Kubernetes 控制器:从 Kubernetes 资源控制到开放应用模型、工作原理解读
目录
从 Kubernetes 资源控制到开放应用模型
1. 控制循环
2. Informer
4. CRD
5. 自定义控制器
6. Operator
7. OAM
Kubernetes 控制器的工作原理解读
1. 控制器的模型
2. 水平触发的 API
3. 控制器的内部结构
Informer
Workqueue
从 Kubernetes 资源控制到开放应用模型
我是一堆 Kubernetes 控制器。
你可能会疑惑为什么是一堆,因为我不是一个人,我只是众多控制器中的一员,你也可以把我看成是众多控制器的集合。我的职责就是监控集群内资源的实际状态,一旦发现其与期望的状态不相符,就采取行动使其符合期望状态。
想当初,Kubernetes 老大哥创造我时,只是打算让我用控制循环简单维护下资源的状态。但我后来的发展,远远超出了他的想象。
1. 控制循环
 第一阶段:控制器直接访问api-server
第一阶段:控制器直接访问api-server
所谓控制循环就是一个用来调节系统状态的周期性操作,在 Kubernetes 中也叫调谐循环(Reconcile Loop)。我的手下控制着很多种不同类型的资源,比如 Pod,Deployment,Service 等等。就拿 Deployment 来说吧,我的控制循环主要分为三步:
- 从
API Server中获取到所有属于该 Deployment 的 Pod,然后统计一下它们的数量,即它们的实际状态。- 检查 Deployment 的
Replicas字段,看看期望状态是多少个 Pod。- 将这两个状态做比较,如果期望状态的 Pod 数量比实际状态多,就创建新 Pod,多几个就创建几个新的;如果期望状态的 Pod 数量比实际状态少,就删除旧 Pod,少几个就删除几个旧的。
然而好景不长,我收到了 Kubernetes 掌门人(看大门的) API Server 的抱怨:“你访问我的次数太频繁了,非常消耗我的资源,我连上厕所的时间都没有了!”
我仔细一想,当前的控制循环模式确实有这个缺陷——访问 API Server 的次数太频繁了,容易被老大反感。
所以我决定,找一个小弟。
2. Informer
 第二阶段:控制器通过informer访问api-server
第二阶段:控制器通过informer访问api-server
这次我招的小弟叫 Informer,它分担一部分我的任务,具体的做法是这样的:由 Informer代替我去访问 API Server,而我不管是查状态还是对资源进行伸缩都和 Informer 进行交接。而且 Informer 不需要每次都去访问 API Server,它只要在初始化的时候通过 LIST API 获取所有资源的最新状态,然后再通过 WATCH API 去监听这些资源状态的变化,整个过程被称作 ListAndWatch。
而 Informer 也不傻,它也有一个助手叫 Reflector,上面所说的 ListAndWatch 事实上是由 Reflector 一手操办的。
这一次,API Server 的压力大大减轻了,因为 Reflector 大部分时间都在 WATCH,并没有通过 LIST 获取所有状态,这使 API Server 的压力大大减少。我想这次掌门人应该不会再批评我了吧。
然而没过几天,掌门人又找我谈话了:“你的手下每次来 WATCH 我,都要 WATCH 所有兄弟的状态,依然很消耗我的资源啊!我就纳闷了,你一次搞这么多兄弟,你虎啊?”
我一想有道理啊,没必要每次都 WATCH 所有兄弟的状态,于是告诉 Informer:“以后再去 API Server 那里 WATCH 状态的时候,只查 WATCH 特定资源的状态,不要一股脑儿全 WATCH。“
Informer 再把这个决策告诉 Reflector,事情就这么愉快地决定了。
本以为这次我会得到掌门人的夸奖,可没过几天安稳日子,它又来找我诉苦了:“兄弟,虽然你减轻了我的精神压力,但我的财力有限啊,如果每个控制器都招一个小弟,那我得多发多少人的工资啊,你想想办法。”
3. SharedInformer
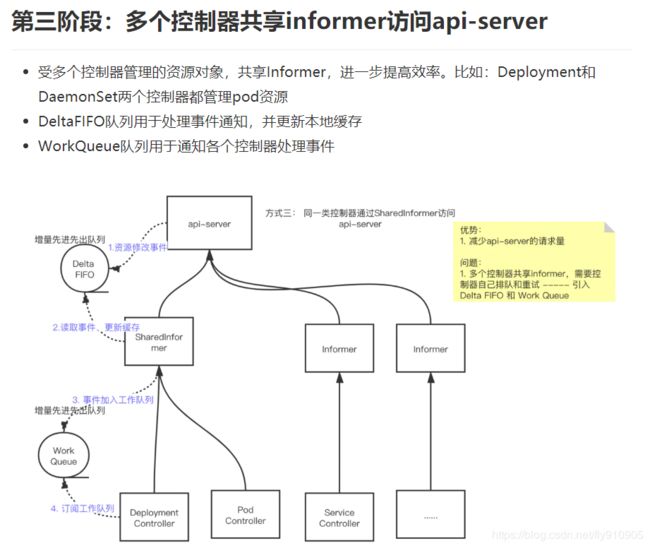 第三阶段:多个控制器共享informer访问api-server
第三阶段:多个控制器共享informer访问api-server
经过和其他控制器的讨论,我们决定这么做:所有控制器联合起来作为一个整体来分配 Informer,针对每个(受多个控制器管理的)资源招一个 Informer 小弟,我们称之为 SharedInformer。你们可以理解为共享 Informer,因为有很多资源是受多个控制器管理的,比如 Pod 同时受 Deployment 和 StatefulSet 管理。这样当多个控制器同时想查 Pod 的状态时,只需要访问一个 Informer 就行了。
但这又引来了新的问题,SharedInformer 无法同时给多个控制器提供信息,这就需要每个控制器自己排队和重试。
为了配合控制器更好地实现排队和重试,SharedInformer 搞了一个 Delta FIFO Queue(增量先进先出队列),每当资源被修改时,它的助手 Reflector 就会收到事件通知,并将对应的事件放入 Delta FIFO Queue 中。与此同时,SharedInformer 会不断从 Delta FIFO Queue 中读取事件,然后更新本地缓存的状态。
这还不行,SharedInformer 除了更新本地缓存之外,还要想办法将数据同步给各个控制器,为了解决这个问题,它又搞了个工作队列(Workqueue),一旦有资源被添加、修改或删除,就会将相应的事件加入到工作队列中。所有的控制器排队进行读取,一旦某个控制器发现这个事件与自己相关,就执行相应的操作。如果操作失败,就将该事件放回队列,等下次排到自己再试一次。如果操作成功,就将该事件从队列中删除。
现在这个工作模式得到了大家的一致好评。虽然单个 SharedInformer 的工作量增加了,但 Informer 的数量大大减少了,老大可以把省下来的资金拿出一小部分给 SharedInformer 涨工资啊,这样大家都很开心。
4. CRD
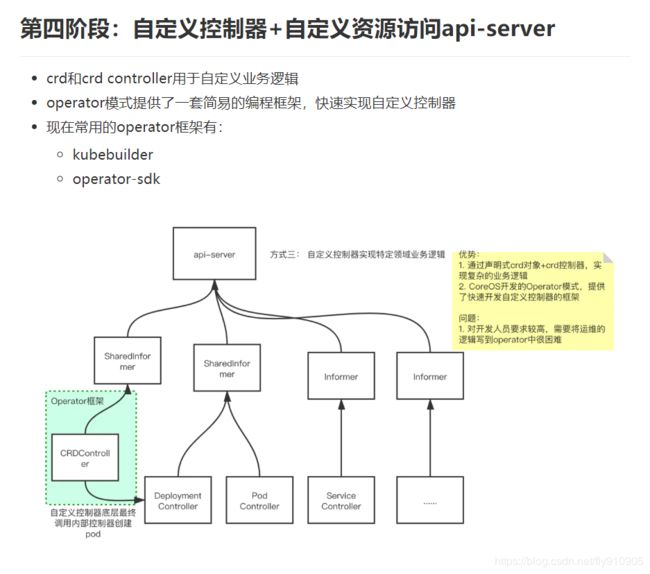 第四阶段:自定义控制器+自定义资源访问api-server
第四阶段:自定义控制器+自定义资源访问api-server
全民 Kubernetes 时代到了。
随着容器及其编排技术的普及,使用 Kubernetes 的用户大量增长,用户已经不满足 Kubernetes 自带的那些资源(Pod,Node,Service)了,大家都希望能根据具体的业务创建特定的资源,并且对这些资源的状态维护还要遵循上面所说的那一套控制循环机制。
幸好最近掌门人做了一次升级,新增了一个插件叫 CRD(Custom Resource Definition),创建一个全新的资源实例,只需要经过以下两步:
- 创建一个 CRD 资源(没错,CRD 也是一种资源类型),其中定义”自定义资源“的 API 组、API 版本和资源类型。这样就会向 API Server 注册该资源类型的 API。
- 指定上面定义的 API 组 和 API 版本,创建自定义资源。
当然,中间还要加入一些代码让 Kubernetes 认识自定义资源的各种参数。
到这一步就基本上完成了自定义资源的创建,但 Kubernetes 并不知道该资源所对应的业务逻辑,比如你的自定义资源是宿主机,那么对应的业务逻辑就是创建一台真正的宿主机出来。那么怎样实现它的业务逻辑呢?
5. 自定义控制器
Controller Manager 见多识广,说:”这里的每个控制器都是我的一部分,当初创造你们是因为你们都属于通用的控制器,大家都能用得上。而自定义资源需要根据具体的业务来实现,我们不可能知道每个用户的具体业务是啥,自己一拍脑袋想出来的自定义资源,用户也不一定用得上。我们可以让用户自己编写自定义控制器,你们把之前使用的控制循环和 Informer 这些编码模式总结一下,然后提供给用户,让他们按照同样的方法编写自己的控制器。“
Deployment 控制器一惊,要把自己的秘密告诉别人?那别人把自己取代了咋办?赶忙问道:”那将来我岂不是很危险,没有存在的余地了?“
Controller Manager 赶忙解释道:”不用担心,虽然用户可以编写自定义控制器,但无论他们玩出什么花样,只要他们的业务跑在 Kubernetes 平台上,就免不了要跑容器,最后还是会来求你们帮忙的,你要知道,控制器是可以层层递进的,他们只不过是在你外面套了一层,最后还是要回到你这里,请求你帮忙控制 Pod。“
这下大家都不慌了,决定就把自定义控制器这件事情交给用户自己去处理,将选择权留给用户。
6. Operator
用户自从获得了编写自定义控制器的权力之后,非常开心,有的用户(CoreOS)为了方便大家控制有状态应用,开发出了一种特定的控制器模型叫 Operator,并开始在社区内推广,得到了大家的一致好评。不可否认,Operator 这种模式是很聪明的,它把需要特定领域知识的应用单独写一个 Operator 控制器,将这种应用特定的操作知识编写到软件中,使其可以利用 Kubernetes 强大的抽象能力,达到正确运行和管理应用的目的。
以 ETCD Operator 为例,假如你想手动扩展一个 ETCD 集群,一般的做法是:
- 使用 ETCD 管理工具添加一个新成员。
- 为这个成员所在的节点生成对应的启动参数,并启动它。
而 ETCD Operator 将这些特定于 etcd 的操作手法编写到了它的控制循环中,你只需要通过修改自定义资源声明集群期望的成员数量,剩下的事情交给 Operator 就好了。
本以为这是一个皆大欢喜的方案,但没过多久,就有开发 Operator 的小哥来抱怨了:”我们有很多开发的小伙伴都是不懂运维那一套的,什么高可用、容灾根本不懂啊,现在让我们将运维的操作知识编写到软件中,臣妾做不到啊。。“
这确实是个问题,这样一来就把开发和运维的工作都塞到了开发手里,既懂开发又懂运维的可不多啊,为了照顾大家,还得继续想办法把开发和运维的工作拆分开来。
7. OAM
 第五阶段:Open Application Model(OAM)
第五阶段:Open Application Model(OAM)
这时候阿里和微软发力了,他们联合发布了一个开放应用模型,叫 Open Application Model (OAM)。这个模型就是为了解决上面提到的问题,将开发和运维的职责解耦,不同的角色履行不同的职责,并形成一个统一的规范,如下图所示:
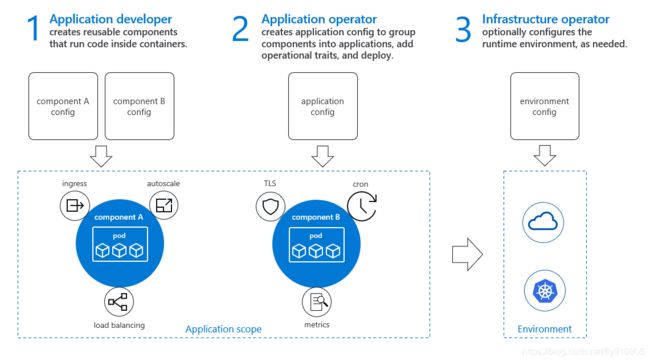 Open Application Model (OAM)
Open Application Model (OAM)
这个规范告诉我们:
- 开发人员负责描述组件的功能,如何配置组件,以及运行需要多少资源
- 运维人员负责将相关组件组合成一个应用,并配置运行时参数和运维支撑能力,比如是否需要监控,是否需要弹性伸缩。
- 基础设施工程师负责建立和维护应用的运行时环境(如底层系统)。
其中每一个团队负责的事情都用对应的 CRD 来配置。
这样一来,开发和运维人员的职责就被区分开来了,简化了应用的组合和运维。它将应用的配置和运维特征(如自动伸缩、流量监控)进行解耦,然后通过建模构成一个整体,避免了 Operator 这种模型带来的大量冗余。
自从用上了这个模型之后,运维和开发小哥表示现在他们的关系很融洽,没事还能一起出去喝两杯。
Kubernetes 控制器的工作原理解读
Kubernetes 中运行了一系列控制器来确保集群的当前状态与期望状态保持一致,它们就是 Kubernetes 的大脑。例如,ReplicaSet 控制器负责维护集群中运行的 Pod 数量;Node 控制器负责监控节点的状态,并在节点出现故障时及时做出响应。总而言之,在 Kubernetes 中,每个控制器只负责某种类型的特定资源。对于集群管理员来说,了解每个控制器的角色分工至关重要,如有必要,你还需要深入了解控制器的工作原理。
本文我将会带你深入了解 Kubernetes 控制器的内部结构、基本组件以及它的工作原理。本文使用的所有代码都是从 Kubernetes 控制器的当前实现代码中提取的,基于 Go 语言的 client-go 库。
1. 控制器的模型
Kubernetes 官方文档给出了控制器最完美的解释:
In applications of robotics and automation, a control loop is a non-terminating loop that regulates the state of the system. In Kubernetes, a controller is a control loop that watches the shared state of the cluster through the API server and makes changes attempting to move the current state towards the desired state. Examples of controllers that ship with Kubernetes today are the replication controller, endpoints controller, namespace controller, and serviceaccounts controller.
翻译:
在机器人设计和自动化的应用中,控制循环是一个用来调节系统状态的非终止循环。而在 Kubernetes 中,控制器就是前面提到的控制循环,它通过 API Server 监控整个集群的状态,并确保集群处于预期的工作状态。Kubernetes 自带的控制器有 ReplicaSet 控制器,Endpoint 控制器,Namespace 控制器和 Service Account 控制器等。
官方文档:Kube-controller-manager
Kubernetes 控制器会监视资源的创建/更新/删除事件,并触发 Reconcile 函数作为响应。整个调整过程被称作 “Reconcile Loop”(调谐循环)或者 “Sync Loop”(同步循环)。Reconcile是一个使用 object(Resource 的实例)的命名空间和 object 名来调用的函数,使 object 的实际状态与 object 的 Spec 中定义的状态保持一致。调用完成后,Reconcile 会将 object 的状态更新为当前实际状态。
什么时候才会触发 Reconcile 函数呢?以 ReplicaSet 控制器为例,当收到了一个关于 ReplicaSet 的事件或者关于 ReplicaSet 创建 Pod 的事件时,就会触发 Reconcile 函数。
为了降低复杂性,Kubernetes 将所有的控制器都打包到 kube-controller-manager 这个守护进程中。下面是控制器最简单的实现方式:
for {
desired := getDesiredState()
current := getCurrentState()
makeChanges(desired, current)
}
2. 水平触发的 API
Kubernetes 的 API 和控制器都是基于水平触发的,可以促进系统的自我修复和周期协调。水平触发这个概念来自硬件的中断,中断可以是水平触发,也可以是边缘触发。
- 水平触发 : 系统仅依赖于当前状态。即使系统错过了某个事件(可能因为故障挂掉了),当它恢复时,依然可以通过查看信号的当前状态来做出正确的响应。
- 边缘触发 : 系统不仅依赖于当前状态,还依赖于过去的状态。如果系统错过了某个事件(“边缘”),则必须重新查看该事件才能恢复系统。
Kubernetes 水平触发的 API 实现方式是:监视系统的实际状态,并与对象的 Spec 中定义的期望状态进行对比,然后再调用 Reconcile 函数来调整实际状态,使之与期望状态相匹配。
注意
水平触发的 API 也叫声明式 API。
水平触发的 API 有以下几个特点:
Reconcile会跳过中间过程在Spec中声明的值,直接作用于当前Spec中声明的值。- 在触发
Reconcile之前,控制器会并发处理多个事件,而不是串行处理每个事件。
举两个例子:
例 1:并发处理多个事件
用户创建了 1000 个副本数的 ReplicaSet,然后 ReplicaSet 控制器会创建 1000 个 Pod,并维护 ReplicaSet 的 Status 字段。在水平触发系统中,控制器会在触发 Reconcile 之前并发更新所有 Pod(Reconcile 函数仅接收对象的 Namespace 和 Name 作为参数),只需要更新 Status 字段 1 次。而在边缘触发系统中,控制器会串行响应每个 Pod 事件,这样就会更新 Status 字段 1000 次。
例 2:跳过中间状态
用户修改了某个 Deployment 的镜像,然后进行回滚。在回滚过程中发现容器陷入 crash 循环,需要增加内存限制。然后用户更新了 Deployment 的内容,调整内存限制,重新开始回滚。在水平触发系统中,控制器会立即停止上一次回滚动作,开始根据最新值进行回滚。而在边缘触发系统中,控制器必须等上一次回滚操作完成才能进行下一次回滚。
3. 控制器的内部结构
每个控制器内部都有两个核心组件:Informer/SharedInformer 和 Workqueue。其中 Informer/SharedInformer 负责 watch Kubernetes 资源对象的状态变化,然后将相关事件(evenets)发送到 Workqueue 中,最后再由控制器的 worker 从 Workqueue 中取出事件交给控制器处理程序进行处理。
注意
事件 = 动作(create, update 或 delete) + 资源的 key(以 namespace/name 的形式表示)
Informer
控制器的主要作用是 watch 资源对象的当前状态和期望状态,然后发送指令来调整当前状态,使之更接近期望状态。为了获得资源对象当前状态的详细信息,控制器需要向 API Server 发送请求。
但频繁地调用 API Server 非常消耗集群资源,因此为了能够多次 get 和 list 对象,Kubernetes 开发人员最终决定使用 client-go 库提供的缓存机制。控制器并不需要频繁调用 API Server,只有当资源对象被创建,修改或删除时,才需要获取相关事件。client-go 库提供了 Listwatcher 接口用来获得某种资源的全部 Object,缓存在内存中;然后,调用 Watch API 去 watch 这种资源,去维护这份缓存;最后就不再调用 Kubernetes 的任何 API:
lw := cache.NewListWatchFromClient(
client,
&v1.Pod{},
api.NamespaceAll,
fieldSelector)
上面的这些所有工作都是在 Informer 中完成的,Informer 的数据结构如下所示:
store, controller := cache.NewInformer {
&cache.ListWatch{},
&v1.Pod{},
resyncPeriod,
cache.ResourceEventHandlerFuncs{},
尽管 Informer 还没有在 Kubernetes 的代码中被广泛使用(目前主要使用 SharedInformer,下文我会详述),但如果你想编写一个自定义的控制器,它仍然是一个必不可少的概念。
注意
你可以把 Informer 理解为 API Server 与控制器之间的事件代理,把 Workqueue 理解为存储事件的数据结构。
下面是用于构造 Informer 的三种模式:
ListWatcher
ListWatcher 是对某个特定命名空间中某个特定资源的 list 和 watch 函数的集合。这样做有助于控制器只专注于某种特定资源。fieldSelector 是一种过滤器,它用来缩小资源搜索的范围,让控制器只检索匹配特定字段的资源。Listwatcher 的数据结构如下所示:
cache.ListWatch {
listFunc := func(options metav1.ListOptions) (runtime.Object, error) {
return client.Get().
Namespace(namespace).
Resource(resource).
VersionedParams(&options, metav1.ParameterCodec).
FieldsSelectorParam(fieldSelector).
Do().
Get()
}
watchFunc := func(options metav1.ListOptions) (watch.Interface, error) {
options.Watch = true
return client.Get().
Namespace(namespace).
Resource(resource).
VersionedParams(&options, metav1.ParameterCodec).
FieldsSelectorParam(fieldSelector).
Watch()
}
}
Resource Event Handler
Resource Event Handler 用来处理相关资源发生变化的事件:
type ResourceEventHandlerFuncs struct {
AddFunc func(obj interface{})
UpdateFunc func(oldObj, newObj interface{})
DeleteFunc func(obj interface{})
}
- AddFunc : 当资源创建时被调用
- UpdateFunc : 当已经存在的资源被修改时就会调用
UpdateFunc。oldObj表示资源的最近一次已知状态。如果 Informer 向 API Server 重新同步,则不管资源有没有发生更改,都会调用UpdateFunc。 - DeleteFunc : 当已经存在的资源被删除时就会调用
DeleteFunc。该函数会获取资源的最近一次已知状态,如果无法获取,就会得到一个类型为DeletedFinalStateUnknown的对象。
ResyncPeriod
ResyncPeriod 用来设置控制器遍历缓存中的资源以及执行 UpdateFunc 的频率。这样做可以周期性地验证资源的当前状态是否与期望状态匹配。
如果控制器错过了 update 操作或者上一次操作失败了,ResyncPeriod 将会起到很大的弥补作用。如果你想编写自定义控制器,不要把周期设置太短,否则系统负载会非常高。
SharedInformer
通过上文我们已经了解到,Informer 会将资源缓存在本地以供自己后续使用。但 Kubernetes 中运行了很多控制器,有很多资源需要管理,难免会出现以下这种重叠的情况:一个资源受到多个控制器管理。
为了应对这种场景,可以通过 SharedInformer 来创建一份供多个控制器共享的缓存。这样就不需要再重复缓存资源,也减少了系统的内存开销。使用了 SharedInformer 之后,不管有多少个控制器同时读取事件,SharedInformer 只会调用一个 Watch API 来 watch 上游的 API Server,大大降低了 API Server 的负载。实际上 kube-controller-manager 就是这么工作的。
SharedInformer 提供 hooks 来接收添加、更新或删除某个资源的事件通知。还提供了相关函数用于访问共享缓存并确定何时启用缓存,这样可以减少与 API Server 的连接次数,降低 API Server 的重复序列化成本和控制器的重复反序列化成本。
lw := cache.NewListWatchFromClient(…)
sharedInformer := cache.NewSharedInformer(lw, &api.Pod{}, resyncPeriod)
Workqueue
由于 SharedInformer 提供的缓存是共享的,所以它无法跟踪每个控制器,这就需要控制器自己实现排队和重试机制。因此,大多数 Resource Event Handler 所做的工作只是将事件放入消费者工作队列中。
每当资源被修改时,Resource Event Handler 就会放入一个 key 到 Workqueue 中。key 的表示形式为
Workqueue 在 client-go 库中的位置为 client-go/util/workqueue,支持的队列类型包括延迟队列,定时队列和速率限制队列。下面是速率限制队列的一个示例:
queue :=
workqueue.NewRateLimitingQueue(workqueue.DefaultControllerRateLimiter())
Workqueue 提供了很多函数来处理 key,每个 key 在 Workqueue 中的生命周期如下图所示:
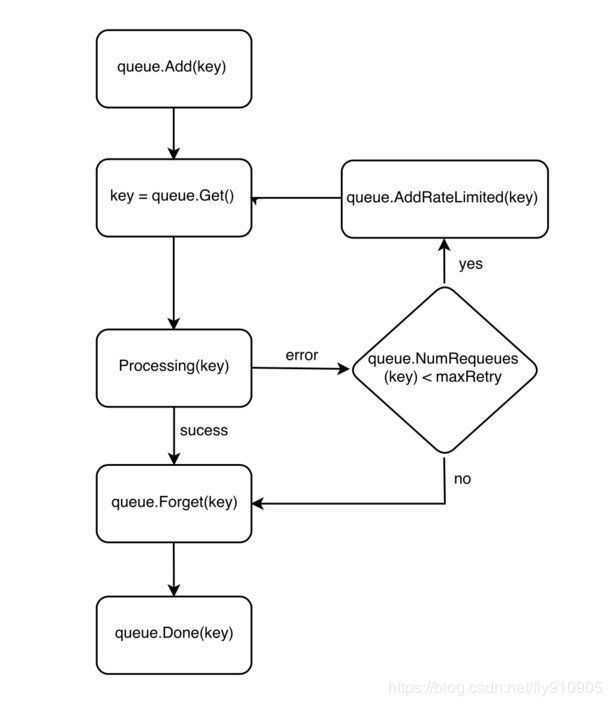 key 在 Workqueue 中的生命周期
key 在 Workqueue 中的生命周期
如果处理事件失败,控制器就会调用 AddRateLimited() 函数将事件的 key 放回 Workqueue 以供后续重试(如果重试次数没有达到上限)。如果处理成功,控制器就会调用 Forget() 函数将事件的 key 从 Workqueue 中移除。注意:该函数仅仅只是让 Workqueue 停止跟踪事件历史,如果想从 Workqueue 中完全移除事件,需要调用 Done() 函数。
现在我们知道,Workqueue 可以处理来自缓存的事件通知,但还有一个问题:控制器应该何时启用 workers 来处理 Workqueue 中的事件呢?
控制器需要等到缓存完全同步到最新状态才能开始处理 Workqueue 中的事件,主要有两个原因:
- 在缓存完全同步之前,获取的资源信息是不准确的。
- 对单个资源的多次快速更新将由缓存合并到最新版本中,因此控制器必须等到缓存变为空闲状态才能开始处理事件,不然只会把时间浪费在等待上。
这种做法的伪代码如下:
controller.informer = cache.NewSharedInformer(...)
controller.queue = workqueue.NewRateLimitingQueue(workqueue.DefaultControllerRateLimiter())
controller.informer.Run(stopCh)
if !cache.WaitForCacheSync(stopCh, controller.HasSynched)
{
log.Errorf("Timed out waiting for caches to sync"))
}
// Now start processing
controller.runWorker()
所有处理流程如下所示:
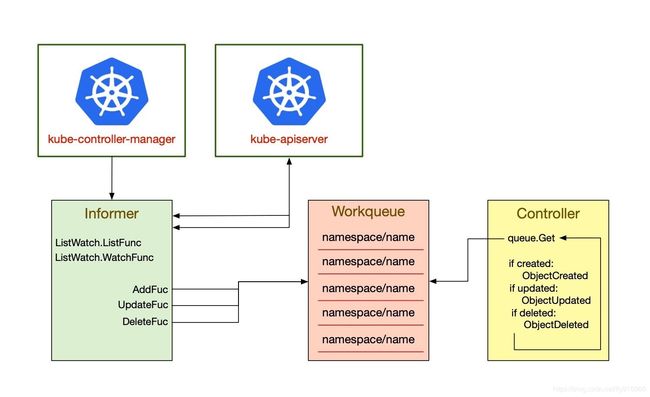 处理流程
处理流程
参考链接:
- https://juejin.im/post/5e7a15b46fb9a07c994c0895
- https://fuckcloudnative.io/posts/controllers-confession/