微调预训练模型的新姿势——自集成和自蒸馏
文章目录
- 1、什么是自蒸馏?
- 2、为什么要自蒸馏?
- 3、如何进行自蒸馏?
- 4、通过自蒸馏我们可以得到什么?
转载来源:https://zhuanlan.zhihu.com/p/133804801
论文:Improving BERT Fine-Tuning via Self-Ensemble and Self-Distillation
链接:https://arxiv.org/abs/2002.10345
作者:Yige Xu, Xipeng Qiu, Ligao Zhou, Xuanjing Huang
本文提出了一种自集成和自蒸馏的fine-tuning方法,在不引入外部资源和不显著增加训练时间的前提下,可以进一步增强fine-tuning的效果。

自蒸馏的前世今生——what、why、how?
1、什么是自蒸馏?
知识蒸馏(Knowledge Distillation)指的是将预训练好的教师模型(Teacher Model)的知识通过蒸馏的方式迁移到学生模型(Student Model)。自蒸馏(Self-Distillation)则指的是自己蒸馏到自己,Teacher Model就是Student Model的集成版本,称为自集成(Self-Ensemble)。集成模型在是刷榜利器,因此我们希望在训练过程中不同time step的模型也可以集成。为了不增加训练开销,我们选择一种参数平均的方式来进行自集成。
与同期的工作FastBERT的自蒸馏(高层蒸馏到底层)不同,本文的自蒸馏指的是过去time step蒸馏到当前time step。在Fine-tune过程中,目标函数除了有来自标签的监督信号以外,还有来自过去time step的监督信号。本文的自蒸馏是为了进一步提高准确率而不是模型压缩。
2、为什么要自蒸馏?
I. 在一般的Fine-tune流程当中,我们通常只关注某一个epoch结束之后的模型参数,而不关心在Fine-tune过程中某个time step的参数。那么Fine-tune的中间过程是否有什么值得我们挖掘的信息呢?
II. 在一般的训练过程当中,我们通常将数据集划分成一个个mini-batch,依次通过模型进行训练。如果某一个mini-batch的数据质量不过关,可能会将模型参数带歪,因此是否可以寻找一种方式来减缓“带歪”的趋势呢?
III.好的teacher可以教出更好的学生,而好的学生可以进一步集成为更好的教师,通过迭代可以进行自我增强。
3、如何进行自蒸馏?
在本文中,我们提出了两种自蒸馏的方式:Self-Distillation-Averaged(SDA)和Self-Distillation-Voted(SDV)。在SDA中,我们首先计算出过去K个time step参数的平均值作为Teacher Model。在SDV中,我们将过去K个time step的参数视为K个Teacher Model。
SDA的目标函数计算方式如下:
£ θ ( x , y ) = C E ( B E R T ( x , θ ) , y ) + λ M S E ( B E R T ( x , θ ) , B E R T ( x , θ ˉ ) ) \pounds _{\theta }(x,y)=CE(BERT(x,\theta ),y)+\lambda MSE(BERT(x,\theta ),BERT(x,\bar{\theta})) £θ(x,y)=CE(BERT(x,θ),y)+λMSE(BERT(x,θ),BERT(x,θˉ))
其中 θ ˉ = 1 K ∑ k = 1 K θ t − k \bar{\theta} = \frac{1}{K}\sum_{k=1}^{K}\theta_{t-k} θˉ=K1∑k=1Kθt−k
SDV的目标函数计算方式如下:
£ θ ( x , y ) = C E ( B E R T ( x , θ ) , y ) + λ M S E ( B E R T ( x , θ ) , 1 K ∑ k = 1 K B E R T ( x , θ t − k ) ) \pounds _{\theta }(x,y)=CE(BERT(x,\theta ),y)+\lambda MSE(BERT(x,\theta ),\frac{1}{K}\sum_{k=1}^{K}BERT(x,\theta_{t-k})) £θ(x,y)=CE(BERT(x,θ),y)+λMSE(BERT(x,θ),K1k=1∑KBERT(x,θt−k))
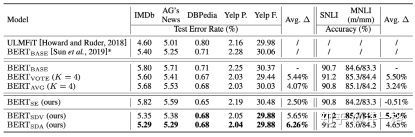
4、通过自蒸馏我们可以得到什么?
更稳定的训练过程
我们在SNLI数据集当中随机抽取了1500条训练数据组成一个迷你训练集。不改变模型参数初始化,只改变数据训练顺序。通过在这个迷你训练集上的实验,我们发现SDA和SDV加持下的训练更为稳定,准确率的均值更高、方差更低。

更高的准确率
在SDA和SDV加持下,可以有效提升在下游任务Fine-tune BERT的性能。