前言:
电影票房预测项目中,我们需要根据电影的预算,类型,语言,发行时间,电影时长,受欢迎程度,演员信息,工作人员信息等信息来预测电影票房。
这篇文章主要是数据分析与可视化,具体的数据处理,特征工程,建模调参可以戳这里:kaggle电影票房预测(特征工程与建模调参)
)。
本次项目说明:
- 编程语言:Python
- 编译工具:jupyter notebook
- 涉及到的库:pandas,numpy,matplotlib,sklearn,seaborn,datetime,dateutil
- Kaggle链接:https://www.kaggle.com/c/tmdb-box-office-prediction
对数据分析,我们一方面是探究各个自变量与因变量revenue之间的关系,另一方面我们还可以探索各个变量自身的变化,比如哪些类型的电影最多,哪些演员最高产,电影公司最喜欢周几发行新作。
所以为了探索自变量本身的变化,我们可以将train_data和test_data合并,新建一个movie_data。
movie_data=pd.concat([train_data,test_data],ignore_index=True,axis=0)
1. belongs_to_collection/homepage/tagline/released和revenue的关系
belongs_to_collection/homepage/tagline/released这几列,我们都新增了一列来判断电影是否包含了相应的特征,所以其实这里我们是在对has_feature列进行分析。
%matplotlib notebook
fig = plt.figure()
plt.subplot2grid((4,2),(0,0))
sns.countplot(movie_data['has_collection'])
plt.subplot2grid((4,2),(0,1))
sns.boxplot(data=train_data,x='has_collection',y='revenue',showmeans=True)
plt.subplot2grid((4,2),(1,0))
sns.countplot(movie_data['has_homepage'])
plt.subplot2grid((4,2),(1,1))
sns.boxplot(data=train_data,x='has_homepage',y='revenue',showmeans=True)
plt.subplot2grid((4,2),(2,0))
sns.countplot(movie_data['has_tagline'])
plt.subplot2grid((4,2),(2,1))
sns.boxplot(data=train_data,x='has_tagline',y='revenue',showmeans=True)
plt.subplot2grid((4,2),(3,0))
sns.countplot(movie_data['has_Released'])
plt.subplot2grid((4,2),(3,1))
sns.boxplot(data=train_data,x='has_Released',y='revenue',showmeans=True)

从上面的图表中,我们可以得出以下信息:
- 系列电影数量要少于于非系列电影,但是系列电影的票房均值、中位数都要高于非系列电影
- 有官方主页的电影要少于没有主页的电影,但是有主页的电影票房均值、中位数都要高于没有主页的电影
- 大部分电影都有宣传标语,同样的,有宣传标语的电影的票房均值、中位数都要高于没有宣传标语的电影
- 只有极少数电影是非已发行状态,已发行的电影的票房均值、中位数要高于非发行状态的电影
发现系列电影的票房,不管是均值还是中位数都要高于非系列电影,这个也很容易理解,一个电影票房很好,公司自然想继续延续这个电影,继续赚钱!
2. budget与revenue的关系
sns.jointplot(data=train_data,x='budget',y='revenue',kind='scatter')

从散点图可以看大,绝大多数的电影预算都是在1亿以内,随着预算的增长,票房也呈现一个增长趋势,但是这个趋势并不是特别明显,因为一个电影的票房除了成本,还有剧本,演员演技,导演水平,宣发等多方面影像,毕竟,大制作的烂片我们也看到过不少了。
另外我们还可以通过时间维度观察,我们根据release_year进行聚合运算,求出每年的电影平均预算与收入来进行对比。
train_data.groupby(['release_year'])['budget'].agg('mean').plot()
train_data.groupby(['release_year'])['revenue'].agg('mean').plot()
plt.xticks(range(1921,2019,8))
plt.ylabel('average revenue')
plt.legend()

可以看到电影平均预算和平均收益都是在逐渐上升的,所以增加电影预算确实能一定程度上提高票房。
3. genres列与revenue的关系
首先我们看下,一个电影他所属的类型数量,以及类型数量与票房之间的关系。
sns.countplot(movie_data['genres_num'])

sns.boxplot(data=train_data,x='genres_num',y='revenue',showmeans=True)

从均值来看,呈现一个正态分布的关系,当电影的类型数量是4的时候,票房均值最高,过多和过少,票房都会往下降。
下面我们来看下,哪些电影类型产量最高,哪些电影类型最赚钱。
genres_top_df = pd.DataFrame(genres_top)
genres_top_list = list(genres_top_df[0])
sns.barplot(genres_top_df[0],genres_top_df[1])
plt.xlabel('genres')
plt.ylabel('count')
plt.xticks(fontsize=8,rotation=90)

剧情片的产量非常高,远高于其他类型的电影,不过我觉好像所有的电影都可以归类到剧情篇,这是不是剧情片产量非常高的原因呢?其他类型的话,喜剧,惊悚,动作,这些类型的电影产量也比较高。
下面来看下哪些电影最赚钱,我们根据各类型对应的票房均值来判断,需要注意的是由于一个电影是可以归属多个类型的,因此会存在重复的情况,这里是为什么在这里没有用sns.boxplot()的原因。
genres_average_revenue=[]
for i in (genres_top_list):
n = train_data[train_data['genres_'+i]==1]['revenue'].mean()
genres_average_revenue.append(n)
genres_average_revenue = pd.DataFrame({'genres':genres_top_list,'average revenue':genres_average_revenue})
sns.barplot(genres_average_revenue['genres'],genres_average_revenue['average revenue'])
plt.xticks(fontsize=8,rotation=90)

发现冒险类型的电影平均票房最高,其他的像科幻片,奇幻电影,动画片,家庭电影的平均票房也很高,反而高产的剧情片,喜剧片的平均票房较低,猜测是由于高产的同时水平层次不齐,所以平均票房也不高。
4. popularity列与revenue的关系
sns.jointplot(data=train_data,x='popularity',y='revenue',kind='scatter')

绝大多数电影的流行程度都在50以下,而且这里其实不是很清楚这个流行程度到底是怎么计算出来的,从散点图来看,似乎流行程度和revenue的关系并不明显。
5. production_companies列与revenue的关系
由于出品公司实在太多了,所以这里选取频次前10的公司进行分析。
companies_top_df = pd.DataFrame(companies_top[:10])
sns.barplot(companies_top_df[0],companies_top_df[1])
plt.xticks(rotation=90,fontsize=8)
plt.ylabel('count')
plt.xlabel('company')

时代华纳,环球影业,派拉蒙,21世纪福克斯是电影产量最高的4家公司,明显高于其他公司。
companies_top_list = list(companies_top_df[0].values)
companies_average_revenue=[]
for i in (companies_top_list):
n = train_data[train_data['companies_'+i]==1]['revenue'].mean()
companies_average_revenue.append(n)
companies_average_revenue = pd.DataFrame({'companies':companies_top_list,'average revenue':companies_average_revenue})
sns.barplot(companies_average_revenue['companies'],companies_average_revenue['average revenue'])
plt.xticks(fontsize=8,rotation=90)

平均票房最高的公司竟然是迪士尼,平均每部电影票房高达3亿,果然还是拍动画片赚钱。另外新线电影公司的平均票房也还不错,其他的一些大牌公司都是半斤八两,平均票房差不的不是特别多。
4.6 production_countries列与revenue的关系
countries_top_df = pd.DataFrame(countries_top[:10])
sns.barplot(countries_top_df[0],countries_top_df[1])
plt.xlabel('country')
plt.ylabel('count')
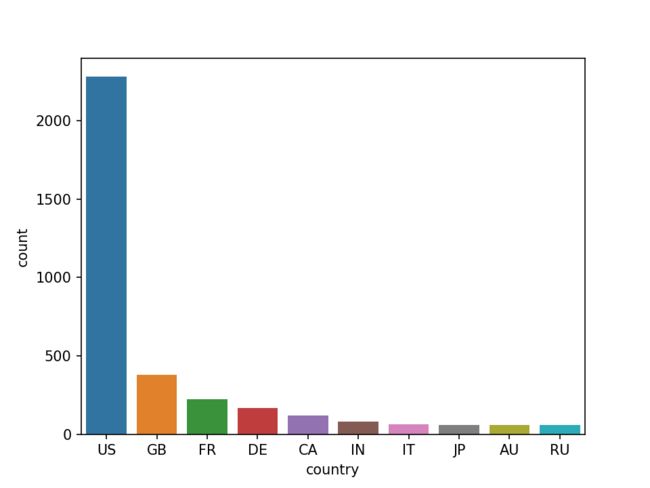
出品国家就不用说了,绝大多数电影都是美国公司出品,德国,法国排名2、3,但是和第一名美国比起来,差的还是有点远。
另外就是这个数据来源是TMDB,所以自然就是美国公司的电影为主,这也是导致美国公司和美国的电影产量特别高的原因。
countries_top_list = list(countries_top_df[0].values)
countries_average_revenue=[]
for i in (countries_top_list):
n = train_data[train_data['pr_countries_'+i]==1]['revenue'].mean()
countries_average_revenue.append(n)
countries_average_revenue = pd.DataFrame({'countries':countries_top_list,'average revenue':countries_average_revenue})
sns.barplot(countries_average_revenue['countries'],countries_average_revenue['average revenue'])
plt.xticks(fontsize=8,rotation=90)

从国家来看的话,美国出品的电影平均票房只是稍微领先其他国家,而俄罗斯电影则是平均票房非常低。
4.7 release_date列与revenue的关系
首先我们可以看下电影的发行与时间之间的关系,比如电影公司喜欢在周几发行电影,喜欢在哪一个月发行电影...
%matplotlib notebook
fig = plt.figure()
plt.subplot2grid((2,3),(0,0))
sns.countplot(movie_data['release_month'])
plt.subplot2grid((2,3),(0,1))
sns.countplot(movie_data['release_weekday'])
plt.ylabel('')
plt.subplot2grid((2,3),(0,2))
sns.countplot(movie_data['release_quarter'])
plt.ylabel('')
plt.subplot2grid((2,3),(1,0),colspan=3)
sns.countplot(movie_data['release_day'])

从上面的图中我们可以得到以下信息:
- 9月份是电影发行量最高的一个月份
- 星期五是电影发行量最多的日子
- 3季度是电影发行量最高的季度,9月也是在3季度,而1季度的电影发行量最少
- 每个月的1号的发行最高的日子
再来看下电影的发行量随着年份变化的趋势。
plt.figure(figsize=(20,12))
sns.countplot(movie_data['release_year'].sort_values())
plt.title("Movie Release count by Year",fontsize=20)
loc, labels = plt.xticks()
plt.xticks(fontsize=12,rotation=90)

可以发现,随着时间的推移,电影发行量逐渐升高,至于2017,2018突然降低,怀疑是数据的收录不足导致的。
下面再来看下电影平均票房与发行时间之间的关系。
%matplotlib notebook
fig = plt.figure()
plt.subplot2grid((2,3),(0,0))
train_data.groupby(['release_month'])['revenue'].agg('mean').plot()
plt.xticks(range(1,12,2))
plt.ylabel('average revenue')
plt.subplot2grid((2,3),(0,1))
train_data.groupby(['release_weekday'])['revenue'].agg('mean').plot()
plt.subplot2grid((2,3),(0,2))
train_data.groupby(['release_quarter'])['revenue'].agg('mean').plot()
plt.ylabel('')
plt.subplot2grid((2,3),(1,0),colspan=3)
train_data.groupby(['release_day'])['revenue'].agg('mean').plot()
plt.ylabel('average revenue')

这里发现一个很有意思的情况,就是9月,周五,3季度,每月的1号,这些都是电影发行量最多的时候,但是这些时候的平均票房都是时间段内最低点。
train_data.groupby(['release_year'])['revenue'].agg('mean').plot()
plt.xticks(range(1921,2019,8))
plt.ylabel('average revenue')

随着时间的增长,整个电影市场的平均票房都在稳步上升,其中1975年的时候,出现了一个小高潮,电影平均票房猛增。
4.8 runtime与revenue的关系
sns.jointplot(data=train_data,x='runtime',y='revenue')

runtime与revenue呈现一个正态分布,大部分电影的时长都在120min左右,这个时长电影的票房也是最高。
另外我们还可以看下电影时长随时间的变化趋势。
train_data.groupby(['release_year'])['runtime'].agg('mean').plot()
plt.ylabel('average runtime')
plt.title('average runtime by year')
plt.legend()

可以看到,在电影产业早期,那时候电影平均时长很不稳定,有的电影非常长,有的电影很短,到1980年之后,随着电影产业愈发成熟,电影平均时长稳定在110min左右。
4.9 cast与revenue的关系
cast_top_df = pd.DataFrame(cast_top[:10])
sns.barplot(cast_top_df[0],cast_top_df[1])
plt.xlabel('cast')
plt.ylabel('count')
plt.xticks(fontsize=8,rotation=90)

产量前10的演员都差的不多,其中塞缪尔·杰克逊(神盾局局长),罗伯特·德尼罗(教父)并列第一,都产出呢30部电影,前10内的其他演员其实产量都不低,最少的福里斯特·惠特克都产出了23部电影。
cast_top_list = list(cast_top_df[0].values)
cast_average_revenue=[]
for i in (cast_top_list):
n = train_data[train_data['cast_'+i]==1]['revenue'].mean()
cast_average_revenue.append(n)
cast_average_revenue = pd.DataFrame({'cast':cast_top_list,'average revenue':cast_average_revenue})
sns.barplot(cast_average_revenue['cast'],cast_average_revenue['average revenue'])
plt.xticks(fontsize=8,rotation=90)
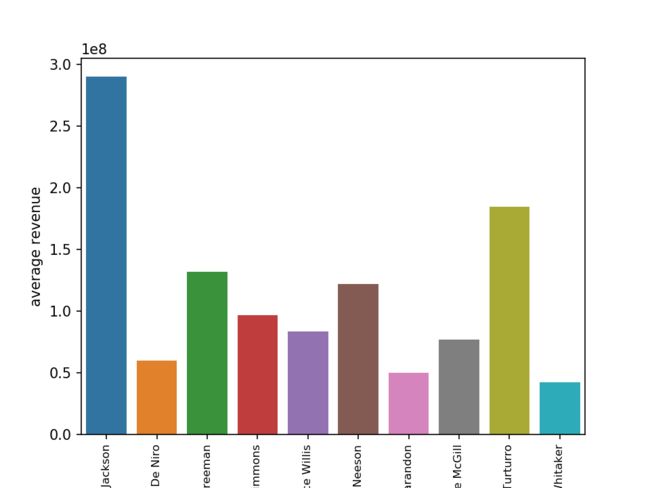
果然还是神盾局局长厉害,参演的电影平均票房远高于其他演员。
4.9 cast与revenue的关系
crew_top_df = pd.DataFrame(crew_top[:10])
sns.barplot(crew_top_df[0],crew_top_df[1])
plt.xlabel('crew')
plt.ylabel('count')
plt.xticks(fontsize=8,rotation=90)

频次前10的工作人员电影产出也差的不多,其中Avy Kaufman参与的电影数量最多,高达50部。
crew_top_list = list(crew_top_df[0].values)
crew_average_revenue=[]
for i in (crew_top_list):
n = train_data[train_data['crew_'+i]==1]['revenue'].mean()
crew_average_revenue.append(n)
crew_average_revenue = pd.DataFrame({'crew':crew_top_list,'average revenue':crew_average_revenue})
sns.barplot(crew_average_revenue['crew'],crew_average_revenue['average revenue'])
plt.xticks(fontsize=8,rotation=90)

从赚钱来看,还是斯皮尔伯格老爷子最赚钱,平均每部电影票房高达3亿。
以上就是对TMDB电影数据进行的数据分析和可视化,其实还可以拓展很多维度来分析,比如哪种类型的电影投资汇报比最高,哪些男演员最高产,哪些女演员最高产,最赚钱的导演又是谁?大家都可以多尝试下,会有很多有意思的发现。