死锁检测lockdep实现原理
死锁在编程中是再常见不过的错误了,和内存泄露一样是很难避免的问题,Ingo Molnar发明了lockdep用来检测死锁,它将问题产生的场景进行了归纳总结,避开了对锁进行单个追踪的方式来调试问题而是使用另外一种smart的方式,它不再处理单个锁而是处理锁类.他不仅适用于普通的自旋锁,还可以用在mutex,rwlock,rcu中.
目前这个功能的调试只适合在开发环境下,不适合在生产环境下,它在持锁和释放锁的过程中做了非常多的检查工作,并且它的实现中使用了一些全局表的操作,非常耗性能的.可以在开发阶段设置死锁触发的场景下进行重启,当然这需要有能力进行kdump,服务器环境下还是通过syslog记录死锁的堆栈.它的堆栈提示非常友好,基本上不需要使用crash这类工具进行深度分析就可以很快还原问题,推荐开发阶段使用.
死锁场景
死锁场景有:AA锁,ABBA锁。
其中AA锁场景又分为简单重复上锁和上下文切换引起的上锁,前者不必多说,而后者可能是锁使用场景可能有软中断和进程上下文,但是它使用的普通的spin_lock/spin_unlock而不是spin_lock_bh/spin_unlock_bh版本的,在进程上下文临界区中被中断打断,中断退出后进入软中断,此时就形成了AA死锁.
而ABBA锁是获取锁顺序不一致导致的死锁,如下:
thread_P() {
spin_lock(&lockA);
spin_lock(&lockB);
spin_unlock(&lockA);
spin_unlock(&lockB);
}
thread_Q() {
spin_lock(&lockB);
spin_lock(&lockA);
spin_unlock(&lockB);
spin_unlock(&lockA);
}
lockdep的原理
1.lockdep不再单独追踪每个锁,而是一类锁,例如inode->i_lock,内核中有很多的inode对象,但是他们共享同样一个lock_class对象,通过在spin_lock系列的api内部改造来使得开发者对此无感. inode对象通常都会使用inode_init_always或类似的接口来进行初始化,当第一次执行的时候会创建一个局部静态变量,后续对象初始化的时候会沿用静态变量,实现公用一个锁类.
2.每个锁类维护了一个before和after链表
before 链:锁类 L 前曾经获取的所有锁类,也就是锁类 L 前可能获取的锁类集合.
after 链:锁类 L 后曾经获取的所有锁类.
当尝试获取锁L,它会检查在当前获取的锁栈中是否已经持有过该锁;此外还检查它的before链和after链中是否有重叠,也就是一个锁既在before中,也在after中
3.持有锁的上下文是多样的,但是有些上下文是不能混用的,就如上面所说的软中断上下文和进程上下文中使用spin_lock/spin_lock_bh两个版本的锁api造成的死锁问题,在这里同样会检查锁的状态.
锁类有 4n + 1 种不同的使用历史状态:
其中的 4 是指:
‘ever held in STATE context’ –> 该锁曾在 STATE 上下文被持有过
‘ever held as readlock in STATE context’ –> 该锁曾在 STATE 上下文被以读锁形式持有过
‘ever held with STATE enabled’ –> 该锁曾在启用 STATE 的情况下被持有过
‘ever held as readlock with STATE enabled’ –> 该锁曾在启用 STATE 的情况下被以读锁形式持有过
其中的 n 也就是 STATE 状态的个数:
hardirq –> 硬中断
softirq –> 软中断
reclaim_fs –> fs 回收
其中的 1 是:
ever used [ == !unused ] –> 不属于上面提到的任何特殊情况,仅仅只是表示该锁曾经被使用过
lockdep的实现
下面主要通过数据结构之间的联系来展示它的实现过程
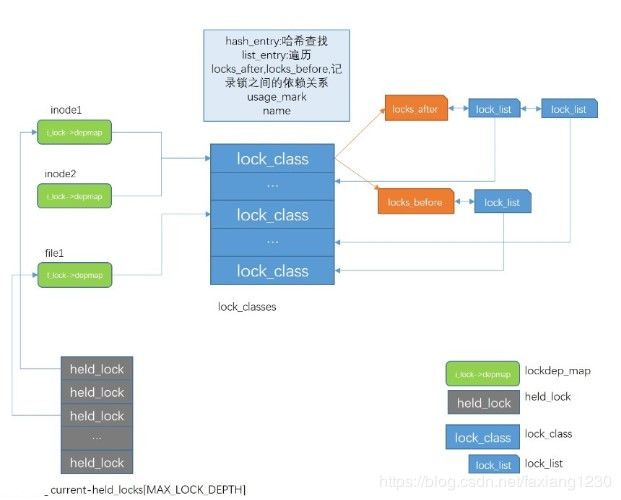
lock_class:lockdep中的核心结构,维护了锁的before和after结构,就是锁之间的依赖关系.另外还通过链表结构维护,可以进行遍历操作,通过hash表结构进行查找操作,里面还记录锁的ip,可以通过kallsym翻译成可读形式的符号.
lock_list:lock_class的before/after链表上挂的数据结构,主要是关联锁类lock_class信息,形成一对多的关系,遍历before/after链表时找到lock_class对象.
held_lock:进程的锁栈上记录,每一个获取锁的操作就会在current进程信息中添加一个held_lock信息,目前最多支持48层锁栈,之后会尝试将锁栈上的锁加入到lock_class的before/class链表中,其中会进行检查.其中当中断发生时,会保存进程上下文,之后会进入中断处理,所以在中断上下文中使用的也是进程上下文的进程held_lock记录数组,在处理的时候会判断是否从进程上下文切换到中断上下文,当切换的时候只会负责相同上下文的held_lock信息.
lock_chain:记录当前的lock是否已经和锁L进行了关联,lock_chain_get_class可以通过该数据结构的可以找到lock_class.如果已经关联过了,则略过.否则会添加依赖关系,在此过程中会检查是否会产生死锁.
lockdep_map:每个锁额外的数据结构,可能是多个锁实例指向同一个锁类数据结构
检查规则
以下摘自内核的
Documentation/locking/lockdep-design.txt
单锁状态检查(Single-lock state rules):
1.一个软中断不安全(softirq-unsafe)的锁类同样也是硬中断不安全(hardirq-unsafe)的。
2.对于任何一个锁类,它不可能同时是hardirq-safe和hardirq-unsafe,也不可能同时是softirq-safe和softirq-unsafe,即这两对对应状态是互斥的。
多锁依赖规则(Multi-lock dependency rules):
1.同一个锁类不能被获取两次,因为这会导致递归死锁。
2.不能以不同的顺序获取两个锁类,即如此这样是不行的:
->
->
因为这会非常容易的导致本文最先提到的AB-BA死锁。
3,同一个锁实例在任何两个锁类之间不能出现这样的情况:
->
->
这意味着,如果同一个锁实例,在某些地方是hardirq-safe(即采用spin_lock_irqsave(…)),而在某些地方又是hardirq-unsafe(即采用spin_lock(…)),那么就存在死锁的风险。这应该容易理解,比如在进程上下文中持有锁A,并且锁A是hardirq-unsafe,如果此时触发硬中断,而硬中断处理函数又要去获取锁A,那么就导致了死锁。
在锁类状态发生变化时,进行如下几个规则检测,判断是否存在潜在死锁。比较简单,就是判断hardirq-safe和hardirq-unsafe以及softirq-safe和softirq-unsafe是否发生了碰撞,直接引用英文,如下:
– if a new hardirq-safe lock is discovered, we check whether it
took any hardirq-unsafe lock in the past.
– if a new softirq-safe lock is discovered, we check whether it took
any softirq-unsafe lock in the past.
– if a new hardirq-unsafe lock is discovered, we check whether any
hardirq-safe lock took it in the past.
– if a new softirq-unsafe lock is discovered, we check whether any
softirq-safe lock took it in the past.
validate_state
锁类lock_class的成员usage_mask中记录着迄今为止锁使用的上下文,当尝试持有锁的时候会检查是否有不同上下文混用的情况.
通过mark_lock接口在lock_acquire路径中进行更新它,除了4*n+1种状态还有读/写两种方向用于读写锁嵌套的场景.
下面是usage_mask中成员的注释:
* bit 0 - write/read
* bit 1 - used_in/enabled
* bit 2+ state
我们通过enum lock_usage_bit的成员可以看到,每个STATE都是由4种情况组成,即低2位代表4中情况,第3和4位代表3种状态.validate_state主要检查不同STATE上下文的混用,也就是irq-safe/irq-unsafe这种操作.
LOCK_USED_IN_SOFTIRQ, LOCK_USED_IN_SOFTIRQ_READ, LOCK_ENABLED_SOFTIRQ, LOCK_ENABLED_SOFTIRQ_READ, LOCK_USED_IN_RECLAIM_FS,
LOCK_USED_IN_RECLAIM_FS_READ, LOCK_ENABLED_RECLAIM_FS, LOCK_ENABLED_RECLAIM_FS_READ, LOCK_USED, LOCK_USAGE_STATES}
validate_chain
1.遍历当前进程held_lock数组,和当前要持有的held_lock信息进行比对.
2.在比对过程中,查找两个held_lock是否可能产生环,会遍历其中一个held_lock的before/after链,并迭代链上的lock_class形成一棵树来查找是否有符合的lock_class.
3.它主要检查两种情形:锁之间的依赖关系是否会形成死锁,锁的STATE是否合法,即硬中断和软中断的几种状态是否进行了混用.
validate_chain
lookup_chain_cache //即将获得的lock和上一次的lock是否已经通过lock_chain关联,没有关联就进行下面的关联,否则直接返回
check_deadlock //检查当前task_struct的held_locks栈是否有AA锁
check_prevs_add //添加依赖关系
for (;;) {
hlock = curr->held_locks + depth - 1; //遍历当前held_locks的栈,添加和next的关联关系
check_prev_add(hlock, next..)
depth--;
}
check_prev_add的逻辑:
check_prev_add
check_noncircular(&this, hlock_class(prev), &target_entry); //检查是否形成环形
check_prev_add_irq //检查上下文是否一致
add_lock_to_list(hlock_class(prev), hlock_class(next), //next lock添加到prev的locks_after链表上
&hlock_class(prev)->locks_after);
add_lock_to_list(hlock_class(next), hlock_class(prev), //prev lock添加到next的locks_before链表上
&hlock_class(next)->locks_before);
lockdep nest锁:
同一类(对应相同 key 值)的多个锁同时持有时,Lockdep 会误报“重复上锁”的警告。这类操作中典型的是dentry层级遍历时,dentry共享同一个锁类,当遍历A目录下的B,C,D文件,因为在A层级已经拿到过锁了,所以在B,C,D中尝试拿锁时lockdep会以为是重复的AA锁.此时就需要使用spin_lock_nested 这类 API 设置不同的子类来区分同类锁,消除警告。
lockdep日志的分析
lockdep的日志非常人性化,我们可以通过错误提示就能知道发生了哪些错误,唯一难理解的是它的状态显式,它使用了’.-+?’,下面进行摘自内核文档Documentation/locking/lockdep-design.txt
modprobe/2287 is trying to acquire lock:
(&sio_locks[i].lock){-.-...}, at: [] mutex_lock+0x21/0x24
but task is already holding lock:
(&sio_locks[i].lock){-.-...}, at: [] mutex_lock+0x21/0x24
注意大括号内的符号,一共有6个字符,分别对应STATE和STATE-read这六种(因为目前每个STATE有3种不同含义)情况,各个字符代表的含义分别如下:
‘.’ acquired while irqs disabled and not in irq context
‘-‘ acquired in irq context
‘+’ acquired with irqs enabled
‘?’ acquired in irq context with irqs enabled.
参考:
内核文档:Documentation/locking/lockdep-design.txt
魅族团队的文档:http://kernel.meizu.com/linux-dead-lock-detect-lockdep.html
lenky的博客:http://www.lenky.info/archives/2013/04/2253
United States Patent 8145903:Method and system for a kernel lock validator
http://www.freepatentsonline.com/8145903.html
但是目前很少见有人用它的,毕竟在用户层的并发场景比较少,不像内核中公用相同的地址空间,不同的上下文切换,迄今为止在工作中还没有遇到使用lockdep的应用层框架,有时间了可以再去看一下它的使用场景.
应用层的lockdep:https://lwn.net/Articles/536363/