《操作系统导论》期末复习总结
操作系统复习指南
听说老师给出了这个复习指南,经过一遍复习之后, 发现好像整本书的内容都包括在里面了, 我要这个复习指南有何作用?
文章目录
-
操作系统复习指南 - 1.CPU 调度算法
- 2.进程和线程
- 进程API
- 线程API
- 3.并发同步
- 死锁:
- 4.地址空间
- 分配:
- 释放:
- 常见错误:
- 5.同步原语
- 锁:
- 实现锁
- 控制中断
- TestAndSet
- FetchAndAdd
- 实现公平不自旋锁
- 条件变量
- 信号量
- 实现信号量
- 信号量实现条件变量
- 二值信号量(锁)
- 生产者消费者
- 基于条件变量和锁
- 基于信号量
- 6.分段与分页
- **动态重定位**:
- 分段:
- 分页:
- 例子:
- 7.TLB, 多级页表
- 解决问题1: 慢
- TLB:
- 原理(注意加粗, ** **):
- 缓存:
- 问题里面的问题:
- TLB覆盖问题:
- TLB的替换策略:LRU
- 解决问题2: 页表很大!
- 更大的页
- 分段+分页
- 多级页表
- 8.页面置换算法
- FIFO
- LRU
- 近似LRU
- clock算法
- ARC算法
- 9.磁盘驱动器
- 10.磁盘调度算法
- SJF
- SSTF
- SCAN
- SPTF
- 11.RAID
- RAID0
- RAID1
- RAID4
- RAID5
- 性能比较:
- 12.文件系统接口
- 13.操作系统历史
- 14.其它
1.CPU 调度算法
了解CPU 调度算法,如先到先服务、最短作业优先、轮转、多级反馈队列等调度算法,
以及掌握多处理器调度的特殊性。
T周转时间 = T完成时间 - T 到达时间
FIFO: 平均周转时间很大
SJF: 当一个长时间的任务先到达时,平均周转时间也会很大, 因为不能停止执行。
STCF: 放宽假设条件, 进程可以上下切断, 周转时间很好。
T响应时间 = T首次运行 - T 到达时间
STCF 的响应时间不好 , 引入RR。
RR:根据时间片切换进程,均摊上下文切换成本,RR响应时间好, 但周转时间不好, 陷入死循环。。。
于是引入MLFQ, 综合解决两个问题。
MLFQ:
-
相同优先级的进程按RR调度
-
如果 优先级 A > B , 先运行A
-
初始工作时,放到最高优先级队列中
-
- 工作用完优先级后,降低优先级
- 如果在工作在时间片内主动释放cpu, 优先级不变
-
经过一段时间,重新把所有的的进程放到最高优先级
进程可能恶意每次都在快运行完的时候主动释放cpu, 因此,更改第四条如下
- 如果进程用完了,一个优先级上的时间片段, 则降低优先级,无论是否主动释放cpu
确保每一个工作获得一定的比例的cpu时间, 而不是优化cpu的周转时间和响应时间, 引入比例份额调度。
彩票调度: 按彩票的数量多少来运行程序, 彩票多概率大运行多,当任务短的时候,有随机性, 引入步长调度
步长调度: 步伐短运行地多,无论怎样都是按比例,缺点是需要全局状态, 当一个新的进程加入时, 要更新全部进程的当前步长, 彩票调度只需要一个全局变量,总的彩票数。
多处理器调度: 处理缓存一致性问题, 硬件上,cpu监听总线更改缓存,软件上:
单队列调度(SQMS): 简单,但是缓存不亲和
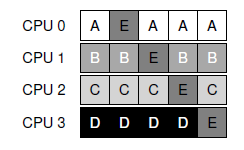
多队列调度(MQMS):天生缓存亲和, 但负载不均衡!(工作窃取)

上图可以看出, A进程独占cpu, 工作窃取,就是定时查看其他cpu的工作负载。
2.进程和线程
掌握进程和线程的概念,熟练使用进程和线程相关编程接口,如fork,exec,wait,
pthread_create,pthread_join等。
进程API
进程就是运行中的程序, 一个进程可以创建多个线程。
进程之间不共用内存, 线程之间可以共用内存, 但每一个线程都有自己的堆栈。
- fork()
子进程改变全局变量不会改变父进程的值, 子进程有自己的程序运行空间, copy自父进程
#include - waidpid()
#include rc = wc
fork 用作相同程序的拷贝作用,执行不同的程序时, 可以用
- exec()
#include // todo
线程API
#include 3.并发同步
掌握进程并发同步相关概念,如死锁、活锁等概念,真实应用中存在的不同类型的同步
问题,熟练使用pthread库中的相关同步函数进行编程。
题目说,进程并发同步的相关概念, 让我对进程和线程的理解再次产生怀疑,首先再次总结一下:
进程是为运行中的程序提供的一个抽象,线程是为单个运行的进程提供的抽象,多线程程序有多个执行点, 每个线程类似于进程, 唯一的区别是: 线程之间共享地址空间,能够访问相同的数据(在堆上的数据或者全局变量, 不是局部变量)。
非死锁:
- 违反原子性
- 违反顺序缺陷
死锁:
产生原因:
-
组件之间会有复杂的依赖
-
模块化会封装细节
解决方案:
所有的线程获取锁的顺序如果是相同的就不会产生死锁
产生条件:
- 互斥
使用硬件支持, 使用不用锁的数据结构!
- 持有并等待
或取多个锁时: 可以用一个把大的锁锁住, 即使防止获取锁的过程中,上下文切换!
- 非抢占
获取第一个锁后,查看第二个锁是否被占有, 如果占有直接放弃第一个锁,再次获取第一个锁, 这样存在一个问题, 两个锁一直重复这个问题, 倒置活锁
- 循环等待
锁的获取按照一定的顺序获取等待
4.地址空间
掌握地址空间的概念,以及用户态堆内存的管理。
一个进程的地址空间应该包含运行的程序的所有内存状态,操作系统给程序的抽象, 包括代码块, 堆,栈,真实的物理空间可能在任意的地方,地址空间是连续的0KB -> 16KB 。如下图:
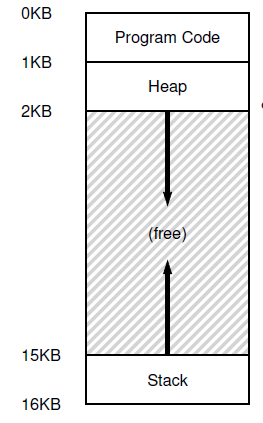
所谓堆内存(属于地址空间), 申请和释放都是又程序猿自己自己自己完成(注意这里操作的是地址空间,虚拟的)。java不用
分配:
void malloc(size_t size) , size大小一般为宏来设定, 比如 sizeof(double), 注意 void 的返回类型 是返回地址的指针,可以强转, 如下:
int *x = malloc(sizeof(int));
释放:
free(x) , 分配的大小不会被用户传入, 必须由内存分配库本身记录追踪。
常见错误:
-
忘记分配内存(这个常犯, 常犯, 给一个指针赋值!!!!指针是存放在栈中的, 4个字节的)
-
没有分配足够的内存
-
忘记初始化分配的内存, NULL 一般输出为 0, 但0 不等于 NULL ,默认都是0
-
忘记释放内存(这个我一般都不是释放 ^ _ ^,web、操作系统等长时间运行的程序一定需要!!)
-
反复释放内存(内存都不释放, 这个绝对不会发生的)
-
用完之前释放内存
-
错误调用free(), 参数传入错误的值。
5.同步原语
掌握锁、条件变量、信号量三种同步机制(熟练使用pthread库中的函数),并使用这些
机制解决实际应用问题,如生产者消费者问题。
锁:
锁就是一个变量, 锁为程序员提供了最小程度的调度控制,线程是操作系统的cpu调度的最小单位。
实现锁
控制中断
通过控制中断, 让代码原子执行
缺点很多, 不支持多cpu, 出现系统问题,操作系统需要控制中断来获取控制权。。。
TestAndSet
这条指令基于硬件的支持,等价于下面代码是原子执行的:
int TestAndSet(int *old_ptr, int new){
int *old = old_ptr;
*old_ptr = new;
return old;
}
实现自旋锁
typedef struct lock_t {
int flag;
} lock_t;
void lock_init(lock_t *lock) {
lock->flag = 0;
}
void lock(lock_t *lock){
while(TestAndSet(&lock->flag, 1) == 1);
//上面会一直自旋,浪费cpu资源, 也可能一直自旋永远得不到执行
}
void unlock(lock_t * lock){
lock->flag = 0;
}
FetchAndAdd
这也是一个硬件支持的原语,这一条指令等价于下面原子执行
FetchAndAdd(int *ptr){
int old = *ptr;
*ptr = old + 1;
return old;
}
实现一个公平的自旋锁
typedef struct lock_t {
int ticket;
int turn;
} lock_t;
void lock_init(lock_t *lock) {
lock->ticket = 0;
}
void lock(lock_t *lock){
int myturn = FetchAndAdd(&lock->ticket);
// 这里每一一次测试都会增加, 让每一个线程都能得到执行!
while(lock->trun != myturn);
//这里还是会自旋
}
void unlock(lock_t *lock){
FetchAndAdd(&lock->turn);
}
上面硬件原语的支持虽然实现了简单的公平锁, 但是它会自旋,下面实现不自旋的公平锁
实现公平不自旋锁
typedef struct __lock_t {
int flag;
int guard;
queue_t *q;
} lock_t;
void lock_init(lock_t *m) {
m->flag = 0;
m->guard = 0;
queue_init(m->q);
}
void lock(lock_t *m) {
while (TestAndSet(&m->guard, 1) == 1);
// 这里虽然也会自旋, 但是这个guard,在一个线程获取锁后(后面的else),guard也设置成了0,
//也就是说,即使已经有线程获取了锁, 这条指令还是有可能通过的, 不会一直在这里自旋,只会自旋几个周期
// guard的作用是保证后面的flag的设置是原子进行的
// 这里保证的原子的执行了, 因为其它指令的gurad为1,进不来这里, 不会有两个线程同时进入这里
if (m->flag == 0) {// 如果能获取到锁
m->flag = 1;
m->guard = 0;// 重置为0
} else {// 如果没有获取到锁
queue_add(m->q, gettid());// 加入队列,休眠队列
m->guard = 0;// guard这里也重置为0
park();
//这个是操作系统提供给程序员的函数, 休眠自己,在c语言中, 每种操作系统可以提供不同的
//函数库供程序猿调度,在 java统一为yeild(), linux中使用c也为 yeild()
}
}
void unlock(lock_t *m) {
while (TestAndSet(&m->guard, 1) == 1); //通过自旋获取guard
if (queue_empty(m->q))
m->flag = 0; // 空的话flag直接设置0
else
unpark(queue_remove(m->q));
// 这里并没有将 flag设置0, 因为要保证公平性, 按照队列的线程来进行唤醒,这样
// 队列里的每一个线程都能够得到执行,直接将flag的1 使用权传给了队列的第一个线程
m->guard = 0;
}
这段代码还有一个很微妙的竞态条件:
queue_add(m->q, gettid());
m->guard = 0;
park();
假设这段代码执行完前两句语句, 此时guard 变成了0, 释放锁的线程可以运行了, 而这个线程已经在休眠队列里面,但是它却还没有休眠, 这是如果唤醒了它,相当于白唤醒, 之后它执行park又再次休眠,而没加入队列里面了。结果就是永久休眠。 所以linux的实现有一个再次确认的代码!!!
linux 也是使用这种思想, 但是提供的原语不同。
锁的实现已经完成了,但是还有一种情况,当父进程等待子进程结束的时候,就要用到下面的同步原语:
条件变量
pthread_cond_wait(pthread_cond_t *c, pthread_mutex_t *m);
pthread_cond_signal(pthread_cond_t *c);
实现子进程等带父进程:
int done = 0;
pthread_mutex_t m = PTHREAD_MUTEX_INITIALIZER;
pthread_cond_t c = PTHREAD_COND_INITIALIZER;
void thr_exit() {
Pthread_mutex_lock(&m);
done = 1;
Pthread_cond_signal(&c);
//唤醒因为条件c而休眠你的线程
Pthread_mutex_unlock(&m);
}
void *child(void *arg) {
printf("child\n");
thr_exit();
return NULL;
}
void thr_join() {
Pthread_mutex_lock(&m);
//为什么要锁呢? 因为下面wait函数有释放锁!!!!!!!!!!!
while (done == 0)
Pthread_cond_wait(&c, &m);
/**
1、 这里要使用一个done来标记时候是否完成, 如果不用, 子进程先于父进程完成的时候,就会卡主
因为子进程已经过了唤醒父进程,而父进程又重新休眠,这样没有线程唤醒父进程
2、当调用了这条命令之后, 线程首先会将** 锁释放 **,然后调用线程休眠自己,(原子操作)
3、要用while, 而不能用if,在这里使用if正确, 但是有多个信号的时候, 可能会出现1 的情况
*/
Pthread_mutex_unlock(&m);
}
int main(int argc, char *argv[]) {
printf("parent: begin\n");
pthread_t p;
Pthread_create(&p, NULL, child, NULL);//创建新的线程
thr_join(); //等待子线程完成
printf("parent: end\n");
return 0;
}
书上没有给出条件变量的实现方法,但是通过其功能描述结合锁的实现应该也略知一二!
信号量
信号量是dijkstra提出的,可以用作为锁和条件变量, 让同步原语更加通用。
信号量是一个整形数值的对象, 下面是POSIX库的使用。
#incldue 实现信号量
基于锁和信号量
typedef struct Zem_t {
int value;
pthread_cond_t cond;
pthread_mutex_t lock;
} Zem_t;
void Zem_init(Zem_t *s, int value) {
s->value = value;
Cond_init(&s->cond);
Mutex_init(&s->lock);
}
void Zem_wait(Zem_t *s) {
Mutex_lock(&s->lock);
while (s->value <= 0)//当初始化的value小于等于0 的时候等待当前的线程
Cond_wait(&s->cond, &s->lock);
s->value--; // value 减去1不能放到上面,原因在下面
Mutex_unlock(&s->lock);
}
void Zem_post(Zem_t *s) {
Mutex_lock(&s->lock);
s->value++; //唤醒一个等待着的线程,对应的value 加上1
Cond_signal(&s->cond);
Mutex_unlock(&s->lock);
}
看了实现之后, 很容易就能用一个信号量实现一个锁
信号量实现条件变量
sem_t s;
void *child(void *arg) {
printf("child\n");
sem_post(&s);
return NULL;
}
int main(int argc, char *argv[]) {
sem_init(&s, 0, 0); // 这里初始化为0,
printf("parent: begin\n");
pthread_t c;
Pthread_create(&c, NULL, child, NULL);
sem_wait(&s);
/*
有两种情况考虑:
1、 当父进程线运行时, 信号量的值为0,休眠自己,此时不会减去1
子进程运行post的时候,唤醒了父进程,value加上了1,变成1
********* 父进程继续运行,减去1 , 信号量重新变为0, 这就是value - 1 不能放上面的原因!!
2、 当子进程先运行的时候, value加上了1, 等于1
当父进程运行的时候, value为1, 不用等了
*/
printf("parent: end\n");
return 0;
}
二值信号量(锁)
初始化信号量的值为1,这就实现了一个锁!!!
当有一个进程获取锁之后, value 就变成了0, 其它线程要进入必须等待被唤醒。
当有多个线程在休眠时, 多个线程同时被唤醒, 多个线程会抢占锁,谁先抢到谁先起来, 这里应该是存在不公平现象的, 有可能有些线程一直得不到执行!???????应该只有一个线程会被唤醒!!!???
上面理解错误!!!!不会有多个被唤醒的情况, 条件变量目前只有一个在等待
应该是按照fifo来的
生产者消费者
基于条件变量和锁
int buffer[MAX];
int fill_ptr = 0;
int use_ptr = 0;
int count = 0;
void put(int value) {
buffer[fill_ptr] = value;
fill_ptr = (fill_ptr + 1) % MAX;
count++;
}
int get() {
int tmp = buffer[use_ptr];
use_ptr = (use_ptr + 1) % MAX;
count--;
return tmp;
}
cond_t empty, fill;
mutex_t mutex;
/*
这里要使用两个条件变量, 如果只使用一个, 而条件变量的唤醒不是按照队列来的,这时
假设有两个消费者因为没有count休眠
而生产者生产满了之后, 就去休眠了, 等待唤醒
此时一个消费者先被唤醒,消费完count后, 唤醒了另一个消费者,发现count已经没了,也去休眠,
此时没人唤醒生产者了。。。
*/
void *producer(void *arg) {
int i;
for (i = 0; i < loops; i++) {
Pthread_mutex_lock(&mutex); // p1
while (count == MAX) // p2
Pthread_cond_wait(&empty, &mutex); // p3
put(i); // p4
Pthread_cond_signal(&fill); // p5
Pthread_mutex_unlock(&mutex); // p6
}
}
void *consumer(void *arg) {
int i;
for (i = 0; i < loops; i++) {
Pthread_mutex_lock(&mutex); // c1
while (count == 0) // c2
Pthread_cond_wait(&fill, &mutex); // c3
/*
这里使用while,而不是if, 原因:
当有多个消费者时, 其中一个消费者先运行,发现count = 0,休眠, 接下来生产者生产一个
count = 1, 这时另一个消费者运行, 把数据取走, 此时count = 0; 假设接下来是
刚才那个休眠的消费者继续运行,此时count已经是0了, 而如果使用if, if只会判断一次,
刚才休眠的时候已经判断过了,所以这个消费者会继续运行, count -= 1; = -1!!!
所以要使用while , while 会重新回来判断!!
*/
int tmp = get(); // c4
Pthread_cond_signal(&empty); // c5
Pthread_mutex_unlock(&mutex); // c6
printf("%d\n", tmp);
}
}
基于信号量
void *producer(void *arg) {
int i;
for (i = 0; i < loops; i++) {
sem_wait(&mutex); // Line P0 (NEW LINE)
sem_wait(&empty); // Line P1
put(i); // Line P2
sem_post(&full); // Line P3
sem_post(&mutex); // Line P4 (NEW LINE)
}
}
void *consumer(void *arg) {
int i;
for (i = 0; i < loops; i++) {
sem_wait(&mutex); // Line C0 (NEW LINE)
sem_wait(&full); // Line C1
int tmp = get(); // Line C2
sem_post(&empty); // Line C3
sem_post(&mutex); // Line C4 (NEW LINE)
printf("%d\n", tmp);
}
}
6.分段与分页
掌握虚拟内存管理中的分段与分页机制的原理,以及比较其优缺点。
动态重定位:
基于硬件的动态重定位,使用内存管理单元(MMU)给地址空间分配内存,效率低下, 造成很多内部碎片(图中allocated but not use)。

分段:
因此引入分段解决内部碎片问题:MMU给地址空间内的每一个逻辑段都分配内存。
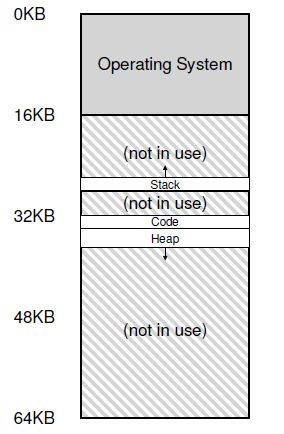
段的引用: 显示方式
于是乎, 在内存上产生很多外部碎片, 解决方法,基于空闲列表 和 各种管理算法:
这里我觉得不会考,但列一列:
-
最优匹配
-
最差匹配
-
首次匹配
-
下次匹配
-
分离空闲列表:经常申请的内存空间,给它一个独立的列表
-
伙伴系统: 二分分配, 合并和分配的时候很方便, 二进制与二叉树的巧合
可以看出分段会产生外部碎片, 这是一个很根本的问题,不通用, 即使有管理内存算法!
以上不会考的,应该考二级页表!
分页:
分页不是将一个地址空间按逻辑段分, 而是分割成固定大小的单元,称为 页帧。
页表: 记录每一个地址空间的每一个虚拟页(页帧)在物理内存中的位置,页表是每一个进程数据结构。
物理帧号(PFN)或称 物理页号(PPN physical page number): 真实的物理 页帧 地址。
- 地址空间划分:

- 物理地址划分

页表项(PTE page table entry): 记录 PFN
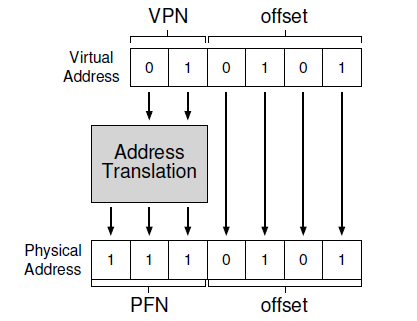
上图中中间的地址转换(address translation)就通过页表来存储!!
例子:
地址空间 地址 21 -> 010101 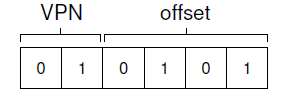
从物理地址 ( 01 推出 )中拿出PTE,取出 PFN 得到地址空间的真实的物理地址, 偏移量不变, 因为页帧一样大。
如何拿出对应的PTE:
VPN = (VirtualAddress & VPN_MASK) >> SHIFT //取出VPN
PTEAddr = PageTableBaseRegister + (VPN * sizeof(PTE)) // 算出物理地址, 拿到PTE的物理地址
于是呢, 有两次的内存访问, 慢!
页表存放:
简单的存放线性页表, 32 位的地址空间, 4KB(2^ 12)的页大小(大部分os,windows,linux),PTE个数:2^32 / 2^12 = 2^20, PTE大小(假设)4B, 线性页表大小 4B * 2^20 = 4MB, 所以一个进程就 4MB内存, 10个就==。。。==
以上就是页表的两个缺点!
先比较优缺点:
| 策略 | 优点 | 缺点 |
|---|---|---|
| 分段 | 很好支持稀疏地址空间,很快,算法简单,适合硬件完成,地址转换的开销极小, 代码共享(如果代码独立的段中,可以被多个运行程序共享)。 | 不支持一般化的稀疏地址,产生外部碎片问题很根本,难以避免,随时间推移,管理难,分配也困难。 |
| 分页 | 不会导致外部碎片, 很灵活,支持稀疏的地址空间 | 速度较慢,要两次访问内存,有可能产生内存浪费 |
7.TLB, 多级页表
掌握TLB 与多级页表,掌握多级页表相关的计算,比如根据地址位、页面大小、PTE 大
小等条件,进行虚拟地址到物理地址的转换;掌握多级页表的访问过程。
第6点的页表的两个问题需要解决!
解决问题1: 慢
TLB:
TLB(地址转换旁路缓冲储存器)也叫 地址转换缓存, 频繁发生虚拟到物理地址的硬件缓存。
原理(注意加粗, ** **):
VPN = (VirtualAddress & VPN_MASK) >> SHIFT
(Success, TlbEntry) = TLB_Lookup(VPN) // TLB里面找VPN对应的物理地址
if (Success == True) // TLB Hit
if (CanAccess(TlbEntry.ProtectBits) == True)
Offset = VirtualAddress & OFFSET_MASK
PhysAddr = (TlbEntry.PFN << SHIFT) | Offset
Register = AccessMemory(PhysAddr) // 直接从** 缓存地址**中拿到实际的物理地址
else
RaiseException(PROTECTION_FAULT)
else // TLB Miss
PTEAddr = PTBR + (VPN * sizeof(PTE))
PTE = AccessMemory(PTEAddr) //没有找到就多了一次PTE ** 内存 **的寻址, 多了一次一次就一次
if (PTE.Valid == False)
RaiseException(SEGMENTATION_FAULT)
else if (CanAccess(PTE.ProtectBits) == False)
RaiseException(PROTECTION_FAULT)
else
TLB_Insert(VPN, PTE.PFN, PTE.ProtectBits)
RetryInstruction()
缓存:
计算机中有很多缓存,有指令、数据、地址转换, 上面是地址转换的缓存TLB,缓存要小,越小越快(物理限制),有时间和空间局部性。cpu的数据缓存也分为多级。
曾看到一道题, TLB 和 cache 有什么不同????
问题里面的问题:
当TLB中有两条相同的VPN索引两个不同的物理地址, 可以通过ASID标记(进程号)来标记, 这样就不用覆盖掉之前的VPN了, 当两个进程交互运行时, 相同的VPN可以存在于TLB中,还是上一张图。

TLB覆盖问题:
如果程序短时间内访问的页数超过了 TLB中的页数, 会产生大量未命中,因为要重写,因此要支持更大的页, 才不会访问很多页!!
TLB的替换策略:LRU
难道是问题8的? 不是的,问题8是页的替换, 这里是TLB的替换,思路应该一样的!!
听说腾讯的面试有要求写一个LRU算法! 基于哈希,哈希每次访问的地址,用一个链表存储哈希后的地址数值,有新的访问就把他放到链表的头结点(包括在链表中的),满了删队尾。(脑子里想起链表的操作删除,插入操作)
解决问题2: 页表很大!
更大的页
页变大, 页表条目减少, 页表也就小了, 但是页变大有内部碎片产生!因为每一页都用不完积累就多
分段+分页
分段与分页相结合,外部碎片再次产生, 页表就是为了解决外部碎片的!!!分段产生外部碎片的根源,无可避免!!
多级页表
于是乎,只有引入多级页表:
问题所在: 页表中存在很多无效区域。
基本思想:将页表分成页大小的单元,如果整页的PTE无效,就完全不分配该页的页表(很重要!)于是引入:
PDE(页目录): 记录页表的页是否有效, 包含有效位和页帧号。
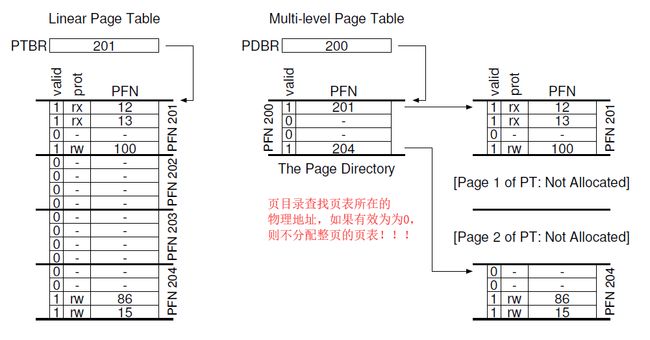
详细深入具体仔细的一个书上的例子: 完美非无可增,乃不可减,老师说必考。
首先题目: 地址空间 16KB(2^14),地址位数14位, 页大小 64B(2^6), 偏移位数6 位,VPN位数: 14 - 4 = 8 位,页表项条数为 2^8条 , PTE的大小为 4B(假设),如果是线性页表大小为: 4 * 256B = 1KB,如果分配到PDE中, 每页存 64B/4B = 16 条PTE,一共要256/16 = 16页来存储PTE,于是页目录的索引要 4位(来自黄色的数字),如下图:
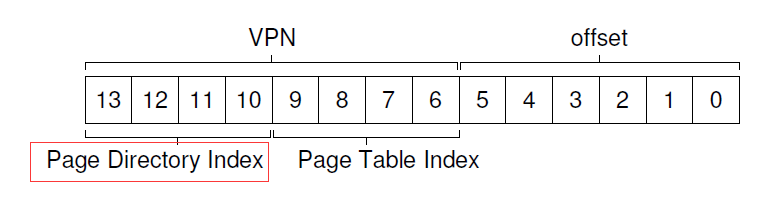
计算PTE的PFN算法:
PDEAddr = PageDirBase + (PDIndex(4位就可以找到!) - sizeof(PDE))
于是找到了PTE所在的物理页帧PFN!(第一步)
因为VPN一共8位, 找PTE所在的页用了4位, 还有4位就索引属于该页所有的PTE的那一条(来自红色的数字)!
通过下面的这条式子找到, 实际物理地址的PFN!(第二步)
PTEAddr = (PDE.PFN << SHIFT) + (PTIndex * sizeof(PTE))
最后,计算实际的物理地址!
PhysAddr = (PTE.PFN << SHIFT) + offset
总结,二级页表的访问内存数目达到了两次,访问速度慢, 但是解决了页表大的问题, 是一个时空的折中。
8.页面置换算法
掌握页面置换算法,比如FIFO,LRU等,要求能根据给定的页面访问序列,给出特定算
法的计算过程;掌握CLOCK算法。
这一块课,没有去听,^ _ ^
FIFO
这个好实现, 先进先出,用一个队列就行!
LRU
这个在TLB的替换页面中写了。
LRU 也有问题, 当内存大的时候, LRU的实现代价很大,比如存储LRU的数据结构,因此引入一个近似LRU:
近似LRU
近似LRU 要硬件的帮助, 给页增加一个使用位, 如果为1, 则认为当前页正在被使用。
clock算法
算法思路: 当要进行页替换的时候,检查当前的页的使用位,如果为1, 则意味着当前页在被使用,不适合替换,然后将这个位设置为0, 接着检查下一个页的使用位。 如果为0, 则直接替换。 算法的最坏情况是所有的页都是在被使用的, 把所有的1 都换为 0, 此时再来一遍循环选第一个替换, 实际上这种情况很少出现!
ARC算法
书上没有介绍!
//todo
9.磁盘驱动器
掌握磁盘寻道、旋转、传输时间的概念及计算过程。
寻道: 就是寻道,一般有偏斜
旋转:就是旋转
T I/O = T 寻道 + T 旋转 + T 传输
RI/O(传输速度) = 文件大小 / T I/O
10.磁盘调度算法
了解各种磁盘调度算法的原理。
SJF
最短任务优先, 计算 I/O的时间,选择最短的!
SSTF
最短寻道时间优先, 可能产生饥饿,一直在同一道内请求
SCAN
到一层的时候, 将请求加入队列, 处理完再寻道,这样避免饥饿
SPTF
最短定位时间
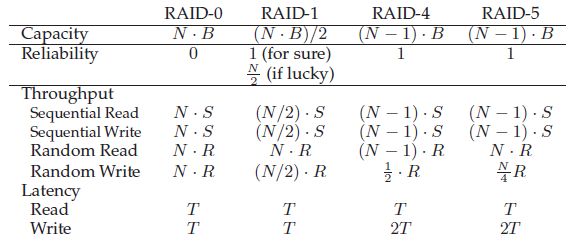
11.RAID
掌握磁盘阵列RAID-0,RAID-1,RAID-4,RAID-5的原理,并分析各种RAID在容量、可
靠性、吞吐量三个层面的特性。熟练使用RAID的这些特性进行设计。
RAID: 廉价冗余磁盘阵列
用于使用多个磁盘构建更大、更快、更可靠的磁盘系统
RAID0
条带化

计算公式:
Disk = A % number_of_disks
Offset = A / number_of_disks
容量最好, 性能优, 不可靠!
RAID1
一半用作镜像

容量减半, 速度也减半, 因为并发io,少了一半,可靠!
RAID4
专门用一个磁盘用来奇偶校验
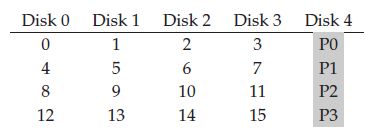
可靠, 速度(n-1)S, 容量大
当一校验盘同时有两个块需要校验时, 速度会减慢, 因此引入:
RAID5
旋转奇偶校验

可靠, 速度(n-1)S,容量大
性能比较:
12.文件系统接口
了解文件系统接口,如open,read,write,在实现时对元数据和文件内容的读写过程。
都说不考喽!!!
13.操作系统历史
了解课堂上讲到的跟操作系统发展史相关的重要人物,并能介绍其主要贡献。
- 图灵
计算机之父
- 冯·诺伊曼
提出了“存储程序”的概念和二进制原理
- linus
编写第一个linux
- 阿兰·马西森·图灵(1912-1917年6月23日)
他在计算机科学的发展,提供概念的形式化“算法”和“计算”的图灵机,可以考虑通用计算机的模型。
图灵被广泛认为是理论计算机之父!
- Dijkstra
同步进程通信的信号量
- Thompson
用B语言写了第一个UNIX操作系统
14.其它
作业中的难点问题需要掌握其解题方法。
都包含在上面了。