数据可视化经验谈-基于Tableau和Vertica的分析方法
近年来,大数据与大数据分析已成为炙手可热的话题,相关的技术与分析工具也备受大家的关注,这篇文章将着重讨论在数据可视化报表开发时,数据的处理及展示方法。本文中提到的数据的处理均基于IBM Platform Analytics数据ETL(Extract, transform, load)框架,其中列存储数据库Vertica提供的分析函数为特殊的数据处理提供了可能。数据可视化分析则用到了当前主流的数据可视化工具Tableau进行说明。
利用Vertica内置函数实现数据聚合
Vertica将数据以列的方式进行存储,大大提高了查询的性能,在以读取为主要负载的工作环境中大大降低了磁盘的I/O。除此之外,他还能对数据进行有效的压缩以减少存储空间。
此外,Vertica提供了一系列高效的SQL分析函数。与聚合函数相同SQL分析函数也返回一个聚合后的结果,但是与聚合函数的不同点在于,SQL分析函数在数据集上并不进行group by操作,分析函数结果将重复出现在数据集的每一行中用于更进一步的分析。
例如,在以下数据集License中:
lic_type num
-------------------------------------------
lic1 3
lic1 2
lic2 4要得到每类license的个数, 聚合函数的查询/结果是:
=> select lic_type, sum(num) as total from License group by lic_type
lic_type total
--------------------------------------------
lic1 5
lic2 4SQL分析函数的查询/结果是:
=> select lic_type, num, sum(num) over(partition by lic_type) as total from License
lic_type num total
---------------------------------------------
lic1 3 5
lic1 2 5
---------------------------------------------
lic2 4 4在ETL中进行的SQL分析函数的聚合可直接存储于用于可视化分析报表的数据表中,避免了报表上聚合操作,增加了数据分析的灵活性。
同时,Vertica提供的时间序列分析函数也非常值得一提。它将随着时间变化的值以一定的时间间隔分组,并对此进行分析和聚合。例如,当数据库中存有lic1在时间点10:00:00及10:00:03的使用情况,如下:
time_stamp lic_type num
-----------------------------------------------
10:00:00 lic1 2
10:00:03 lic1 5
=> select slice_time, TS_FIRST_VALUE(num, 'LINEAR') num FROM License TIMESERIES slice_time AS '1 seconds' OVER(PARTITION BY lic_type ORDER BY time_stamp);运行如上查询,10:00:00和10:00:03中每间隔1秒钟将通过线性插值的方式补上一个点,结果如下:
time_stamp lic_type num
-----------------------------------------------
10:00:00 lic1 2
10:00:01 lic1 3
10:00:02 lic1 4
10:00:03 lic1 5对于时间序列函数的合理使用可以用于在数据分析中将统计数据与采样数据进行合理的转换与合并,后文将对此函数具体使用场景进行详述。
应用Tableau实现数据可视化
Tableau作为一款商业智能与数据分析软件,具有极好的可视化效果,兼顾了良好的分析能力。Tableau 用于开发报表的简单、易用程度令人发指,使用者不需要对复杂的编程和统计原理非常精通,只需要根据需求将数据简单的拖放到工具簿中即可得到自己想要的数据可视化图形,即以最低的学习成本完成有价值的数据分析。但简单、易用的特点并没有妨碍其拥有强大的性能,基本的统计预测和趋势预测,数据源的动态更新都是Tableau的基本功能。 
数据分析及可视化分析方法
1 数据收集方式
IBM Platform Analytics是专门针对IBM Platform LSF (Load Sharing Facility) 的大数据联机解决方案。在要求高的分布式关键任务型高性能计算环境,IBM Platform LSF软件产品提供一个高性能负载管理平台,这个平台有一套综合的基于智能的,策略驱动的调度策略,方便用户使用所有运算基础设施资源,帮助保障最佳的应用性能。调度的基本单位是作业(Job),IBM Platform Analytics对于数据的分析主要集中于LSF的负载及机器硬件情况。
统计数据的收集
最常见的一类数据是统计型数据。以LSF为例,统计数据表记录着历史上完成的作业包括这些作业的基本信息,例如开始时间,结束时间,使用的硬件资源等等。这些数据可用于统计一段时间内集群的负载情况。
采样数据的收集
采样数据包括对当前负载的采样统计及对硬件的采样统计。以LSF为例,负载的采样一般记录着采样点上作业运行的情况,包括运行状态,当前使用的硬件资源等;硬件的采样一般记录着采样点上硬件的使用情况。采样的数据实时反映了被监测的负载或硬件系统情况,能精确说明系统的健康状况。
2 统计数据到采样数据的转换
有时候我们只能得到负载的统计型数据,为展示出以时间变化为序列的负载情况需要进行一定的转化。以License的统计数据为例。License Event表中的每条记录存储了某一License被check in和check out的具体时间,及License的个数。以1小时为间隔,要计算这一小时内某个License的最大及平均使用个数需要这1小时内各个时刻License使用情况的信息,当然时间粒度越小,值越精确。假设时间粒度为1分钟,这里我们需要用到Vertica提供的时间序列函数制造这1小时内每隔1分钟的假采样点,在某采样点上已经被check out还未check in的License总数即可当作此采样点的License使用总和,1小时,共60个采样点中最大的License使用值及其平均License使用值即为这1小时内License的最大使用及平均使用个数。
2016-01-01 10:00:00到11:00:00假采样点的生成:
SELECT TIME_STAMP, LIC_VENDOR_NAME, LIC_FEATURE_NAME, SUM(R.LIC_USAGE) AS LIC_USAGE
FROM (SELECT TIME_STAMP
FROM (SELECT timestamp'2016-1-1 10:00:00'
FROM dual
UNION
SELECT timestamp'2016-1-1 11:00:00' AS SAMPLING_TIME
FROM dual) T TIMESERIES TIME_STAMP AS '1 minute' OVER(ORDER BY SAMPLING_TIME)) T,
(SELECT CHECKOUT, CHECKIN, LIC_VENDOR_NAME,LIC _FEATURE_NAME, LIC_USAGE
FROM LICENSE_EVENT ) R
WHERE T.TIME_STAMP_UTC >= R.CHECKOUT AND T.TIME_STAMP_UTC <= R.CHECKIN
GROUP BY 1, 2, 33 往更高时间粒度上的聚合
实际数据采集分析中,为保证精确度,数据采集的时间粒度可能很小,但是在报表展示中,细粒度的数据对宏观的分析没有帮助的同时大量的数据查询还降低了报表展示的性能,所以采样数据有时需要向更高的粒度进行聚合。在聚合中对于任意度量需要保存的聚合值必须包含其最大值,最小值,总和及细粒度的间隔,这些信息可帮助我们在更高粒度的数据表中还原出此度量的最大值,最小值及平均值,没有信息的丢失。
4 数据的展示方式
时间过滤器
报表中时间过滤器可以帮助用户只关注于感兴趣的时间区间,基于大量的用户需求和实例,最有效便捷的时间过滤方式可以是提供用户三个选项参数和一个时间过滤表。用户通过选项参数锁定较大范围的时间区间,点击时间过滤表得到更精确的时间区域。三个选项包括:显示天数,使用给定时间作为起点或以今天作为时间终点,给定的时间起点。除此之外,对于某些和工作时间有关的负载需要以用户自定义工作时间进行过滤计算。例如IBM Platform Analytics提供如图2的时间过滤器。
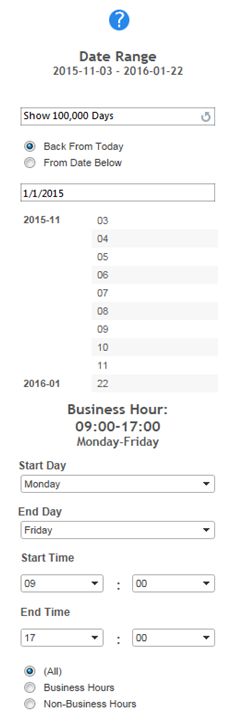
柱状图与线(区域)图使用场景
当时间作为坐标轴时柱状图与线(区域图)的最大区别是,柱状图应该用于显示离散的数据,而线(区域)图应该用于显示连续产生的数据例如采样数据,若在离散数据的展示中使用线(区域)图,结果是没有值的时间点将被前后点线性连接起来,并不能很好的反映真实情况,如图3:

图3展示了1月9日到22日作业完成的分布情况,柱状图显示的负载情况清晰明了。
用于排序的柱状图
要对负载情况进行全面分析的另一方法则是以负载的数量为度量值进行排序,例如运行在某一时间段内作业的长短情况。进行排序前首先需要对作业运行时间进行归类,1分钟内和2分钟内的作业对用户来说都是短作业,归类即使报表展示简单明了对用户来说整体情况也一目了然。

报表的交互及分析流
交互式报表给数据的挖掘提供了无限可能,例如用户可以通过点击时间列表中任意一天仅查看一天内的负载硬件情况,通过点击任意作业运行时间分类查看此分类下所有作业的信息,或是点击任意集群查看此集群下硬件的详细信息。一个简单的例子: 
上面的例子中,用户先点击他所关注的作业,在这里是运行时间在1分钟到3分钟里的所有作业,作业挂起时间表在用户点击后进行了过滤,正如图5所展示的,1分钟到3分钟里的作业挂起时间都在5秒之内,点击0s到5s的柱子,具体作业运行情况的数据表将只显示用户关心的作业情况即运行在1分钟到3分钟内,挂起在5秒内的作业。
5. 典型的用户用例
内存的申请与使用对比

在”Requested Vs Used Memory Ranks”表中,用户首先锁定内存请求在”4GB to 8GB”这一分类,从数据表中可以看到,大量的申请了4GB到8GB的作业只使用了小与1GB的内存,点击”4GB to 8GB” 在”Requested Vs Used Chart”表中显示了申请4GB到8GB的作业在真正使用内存类别上的分布。用户可以进一步钻取数据,查看使用小与1GB的内存在Project上的分布,如图7: 
用户可以只选择排列靠前的Project在”Requested Vs Used Memory – Workload Data”表中查看每个项目中运行的作业的详细情况,找出LSF系统的瓶颈。
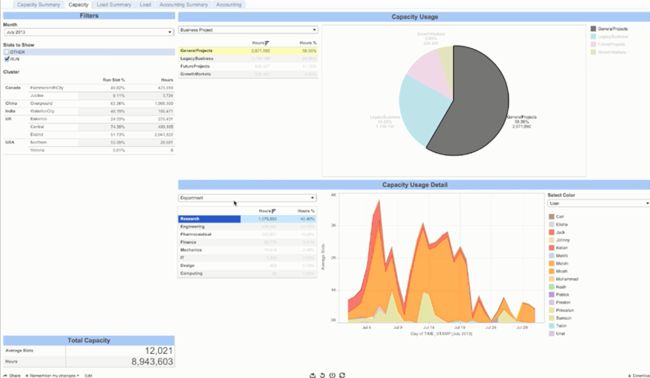
系统负载情况
图8是一个典型的展示系统负载情况的报表。”Capacity Usage”图表清晰地指出在GeneralProject上以小时为单位负载量最大,占总体的50%以上。当用户点击GeneralProject,”Capacity Usage Detail”表中展示了在GeneralProject上负载在不同维度上的分布情况:Research部门与其他部门相比负载量遥遥领先,而在Research部门中,又属用户Michael,及区域图中橙色部分代表的区域,运行了最多的负载。交互钻取式的信息展示方法可以帮助用户对LSF上运行的负载进行快速深入的了解。
结束语
以上提到的数据分析可视化方法,都是我们在开发IBM Platform Analytics时通过丰富的用户用例及使用反馈总结的宝贵经验,PA下一步将在数据分析和预测上持续前进。
作者简介:雒琛,2014年加入IBM至今,从事软件开发工作,研究方向为大数据分析及数据可视化。
责编:周建丁([email protected])