本实验的代码依然是MATLAB。
关键字: 语音性别识别; k-means; KNN; MATLAB; 机器学习
1 背景说明
我在我的上一篇博文中提到会把kmeans聚类算法用到诸如语音性别识别和0-9数字手写体识别等具体问题中去,所以还是抱着长痛不如短痛的想法赶紧把这些东西给写了,以防止自己忘掉或者懒癌发作以至于终究没有了下文。其实这个很简单。
2 算法原理
2.1 什么是KNN
KNN是K最邻近(K Nearest Neighbor)分类算法的简写,它是数据挖掘与分析包括机器学习中最简单的分类方法之一。KNN是“惰性学习”(Lazy Learning)的著名代表,它对数据不做任何模型训练,训练时间开销为零,所以也被称为为“史上最懒惰的算法”。
KNN的基本思想是:如果一个样本在特征空间中的K个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。注意,该样本所选中进行比较的“邻居”都是已经正确分类的对象。简而言之,KNN算法体现的思想就是“随大流”,或者说“近朱者赤、近墨者黑”。虽然很简单,但是很好用。
严谨地说,KNN的流程如下:
1-准备已标记好类别的合适数据,构成特征空间;
2-选定K值;
3-当出现一个新数据时,计算该新数据与当前特征空间中所有已知类别的数据的距离,并按照从小到大的顺序排列;
3-取排列好的数据列表的前K条,找出这K条数据中条数最多的类别;
4-将该新数据归入此类别。
2.2 为什么要kmeans+KNN
从上文来,光用KNN就可以解决问题了啊,为什么还要用k-means呢?概括地说,是为了简化计算。
以本实验为例,实验中我们一共有3168条数据,男女各1584条,每条数据有20个参数,这就是一个3168*20的矩阵。在仅使用KNN时,每新来一个数据就需要计算它和所有3168条数据之间的距离。说实话千量级的数据量的确不算多,可是如果数据量是百万量级呢,如果每一条数据都有数以十万计的特征呢——在大数据时代这很常见——显然运算量就会变得非常巨大。而k-means就可以通过聚类显著减少特征空间中的数据量,相当于是每发现若干个相似或相近的样本就选出或生成某一个来做代表,这样很轻易就可以做到十倍、百倍地减少数据量,从而简化计算。例如,可以在男声和女声的数据中各聚10类,就将1584条数据减少到了10条,而且后续的实验也将证明这样的数据筛选是科学合理的,对于最终结果的影响在可以接受的范围之内。
3 代码实现
3.1 文件目录
文件目录如图1所示。
仔细观察就可以发现本实验的文件目录实际上就比实验“算法|k-means聚类”多了一个源文件gender_recog.m,这就是实验代码,相当于main函数,它主要调用了mykmeans.m,又通过mykmeans.m调用了目录中的其他函数。
3.2 核心代码
所谓的核心代码其实也相当简单,无非就是聚类、判断(类别)两步。See the code:
% k-means 聚类
k=1000;
DIM = 1;
errdlt = 0.5;
% 给男女声聚类
[Idx_m,C_m,~,~,Errlist_m] = mykmeans(Train_m,k,DIM,errdlt);
[Idx_f,C_f,~,~,Errlist_f] = mykmeans(Train_f,k,DIM,errdlt);
C_m = [C_m,zeros(k,1)];
C_f = [C_f,ones(k,1)];
C=[C_m;C_f];
上面是聚类,男女声分开来各聚k类,直接调用我写的mykmeans.m就搞定了。
% 分别对男女测试集做KNN识别
K = 9;
dists = zeros(k*2,2);
% 判断测试集中的男声
P_M = 0;
N_M2M = 0;
N_M2F = 0;
for i=1:test_num
temp = repmat(Test_m(i,:),2*k,1);
dists(:,1) = sum((temp-C(:,1:20)).^2,2);
dists(:,2) = [zeros(k,1);ones(k,1)];
[B,ind] = sort(dists(:,1));
ind = ind(1:K,1);
for j=1:K
if ind(j,1)<=k
P_M = P_M+1;
end
end
if P_M>=(K+1)/2 % K需要是奇数
N_M2M = N_M2M+1;
else
N_M2F = N_M2F+1;
end
P_M = 0;
end
correct_m2m = N_M2M/test_num;
上面是判断类别,也可以说是识别,男女声分开识别、分开计算识别准确率。
这里需要注意到 k 和 K 的区别,其中小写的 k 表示的是聚类的数量,而大写的 K 表示的是纳入采信范围的与待识别样本最邻近的数据条数。需要注意的是, 第一,k 的取值应当小于总数据条数,因为当k等于总数据条数时聚类失去意义,当k大于总数据条数时则完全错误;第二, K 应当取奇数,这样在进行二分类问题时就不会出现概率相等——都等于50%——以至于无法判断的情况。
4 实验与结果分析
影响实验结果的因素有很多,包括但不限于以下几点:
1-聚类数 k 的选取;
2-最邻近采信范围 K 的选取;
3-kmeans聚类循环轮数上限的设定;
4-kmeans聚类误差变化量阈值的设定;
5-kmeans聚类初始中心的选择;
6-距离测度的选择;
7-原始数据是否经过量化;
具体问题具体分析,通过初步的粗略实验可以发现,在本实验中对最终结果影响较大的因素是第1、2条和第7条。
其中,第3、4、5条是影响kmeans聚类效果的因素,对本实验的影响很小。所以分别选为“不设循环论述上限、误差变化量阈值设为0.5、聚类初始中心随机选取”即可;第6条的选择取决于对象的性质,在这里我们选用欧氏距离即可。
而第7条和KNN以及k-means算法本身无关,是由于数据集的缘故才出现的一个问题。经过粗略的实验发现,当数据是量化后的整数时,正确率可以保持;而当数据换成最原始的浮点数据时,识别正确率急剧大幅降低。所以实验中选择了量化后的数据。
还有一点需要注意的是由于训练集和测试集是按照7:3的比例随机选取的,所以即使在所有参数都相同的情况下每次实验的结果也会有所不同。为此,我对于每组相同的参数都进行了3次实验,取其平均值作为最后的结果记录。
调整参数k和K的值进行了一些列实验,得到如图2所示的结果:
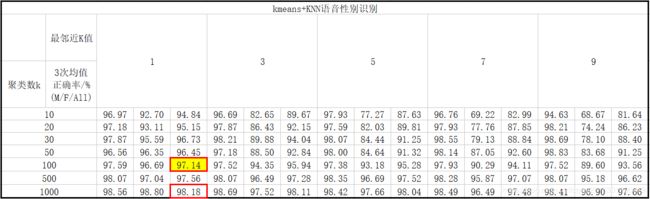
根据图2的结果,至少可以得到如下结论:
1-总地来说,男声的识别正确率高于女声,即女声更容易被误识别为男声;
2-总地来说,男女声识别正确率随着k值的增加和K值的减小而提高;
3-随着k值的增加和K值的减小,女声识别正确率显著大幅提高,而男声识别正确率提高幅度很小;
4-男女声识别正确率的提高和k值的增加不成正比,其中以男声尤甚:k值增加2个数量级男声识别正确率仅提高1-4个百分点;
5-在不考虑运算量的情况下,令k=1000,K=1可获得男女声识别总正确率最高,达到98.18%,若要平衡运算与效率,可取k=100,K=1,得到男女声识别总正确率为97.14%:运算量减小10倍,正确率仅下滑约1个百分点;
6-上升到理论高度,我们可以再次感受到边际效应的存在。如本例中k=10时(对男声而言)已经可以取得较好的识别效果,此时即使将k提高到1000,乃至提高到1100(训练集总数),也很难使男声识别正确率再有很大的提升。
5 后记
最后再说明一下我这篇博客的基础是之前的2篇博客:“kaggle|基于朴素贝叶斯分类器的语音性别识别”和“算法|k-means聚类”,希望读者也去看一看。
接下来我将完成上次立下的第2个flag:将kmeans应用到0-9数字手写体识别中去,有了这次试验的经历我想这应该不是很难。
这次实验参考了不少网上的博客,其中“机器学习(一)——K-近邻(KNN)算法”和“数据挖掘十大算法–K近邻算法”内容不错,推荐阅读。另外也偶然发现了一个大佬的个人网页,干货多多,特此收藏。
由于我已在之前的博客“算法|k-means聚类”中提供了与k-means有关的下载链接,所以这里只提供函数gender_recog.m的下载链接。
转载时务必注明来源及作者。尊重知识产权从我做起。
代码已上传至网络,欢迎下载,密码是fjhb。