Spark权威指南(中文版)----第22章 事件时间和有状态处理
Spark The Definitive Guide(Spark权威指南) 中文版。本书详细介绍了Spark2.x版本的各个模块,目前市面上最好的Spark2.x学习书籍!!!
扫码关注公众号:登峰大数据,阅读中文Spark权威指南(完整版),系统学习Spark大数据框架!
如果您觉得作者翻译的内容有帮助,请分享给更多人。您的分享,是作者翻译的动力

第21章介绍了核心概念和基本api;本章深入研究事件时间和有状态处理。事件时间处理是一个热门话题,因为我们分析的是信息创建的时间,而不是处理的时间。这种处理方式之间的关键思想是,在作业的生命周期中,Spark将维护相关的状态,在将其输出到接收器之前,它可以在作业过程中更新这些状态。
在开始使用代码来展示这些概念之前,让我们更详细地介绍一下这些概念。
22.1.事件时间和处理时间
事件时间是一个需要单独讨论的重要主题,因为Spark的DStream API不支持处理与事件时间相关的信息。在更高的层次上,在流处理系统中,每个事件实际上有两个相关的时间: 它实际发生的时间(事件时间),以及它被处理或到达流处理系统的时间(处理时间)。
22.1.1.事件时间
事件时间是嵌入到数据本身中的时间(虽然不是必需的),但通常是事件实际发生的时间。这一点很重要,因为它提供了一种更健壮的方式来比较事件。这里的挑战是事件数据可能会延迟或无序。这意味着流处理系统必须能够处理无序或延迟的数据。
22.1.2.处理时间
处理时间是流处理系统实际接收数据的时间。这通常没有事件时间那么重要,因为在处理它时,它主要是一个实现细节。这不可能是无序的,因为它是流系统在特定时间的属性(而不是像事件时间这样的外部系统)。
这些解释很抽象,让我们用一个更具体的例子。假设我们有一个位于旧金山的数据中心。一个事件同时发生在两个地方:一个在厄瓜多尔,另一个在弗吉尼亚州(见图22-1)。
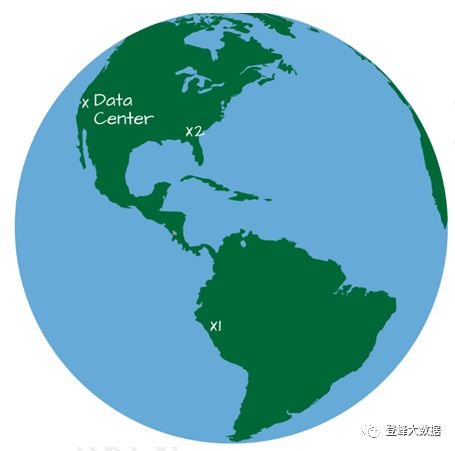
由于数据中心的位置,弗吉尼亚州的事件可能在厄瓜多尔事件之前出现在我们的数据中心中。如果我们根据处理时间来分析这些数据,那么弗吉尼亚事件似乎发生在厄瓜多尔事件之前: 我们知道是错的。然而,如果我们要基于事件时间分析数据(很大程度上忽略了它被处理的时间),我们会看到这些事件是同时发生的。
如前所述,基本思想是处理系统中一系列事件的顺序并不保证事件时间上的顺序。这可能有点不直观,但值得注意。计算机网络是不可靠的。这意味着,时间可以被丢弃、缓慢发送、重复发送。由于单个事件不能保证遭受这样或那样的命运,因此我们必须承认,在从信息源到流处理系统的过程中,这些事件可能发生许多事情。因此,我们需要对事件时间进行操作,并根据数据中包含的信息查看整个流,而不是查看数据何时到达系统。这意味着我们希望根据事件发生的时间来比较事件。
22.2.有状态处理
本章中我们需要讨论的另一个主题是有状态处理。实际上,我们已经在第21章中演示过很多次了。有状态处理只在需要长时间使用或更新中间信息(状态)时才有必要(以微批处理或一次记录的方式)。无论是否涉及事件时间,在使用事件时间或对键执行聚合时都可能发生这种情况。
在大多数情况下,当您执行有状态操作时。Spark为您处理所有这些复杂性。例如,当您指定分组时,结构化流为您维护和更新信息。您只需指定逻辑即可。在执行有状态操作时,Spark将中间信息存储在一个state store中。Spark的当前状态存储实现是内存中的状态存储,它通过将中间状态存储到checkpoint目录来实现容错。
22.3.任意状态处理
上面描述的有状态处理功能足以解决许多流问题。然而,有时您需要细粒度地控制应该存储什么状态、如何更新状态以及何时删除状态(显式地或通过超时)。这称为任意(或自定义)有状态处理,Spark允许您在流的处理过程中存储您喜欢的任何信息。这提供了巨大的灵活性和功能,并允许非常容易地处理一些复杂的业务逻辑。:就像我们之前做的一样,让我们用一些例子来证明这一点:
-
您希望在电子商务网站上记录有关用户会话的信息。例如,您可能希望跟踪用户在此会话过程中访问的页面,以便在他们的下一个会话期间实时提供建议。当然,这些会话有完全任意的开始和停止时间,这对于该用户来说是惟一的。
-
您的公司希望报告web应用程序中的错误,但只有在用户会话期间发生5个事件时才会报告。您可以使用基于计数的窗口来实现这一点,该窗口只在发生五种类型的事件时才发出结果。
-
您希望随时间删除重复记录。要做到这一点,您需要在删除复制之前跟踪所看到的每条记录。
现在我们已经解释了本章中需要的核心概念,接下来我们将用一些示例来介绍所有这些概念,并解释在以这种方式处理时需要考虑的一些重要注意事项。
22.4.事件时间基础
让我们从前一章的相同数据集开始。处理事件时间时,它只是数据集中的另一列,这就是我们需要关心的;我们只需使用该列,如下所示:
// in Scalaspark.conf.set("spark.sql.shuffle.partitions", 5)val static = spark.read.json("/data/activity-data")val streaming = spark.readStream.schema(static.schema).option("maxFilesPerTrigger", 10).json("/data/activity-data")# in Pythonspark.conf.set("spark.sql.shuffle.partitions", 5)static = spark.read.json("/data/activity-data")streaming = spark\.readStream\.schema(static.schema)\.option("maxFilesPerTrigger", 10)\.json("/data/activity-data")streaming.printSchema()root|-- Arrival_Time: long (nullable = true)|-- Creation_Time: long (nullable = true)|-- Device: string (nullable = true)|-- Index: long (nullable = true)|-- Model: string (nullable = true)|-- User: string (nullable = true)|-- gt: string (nullable = true)|-- x: double (nullable = true)|-- y: double (nullable = true)|-- z: double (nullable = true)
在这个数据集中,有两个基于时间的列。Creation_Time列定义事件何时创建,Arrival_Time定义事件何时到达上游服务器。在本章中,我们将使用Creation_Time。这个示例从一个文件读取数据,但是,正如我们在前一章中看到的,如果您已经建立并运行了一个集群,那么将其更改为Kafka将非常简单。
请在公众号中阅读本章剩下的内容。