ECCV的全称是European Conference on Computer Vision(欧洲计算机视觉国际会议) ,两年一次,是计算机视觉三大会议(另外两个是ICCV和CVPR)之一。
YouTube8M是一个大规模视频标签数据集,里面包含了大概8百万视频和3800左右的类别标签。为了推进视频领域的研究,Google AI每年会在这个数据集上举办比赛。
阿里安全图灵实验室今年参加了ECCV2018的2个workshop和YouTube8M比赛,我们提出的“Hierarchical Video Frame Sequence Representation with Deep Convolutional Graph Network” 文章被“2nd Workshop on Youtube-8M Large-Scale Video Understanding”接收,并在“First Workshop on Computer Vision For Fashion, Art and Design”的比赛中获得冠军,已受邀在研讨会上进行poster和oral。
通过本文进行分享,希望能有所帮助。
ECCV2018 workshop
今年ECCV的workshop/tutorial有60多个,有些办了几届,有些今年是第一届,所涵盖的主题不论给学术界,也给工业界带来了很大启发。下面介绍我们参加的其中一个workshop----“2nd Workshop on Youtube-8M Large-Scale Video Understanding”
下图为大名鼎鼎的VGG发明人Andrew Zisserman和google视频分析团队负责人Paul Natsev

下图为我们的poster现场

比赛介绍
比赛在YouTube8M数据集上进行,为了使数据集体积减小,官方使用一些网络对图片和音频提取特征并pca降维后存储,整个数据集大小为1.5T左右。数据集统计数据如下图所示:
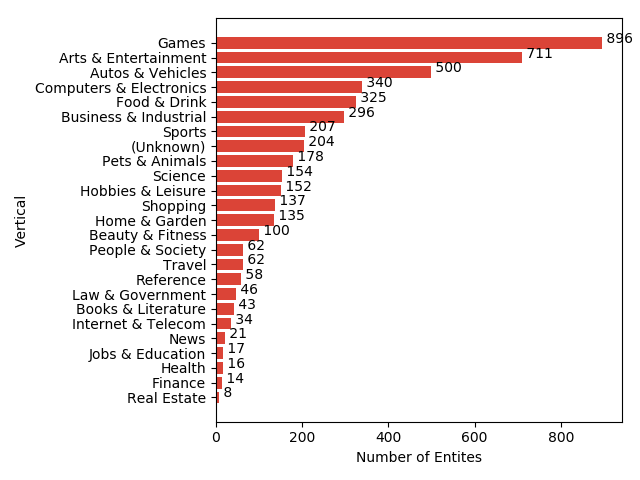
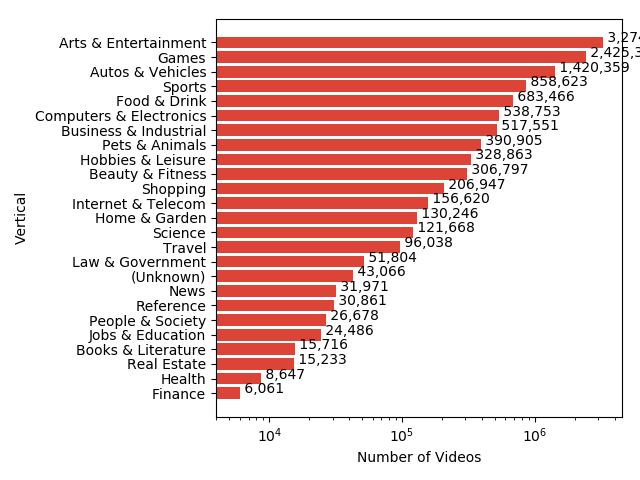

经过pca降维后图片为1024维,音频为128维,视频时长大概分布在120到500秒之间,平均每个视频3个标签左右。
比赛要求在这样的数据集上训练一个不超过1GB大小的模型,并且不允许在test数据集上做任何处理。
比赛准备
我们首先分析了去年获胜队伍的做法。今年的数据集有所变化,对标签做了一些调整,所以去年的一些获胜队伍的做法仍然有参考价值。
去年第一名采用了改进的netVlad[1]作为参赛模型,使用netVLAD和Gate Context来代替传统RNN模型做temporal aggregation。该模型在测试集上效果比较好,但是模型体积太大,大概4GB左右。去年第二名采用了77个模型进行ensemble,模型体积也比较大。下图为VLAD(左)和netVLAD(右)

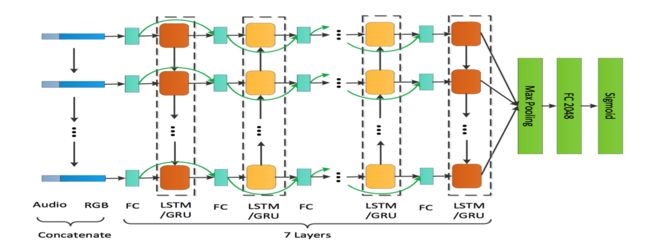
去年第三名采用了改进的7层的Bi-direction LSTM,加入了Fast-forward为了能让7层LSTM可以训练,如下图所示:
我们的工作
我们从以下几个方面进行序列建模,来完成视频标签的任务,分别是:RNN系列、CNN替代RNN系列、Graph建模、VLAD建模。
RNN系列
时间序列建模最先想到的就是RNN模型,通过RNN的计算能够做到temporal aggregation,之后进行多标签分类。
RNN Base Line
直接使用LSTM对视频进行temporal aggregation,然后使用Logistic进行多标签分类,我们得到GAP:76.5%
RNN+Attention
原始的LSTM效果比较弱,我们考虑使用Attention对模型进行改进,LSTM+Attention得到GAP:83.9%,相比较单纯使用LSTM提升了6个点左右,随后我们对Attention进行了分析,得到的中间结果显示,Attention在temporal aggregation的过程中起了很重要的作用,让模型更关注一些重要的能表达内容的视频帧画面。Attention的具体实现如下图所示:

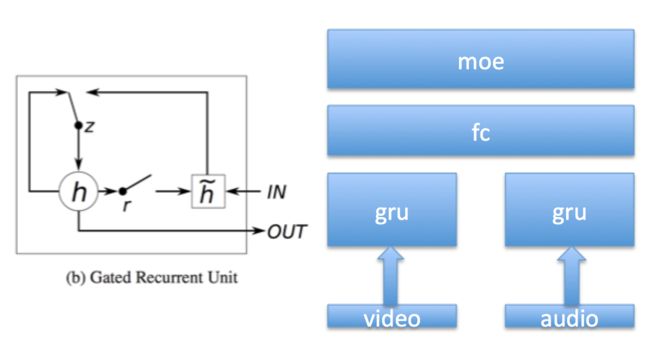
GRU+Attention+Two Stream
考虑到有些视频可能声音比较重要,比如静态画面的MTV,对于这种视频如果只看画面,网络可能很难分辨视频属于哪个类别。所以我们考虑将画面特征与音频特征分别建模,最后做融合,下文把这种分别建模再融合的办法称为Two Stream Model。跟传统的视频Two stream(运动+内容)概念不同,这样做是因为数据集里面只有预先提取的特征,并且经过了PCA降维,所以我们无法很好的获得运动信息。
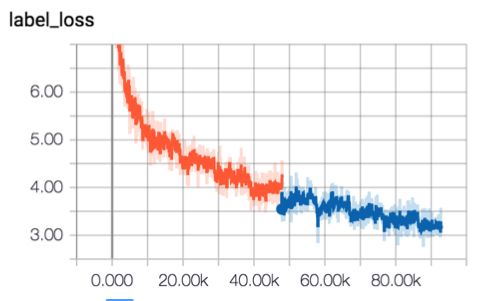
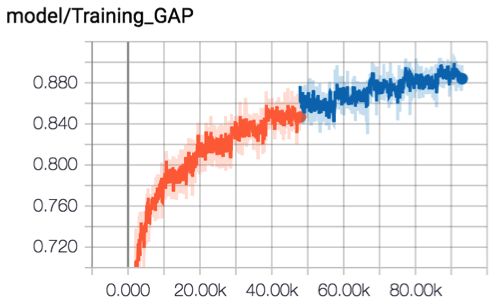
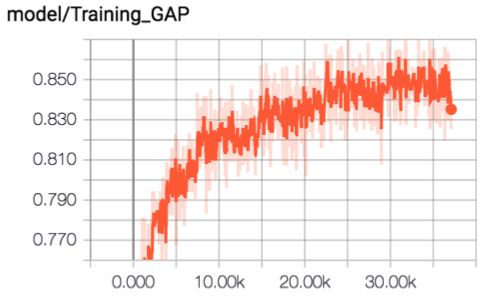
经过分别对视频和音频建模再融合,Two Stream Model取得了比之前更好的效果,GRU+Attention+Two Stream的模型得到GAP:84.6%。模型结构和训练曲线如下图所示:

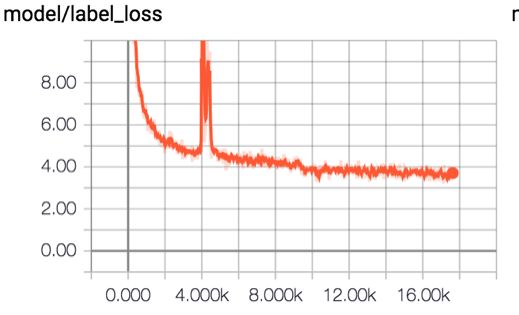
SRU+Attention+Two Stream
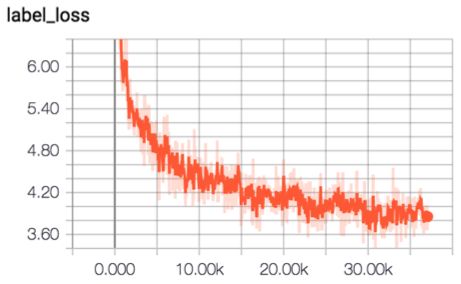
GRU减少了LSTM的门数量,同时又保证了模型效果,虽然GRU减少了两个门,但是依然训练缓慢。SRU通过使用hadamard product来代替矩阵乘法,并通过将大量计算放在可以并行的步骤,加速了训练和推理过程。我们尝试使用SRU替换GRU,得到GAP:85.4%。SRU结构和训练曲线如下图所示:
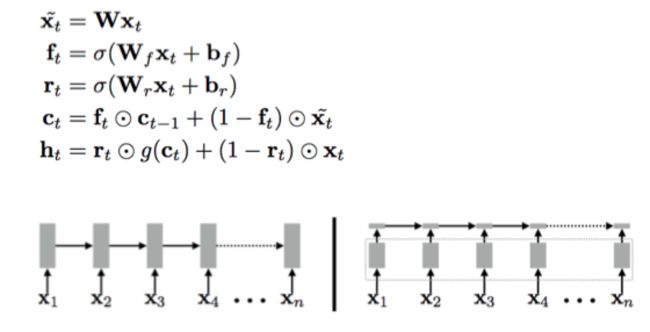
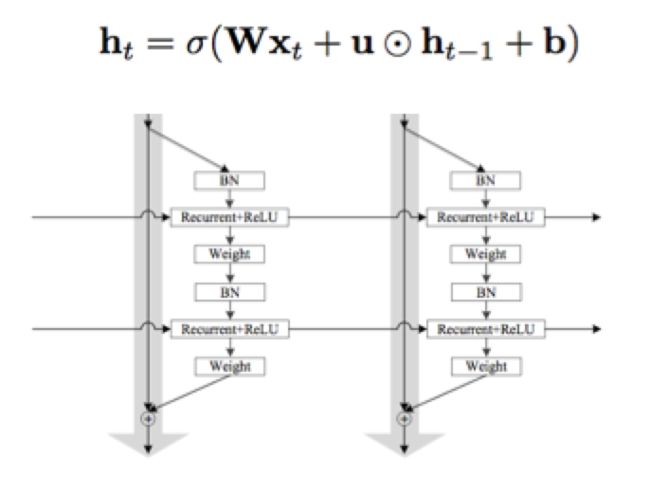
IndRNN+Attention+Two Stream
IndRNN对LSTM的优化更极端,去掉了全部的门,并且使用hadamard product。我们使用IndRNN改进模型后得到GAP:83.4% 模型结构和训练曲线如下:
CNN替代RNN系列
RNN和其改进的模型通常被用在序列建模,大量的序列建模任务也证实了RNN系列模型有很好的拟合能力。RNN系列通过BPTT来进行反向传播训练模型,对于时间的依赖导致RNN系列模型相比CNN不能并行计算,从而影响了训练速度和推理速度。RNN系列里LSTM、GRU、SRU虽然通过门的改进解决了gradient vanish,但是sigmoid函数的使用使得RNN系列层数一旦加深,依然会产生gradient decay,最终难以训练。
CNN在最近的一些序列建模任务中也表现出不错的结果,CNN天生可以并行化计算,通过对层数的堆叠依然可以达到扩大时间尺度上视野的效果,并且CNN可以加深很多层依然容易训练。
所以我们尝试使用CNN代替RNN进行建模。
CNN+Attention+Residual+Two Stream
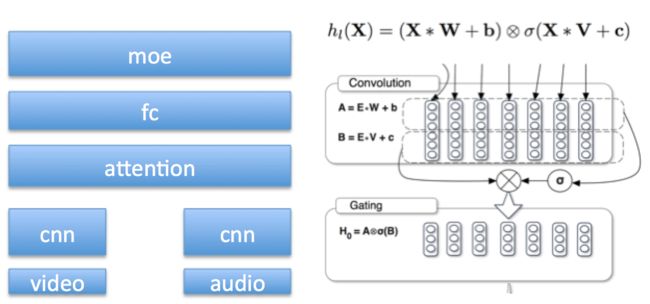
我们尝试使用简单的CNN来替代RNN对时间维度进行卷积,为了加速训练我们使用了Residual结构。同时我们使用GLU激活函数带替代ReLU,GLU使用gate思想添加了gate unit,GLU对比ReLU会产生更高的精度。该模型最后得到GAP:85.9%,模型大小138MB,这是本次比赛过程中我们得到的性价比(性能/体积)最高的模型。
网络结构和GLU结构如下:
训练曲线如下:
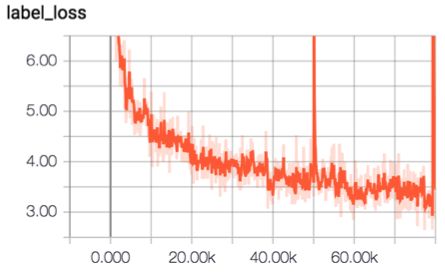
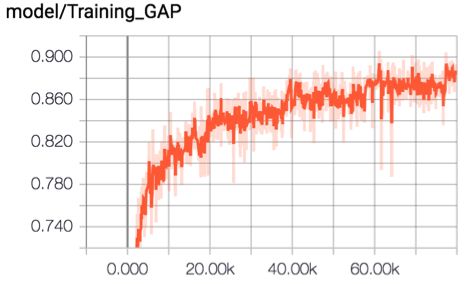
TCN+Attention+Residual+Two Stream
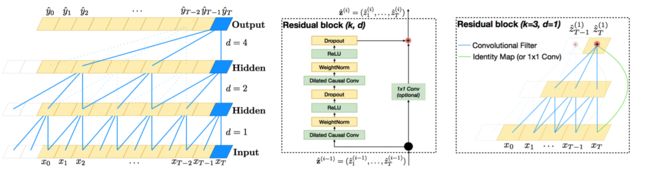
TCN是一个最近在NLP上取得不错结果的模型,我们使用TCN改进基础的CNN,并且使用了空洞卷积来扩大时间尺度上的视野。最后得到GAP:85.5%网络结构如下图:
Graph建模(accepted as post by ECCV2018)
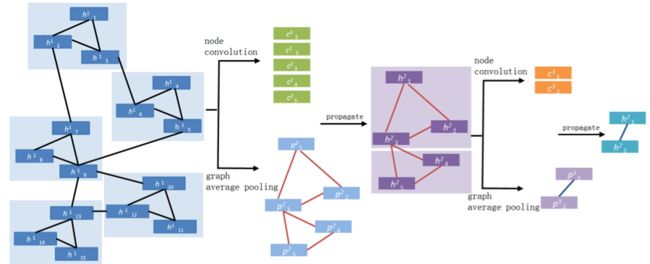
我们认为视频是一种含有多级结构的数据(hierarchical data structure),即一个视频包含帧、镜头、场景、事件等。而且帧与帧、镜头与镜头间的关系十分复杂,不仅仅是前后帧的顺序关系,通过一般的序列建模方法,如LSTM,无法表达如此复杂的关系,建模效果较差。举个例子,如图1所示,包含同一个目标物的帧或镜头并不都是连续的,它们分布在不同的时间点上。本文通过深度卷积图神经网络(DCGN)对视频的帧、镜头、事件进行多级的建模,逐渐地从帧级、镜头级,一直到视频级进行抽象,从而获得视频全局的表达,进而进行分类,如图2所示。

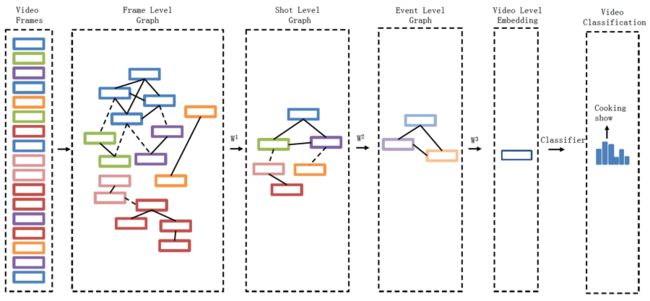
节点被边链接在一起。通过该图,最终获得视频级的表达(video level embedding),进而进行分类(video classification)。
DCGN的核心模块包括1)节点卷积(node convolution);2)图池化(graph pooling);3)特征传播(propagate)。 并且通过堆叠模块形成了一个深度的图神经网络。图3展示了网络中的一个3层的子结构。
此项工作可以作为序列建模的通用方法,在其它如语音识别、文本分类等场景都有潜在应用价值。
我们使用基础的deep convolutional graph neural network(DCGN)结构来建模,得到GAP:84.5%
VLAD建模
原始的netVLAD体积有4GB左右,无法直接拿来用在本届比赛中,所以我们考虑减小netVLAD的体积,通过对网络的剪枝,我们得到400MB左右的模型。最终GAP:86%
Ensemble
通过Ensemble,我们最终模型大小980MB得到的GAP:88.3%
安全AI相关workshop
此外,我们还关注了一些和安全AI相关的workshop和tutorial,主要包括
- “Workshop on Objectionable Content and Misinformation”
- Adversarial ML
Workshop on Objectionable Content and Misinformation
随着互联网的出现,特别是搜索引擎和社交网络的出现,每天都会创建和共享大量的图像和视频,从而导致数十亿的信息呈现给大众。然而依然存在如下两大问题:
不良内容:令人反感的内容或敏感图像,如裸露,色情,暴力,血腥,儿童欺凌和恐怖主义等。
误导信息:如假镜头、PS等可能损坏图像和视频信息的准确性,破坏了信息(新闻,博客,帖子等)的不偏不倚和信任。
本次研讨会的组织者来自Google,Facebook和一些相关领域的企业和学术机构,目的是探索由令人反感的内容和错误信息引起的计算机视觉领域的具体挑战,并围绕这一研究领域建立一个联合讨论论坛。研讨会的研究主题包括
- 图像和视频取证
- 检测/分析/理解作假图像和视频
- 错误信息检测/理解:单模态和多模态
- 对抗技术
- 不良内容的检测/理解:包括:色情、暴力、仇恨言论、恐怖主义、濒危儿童等。
本次研讨会的大部分时间是对misinformation进行了讨论,即Image Splicing and localization

Adversarial ML
机器学习和数据驱动的AI技术,包括深度网络,目前用于多种应用,从计算机视觉到网络安全。 在大多数这些应用程序中,包括垃圾邮件和恶意软件检测,学习算法必须面对智能的和自适应的攻击者,他们可以精细地操纵数据,从而故意破坏学习过程。 由于这些算法最初并未在这样的场景下设计,因此它们被证明易受精心设计的复杂攻击,包括测试期间的规避(evasion)和训练期间的中毒(poisoning)攻击(也称为对抗性样本)。 因此,在对抗环境中应对这些威胁并学习安全分类器和AI系统的问题已经成为机器学习和人工智能安全领域中一个新兴的相关研究领域的主题,称为对抗性机器学习。
如何设计一个Adversary-aware 的机器学习系统呢?这个tutorial提出了3个黄金法则
- Know your adversary。如果你了解敌人并了解自己,你就不必担心战斗结果
- Be proactive。要了解你的敌人,你必须成为你的敌人
- Protect your classifier。



本文作者:为易.wx
阅读原文
本文为云栖社区原创内容,未经允许不得转载。