HashMap源码阅读04
HashMap源码阅读04
- 前言
- 正文
- 1、设计测试案例
- (1)设计目的
- (2)测试hash方法
- (3)建立测试案例
- 2、调试分析
- (1)debug调试
- (2)记录数据
- (3)分析规律
- 3、验证总结
前言
上一篇文章我们呈现了HashMap在扩容时对链表节点的处理过程,这篇文章我们就对其中规律一探究竟。
正文
1、设计测试案例
(1)设计目的
通过测试一个较长的链表结果在HashMap扩容时会如何分布,分析debug过程和结果,试图从中总结规律。
(2)测试hash方法
我们通过HashMap中的hash算法找到了一些在调用put方法时会hash碰撞的key值:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
@Test
public void testHash(){
int n = 16;
String s = "l";
int hash = hash(s);
System.out.println(hash);
int res = (n - 1) & hash;
System.out.println(res);
s = "hd";
hash = hash(s);
System.out.println(hash);
res = (n - 1) & hash;
System.out.println(res);
s = "hdi";
hash = hash(s);
System.out.println(hash);
res = (n - 1) & hash;
System.out.println(res);
s = "hdaq";
hash = hash(s);
System.out.println(hash);
res = (n - 1) & hash;
System.out.println(res);
s = "hderm";
hash = hash(s);
System.out.println(hash);
res = (n - 1) & hash;
System.out.println(res);
}
执行测试方法验证,控制台输入如图,都落在同一个位置上,结果如图:

(3)建立测试案例
将以上测试结果,建立成测试案例:
@Test
public void test(){
Map map = new HashMap<>();
map.put("a",1);
map.put("b",2);
map.put("c",3);
map.put("d",4);
// map.put("Ed",4);
map.put("E",4);
map.put("F",4);
map.put("G",4);
map.put("hd",4);
map.put("hdi",4);
map.put("hdaq",4);
map.put("hderm",4);
// map.put("h",4);
map.put("I",4);
map.put("J",4);
map.put("K",4);
map.put("l",4);
map.put("M",4);
Integer i = (Integer) map.get("a");
System.out.println(i);
}
2、调试分析
(1)debug调试
我们通过debug调试得到了一条以(“hd”,4)为头部,接着是(“hdi”,4)、(“hdaq”,4),以(“hderm”,4)为末端的链表。
当到达阈值时,HashMap需要进行扩容,此时我们关注的是HashMap如何处理这条链表。我们定位到resize方法相关代码:
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode)e).split(this, newTab, j, oldCap);
else { // preserve order
Node loHead = null, loTail = null;
Node hiHead = null, hiTail = null;
Node next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
(2)记录数据
经过debug调试,我们得到了一些遍历链表的数据,列出表格如下:
| 次数\变量 | e | hiHead | hiTail | next | loHead | loTail | (e.hash & oldCap) == 0 | 说明 |
|---|---|---|---|---|---|---|---|---|
| 第一次 | hd,4 | hd,4 | hd,4 | hdi.4 | null | null | 不满足 | |
| 第二次 | hdi,4 | hd,4 | hd,4 | hdaq.4 | hdi,4 | hdi,4 | 满足 | |
| 第三次 | hdaq,4 | hd,4 | hdaq,4 | hderm.4 | hdi,4 | hdi,4 | 不满足 | hd,4的next为hdaq,4 |
| 第四次 | hderm,4 | hd,4 | hdaq,4 | null | hdi,4 | hderm,4 | 满足 | hdi,4的next为hderm,4 |
(3)分析规律
由此我们得知,经过一系列运算,HashMap把这一条链表进行重新组合,满足(e.hash & oldCap) == 0的为一条链,放入当前索引位置,不满足(e.hash & oldCap) == 0的为另一条链,放入扩容后的索引(当前索引+旧容量)位置。
以我们文中的这条链为例,最终被重新组合成了以(“hdi”,4)为头部,以(“hderm”,4)为末端的链表,还有以(“hd”,4)为头部,以(“hdaq”,4)为末端的另一条链表。如截图所示。
附上结果截图:
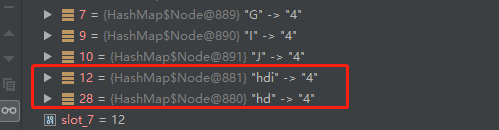
3、验证总结
对于上述分析,我们需要进行进一步的验证,我们对测试案例进行改进,增加链表长度,如下:
@Test
public void test(){
Map map = new HashMap<>();
map.put("a",1);
map.put("b",2);
map.put("c",3);
// map.put("d",4);
// map.put("Ed",4);
// map.put("E",4);
// map.put("F",4);
// map.put("G",4);
map.put("hd",4);
map.put("hdi",4);
map.put("hdaq",4);
map.put("hderm",4);
map.put("hdermh",4);
map.put("hdermeN",4);
map.put("hdermera",4);
map.put("hdermeqco",4);
map.put("l",4);
// map.put("h",4);
map.put("I",4);
map.put("J",4);
map.put("K",4);
map.put("M",4);
Integer i = (Integer) map.get("a");
System.out.println(i);
}
在这里我们发现,当链表长度超过8时,HashMap会调用treeifyBin方法,我们这里不做研究。
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
为了避免treeifyBin方法带来的影响,我们调整下测试案例,将链表长度控制在8以内:
@Test
public void test(){
Map map = new HashMap<>();
map.put("a",1);
map.put("b",2);
map.put("c",3);
// map.put("d",4);
// map.put("Ed",4);
// map.put("E",4);
// map.put("F",4);
// map.put("G",4);
map.put("hd",4);
map.put("hdi",4);
map.put("hdaq",4);
map.put("hderm",4);
map.put("hdermh",4);
map.put("hdermeN",4);
map.put("hdermera",4);
// map.put("hdermeqco",4);
map.put("l",4);
// map.put("h",4);
map.put("I",4);
map.put("J",4);
map.put("K",4);
map.put("M",4);
Integer i = (Integer) map.get("a");
System.out.println(i);
}
进行调试时记录数据并整理成表格如下:
| 次数\变量 | e | hiHead | hiTail | next | loHead | loTail | (e.hash & oldCap) == 0 | 说明 |
|---|---|---|---|---|---|---|---|---|
| 第一次 | hd,4 | hd,4 | hd,4 | hdi.4 | null | null | 不满足 | |
| 第二次 | hdi,4 | hd,4 | hd,4 | hdaq.4 | hdi,4 | hdi,4 | 满足 | |
| 第三次 | hdaq,4 | hd,4 | hdaq,4 | hderm.4 | hdi,4 | hdi,4 | 不满足 | hd,4的next为hdaq,4 |
| 第四次 | hderm,4 | hd,4 | hdaq,4 | hdermh.4 | hdi,4 | hderm,4 | 满足 | hdi,4的next为hderm,4 |
| 第五次 | hdermh,4 | hd,4 | hdaq,4 | hdermeN,4 | hdi,4 | hdermh,4 | 满足 | hderm,4的next为hdermh,4 |
| 第六次 | hdermeN,4 | hd,4 | hdermeN,4 | hdermera,4 | hdi,4 | hdermh,4 | 不满足 | hdaq,4的next为hdermeN,4 |
| 第七次 | hdermera,4 | hd,4 | hdermeN,4 | l,4 | hdi,4 | hdermera,4 | 满足 | hdermh,4的next为hdermera,4 |
| 第八次 | l,4 | hd,4 | hdermeN,4 | null | hdi,4 | l,4 | 满足 | hdermera,4的next为l,4 |
上述表格说明,在HashMap扩容时,原本长度为8的链表进行了重新组合,根据是否满足(e.hash & oldCap) == 0判断作为条件,满足条件的形成一条链表,放在当前索引位置上,不满足条件的形成另一条链,放在扩容后的新位置上(当前索引位置+原节点数组容量)。得到的链表截图如下:

以上验证过程结束,我们总结的规律也成功得到验证。