hive伪分布式安装(ubuntu)
hive,是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行。Hive的优点是学习成本低,可以通过类似SQL语句实现快速MapReduce统计,使MapReduce变得更加简单,而不必开发专门的MapReduce应用程序。hive是十分适合数据仓库的统计分析和Windows注册表文件。
hive不适合用于联机(online)事务处理,也不提供实时查询功能。它最适合应用在基于大量不可变数据的批处理作业。hive的特点包括:可伸缩(在Hadoop的集群上动态添加设备)、可扩展、容错、输入格式的松散耦合。hive 构建在基于静态批处理的Hadoop 之上,Hadoop 通常都有较高的延迟并且在作业提交和调度的时候需要大量的开销。因此,hive 并不能够在大规模数据集上实现低延迟快速的查询。hive 并不适合那些需要低延迟的应用,例如,联机事务处理(OLTP)。
安装准备:①jdk1.7+ ②hadoop安装
官网:http://hive.apache.org/
1、下载hive安装包并解压(tar -zxvf )
2、修改环境配置 $ vim .bashrc
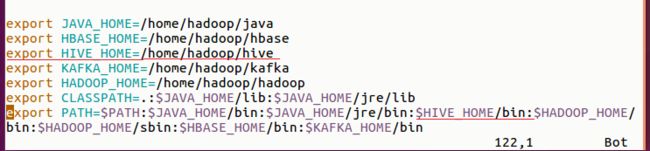
应用修改 $ source .bashrc
3.在hadoop创建hive文件路径
$ hdfs dfs -mkdir -p /user/hive/warehouse
$ hdfs dfs -mkdir -p /tmp/hive
$ hdfs dfs -chmod 777 /user/hive/warehouse
$ hdfs dfs -chmod 777 /tmp/hive
此时使用hive命令启动hive会发生错误。
使用$ schematool -initSchema -dbType derby可能会出现

解决方法:
使用命令 $ schematool -initSchema -dbType derby
此时再使用hive命令时已可正常使用hive
4. 安装mysql
5. hive伪分布配置
5.1 创建两个文件夹:/tmp/hive/operation_logs、/tmp/hive/resources
5.2 在hive/conf路径创建配置文件
$ cp hive-env.sh.template hive-env.sh
$ cp hive-default.xml.template hive-site.xml
$ cp hive-log4j2.properties.template hive-log4j2.properties
$ cp hive-exec-log4j2.properties.template hive-exec-log4j2.properties
5.2 修改配置
5.2.1 hive-env.sh
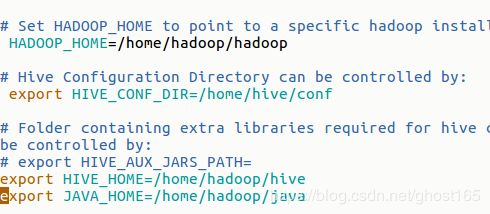
5.2.2 hive-site.xml 内容替换
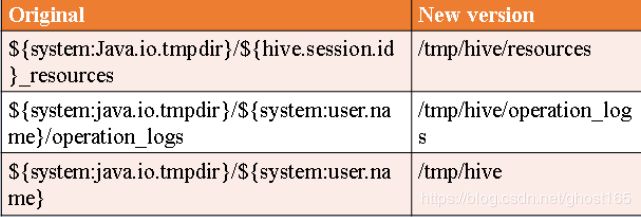
5.2.3 再次初始化hive
$ schematool -initSchema -dbType derby
$ hive
5.2.4 使用MySQL配置hive
下载并解压 MySQL-connector-Java-5.1.47.tar
将mysql-connector-java-5.1.41-bin.jar移动到hive/lib/
登录mysql并创建数据库hive_db
$ mysql -u root -p password
mysql> creat database hive_db;
5.2.5 修改hive-site.xml
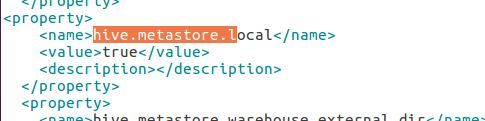
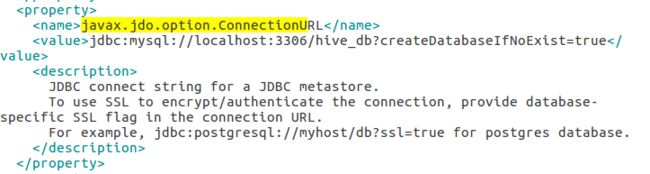



5.2.6 再次初始化hive
$ schematool -initSchema -dbType derby
$ hive
附一份hive教程 https://www.yiibai.com/hive