Spark+Spark streaming+kafka简介和总结
接上文《Hadoop生态系统》,对Spark、Spark streaming、kafka的相关内容进行总结。
1、Hadoop和Spark的关系
Spark是为了跟Hadoop配合而开发出来的,不是为了取代Hadoop,专门用于大数据量下的迭代式计算。
Spark运算比Hadoop的MapReduce框架快的原因是因为Hadoop在一次MapReduce运算之后,会将数据的运算结果从内存写入到磁盘中,第二次MapReduce运算时再从磁盘中读取数据,所以其瓶颈在2次运算间的多余I/O消耗。Spark则是将数据一直缓存在内存中,直到计算得到最后的结果,再将结果写入到磁盘,所以多次运算的情况下,Spark是比较快的。
2、Spark生态系统
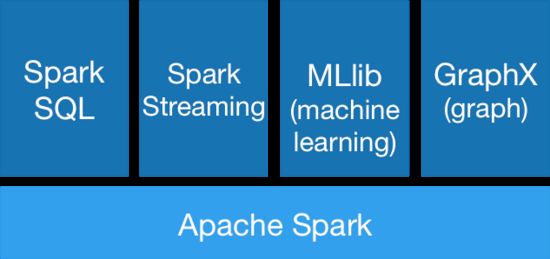
Spark SQL:提供类SQL的查询,返回Spark-DataFrame的数据结构;
Spark Streaming:流式计算,主要用于处理实时数据;
MLlib:提供机器学习的各种模型和调优;
GraphX:提供基于图的算法,如PageRank
3、什么是RDD
RDD俗称弹性分布式数据集,是Spark底层的分布式存储的数据结构,是Spark的核心。
在Spark 的设计思想中,为了减少网络及磁盘 IO 开销,需要设计出一种新的容错方式,于是才诞生了新的数据结构 RDD。RDD 是一种只读的数据块,可以从外部数据转换而来,你可以对RDD进行函数操作(Operation),包括 Transformation 和 Action。在这里只读表示当你对一个RDD进行了操作,那么结果将会是一个新的 RDD,这种情况放在代码里,假设变换前后都是使用同一个变量表示这一 RDD,RDD 里面的数据并不是真实的数据,而是一些元数据信息,记录了该 RDD 是通过哪些Transformation得到的,在计算机中使用lineage来表示这种血缘结构,lineage形成一个有向无环图 DAG,整个计算过程中,将不需要将中间结果落地到HDFS进行容错,加入某个节点出错,则只需要通过lineage关系重新计算即可。
RDD的操作函数(operation)主要分为2种类型 Transformation 和 Action。
| 类别 | 函数 | 区别 |
| Transformation | Map,filter,groupBy,join, union,reduce,sort,partitionBy | 返回值还是 RDD,不会马上提交 Spark 集群运行 |
| Action | count,collect,take,save, show | 返回值不是 RDD,会形成 DAG 图,提交 Spark 集群运行并立即返回结果 |
Transformation操作不是马上提交Spark 集群执行,Spark在遇到Transformation操作时只会记录需要这样的操作,并不会去执行,需要等到有Action操作的时候才会真正启动计算过程进行计算。针对每个Action,Spark会生成一个 Job,从数据的创建开始,经过Transformation,结尾是Action操作。这些操作对应形成一个有向无环图(DAG),形成DAG的先决条件是最后的函数操作是一个Action。
4、Spark Streaming
Spark Streaming是一种构建在Spark上的实时计算框架,它扩展了Spark处理大规模流式数据的能力。
首先,Spark Streaming把实时输入数据流以时间片Δt (如1秒)为单位切分成块,Spark Streaming会把每块数据作为一个RDD,并使用RDD操作处理每一小块数据,每个块都会生成一个Spark Job处理,最终结果也返回多块。 在Spark Streaming中,则通过操作DStream(表示数据流的RDD序列)提供的接口,这些接口和RDD提供的接口类似。
正如Spark Streaming最初的目标一样,它通过丰富的API和基于内存的高速计算引擎让用户可以结合流式处理,批处理和交互查询等应用。因此Spark Streaming适合一些需要历史数据和实时数据结合分析的应用场合。当然,对于实时性要求不是特别高的应用也能完全胜任,另外通过RDD的数据重用机制可以得到更高效的容错处理。
5、kafka
是一种高吞吐量的分布式、发布/订阅消息系统,可以同时支持离线数据处理和实时数据处理。
相当于一个数据管道,一方面对接生产者(生产系统),另一方面对接多个订阅者(分析系统);定时从生产系统获取数据,形成日志收集中心,通过增加订阅者接口,分析系统可以自定义数据提取规则,离线数据可以T+1批量发送,而实时数据可以按分钟级/秒级的频率获取数据。
参考文章:
Spark学习-Spark原理简述与shuffle过程介绍:http://blog.csdn.net/databatman/article/details/53023818?locationNum=4&fps=1
Spark简介:http://blog.csdn.net/qustqustjay/article/details/46874071
flume+kafka+spark streaming(持续更新):http://blog.csdn.net/xuyaoqiaoyaoge/article/details/55823381?locationNum=2&fps=1