常见的时间序列数据库概述
对于时间序列的存储,一般会采用专门的时间序列数据库,而不会去使用mysql或是mongo(但zabbix就是用的mysql,所以它在IO上面遇到了瓶颈)。现在时间序列的数据库是有很多的,比如graphite、opentsdb以及新生的influxdb。最近也相继研究了一下这三个数据库,现在把研究所得记录下来。
graphite
graphite算是一个老牌的时间序列存储解决方案了,graphite由三个部分组成,分别是carbon、whisper和graphite web,盗图:

carbon:实际上是一系列守护进程,这些守护进程用Twisted的事件驱动网络引擎监听时间序列数据。Twisted框架让Carbon守护进程能够以很低的开销处理大量的客户端和流量。
whisper:是一个用于存储时间序列数据的数据库,之后应用程序可以用create,update和fetch操作获取并操作这些数据。
graphite web:使用django开发的一套web,提供一些常用的聚合函数,可以界面友好的展示出图形。再盗图:

whisper支持RRD,可以很方便的定义retention,以及定义storage scheme,不需要手动做,graphite会自动帮你按照不同的scheme实现aggregation。这样每个metric的大小就是固定的了,所以理论上可以永久存储数据。graphite的集群方案主要有两种,分别是使用graphite自带的relay或是使用第三方的工具。
当使用自带的relay时,只需要在配置文件中配置要relay到哪些机器即可,这样在数据写入的时候,被写入的节点会relay一份到这些机器中。在读取的时候,在graphite web的settings中配置HOSTS的列表,这样在django的web中会依次从这些HOSTS中读出数据。
另一种是需用第三方的relay工具,Booking公司开源出来了他们所用的用C写得 carbon-c-relay,以及用GO写得carbon-relay-ng。其基本的思想是运用一致性哈希,可以将不同的metric发到不同的机器,以来达到集群的目的,据Booking称他们的graphite集群的规模达到了百台机器,而mertic也达到了百万的级别.
以上的两种方式都会遇到了一个共同的问题,就是集群扩容的问题,我不知道Booking是怎么来解决这个问题的,但是我这边目前是想到了几种方式,这个在我前一篇的文章中已经阐述了:graphite集群扩容方案探究,在这里就先不赘述了。
最后说一下,除了集群问题以外,graphite的还有一性能问题就是读的性能稍差,这决定于其存储的方式,其实在读的时候会去读whisper文件(虽然在django层做了缓存,但是缓存的功能比较弱),通过seek的方式来获取数据的位置,在将数据取出。
opentsdb
opentsdb是一个比较重的时间序列解决方案,为什么说他重呢?因为它的组成是这样的:
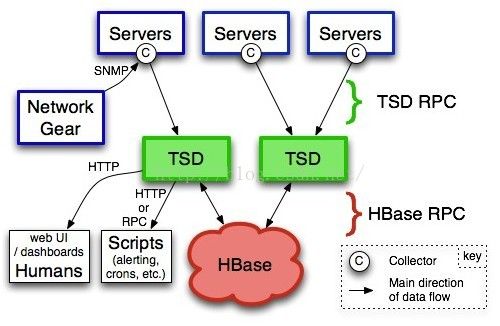
可以看到opentsdb所依赖的存储是Hbase集群。TSD在其中担任的责任是IO部分,TSD其实就是一个后台的daemon,一般我会会用一组TSD达成一个TSD的集群(其实不能算是集群),没有master/slave之分,也没有共享状态,然后在之前用LB设备来做负载均衡,官方比较推荐的是用varnish。
当让后端的存储也可以用其他的例如hadoop,但是官方还是建议用Hbase,因为opentsdb就是Hbase社区孵化出来的产品。那么问题来了,Hbase的运维将是一个艰巨的任务,这个依赖于zookeeper搭建的集群的坑还是很多的,我看了一下官方文档就有上千页。这里面的优化维护需要有专业的Hbase专家才能完成。
另外opentsdb做不到graphite那样自动做downsample,也就是做不到RRD那样地去存储数据,需要在外面自己做一层手动干这活,再把聚合后的数据写入Hbase,唉,还真是一个费时费力的活。
除此之外opentsdb还是很不错的,读写性能挺高,而且支持tag,支持ttl,支持各种聚合函数。现在很多的监控的metric的存储都是用的opentsdb,嗯,是的,只要有能力玩转还是个不错的选择。
influxdb
influxdb是最新的一个时间序列数据库,最新一两年才产生,但已经拥有极高的人气。influxdb 是用Go写的,现在v0.9正在开发中,之前开源出来的最稳定的版本是0.88的,但是0.8X是没有集群方案的,但在0.9中会加入进来。
0.9版本的influxdb对于之前会有很大的改变,后端存储有LevelDB换成了BoltDB,读写的API也是有了很大的变化,也将支持集群化,continuous query,支持retention policy,读写性能也是哇哇的,可以说是时间序列存储的完美方案,但是由于还很年轻,可能还会存在诸多的问题,就像现在正在开发的0.9一样,发布一拖再拖,就是由于还有些技术壁垒没有攻陷。
对于influxdb我不想多说些什么,之后打算开一个专题,专门详细来说一说这个玩意,因为我看国内几乎没有详细的文章来讲influxdb的。
总结
算是简单地说了一下,目前比较常用的三个时间序列数据库吧,可以看到各有优劣,在我们选型的时候,要根据自身情况来选择最适合自己的解决方案,其实我们现在也正在苦恼中,看似influxdb是最完美的解决方案,但是v0.9却是迟迟不出。opentsdb呢,虽然成熟,但是缺乏这方面的专家;graphite呢,性能太差,而且集群太死了。苦恼中啊……