JVM垃圾回收基本原理和实战系列之一
1、我们写的Java代码是怎么运行起来的?
首先假设咱们写好了一份Java代码,那这份Java代码中会包含很多“.java”为后缀的代码文件,比如User.java,OrderService.java,CustomerManager.java。咱们Java程序员平时在Eclipse、Intellij
IDEA等开发工具中,就有很多类似这样的Java源代码文件,当我们写好这些“.java”后缀的代码文件之后,接下来要部署到线上的机器上去运行,会怎么做?一般来说,都是把代码给打成“.jar”后缀的jar包,或者是“.war”后缀的war包,然后把打包好的jar包或者是war包给放到线上机器去部署。这个部署就有很多种途径了,但是最基本的一种方式,就是通过Tomcat这类容器来部署代码,也可以自己手动通过“java”命令来运行一个jar包中的代码。如下图:

这里有一个非常关键的步骤,那就是“编译”,也就是说,在我们写好的“.java”代码打包的过程中,一般就会把代码编译成“.class”后缀的字节码文件,比如“User.class”,“Hello.class”,”Customer.class“,然后这个“.class”后缀的字节码文件,才是可以被运行起来的!所以,首先,无论对JVM机制是否熟悉,都先来回顾一下这个编译的过程,以及“.class”字节码文件的概念。如下图:
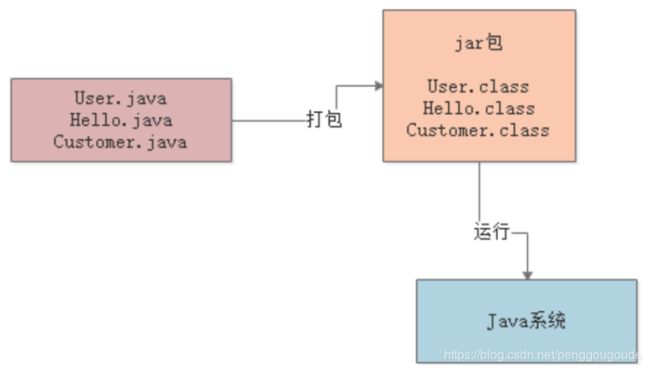
接着需要思考下一个问题:对于编译好的这些“.class”字节码,怎么让他们运行起来?这个时候就需要使用诸如“java -jar”之类的命令来运行我们写好的代码了。此时,一旦采用“java”命令,实际上就会启动一个JVM进程,这个JVM进程就会来负责运行这些“.class”字节码文件,也就相当于是负责运行我们写好的系统。所以,平时我们写好的某个系统在一台机器上部署的时候,一旦启动这个系统,其实就是启动了一个JVM进程,由它来负责运行这台机器上运行的这个系统。如下图:
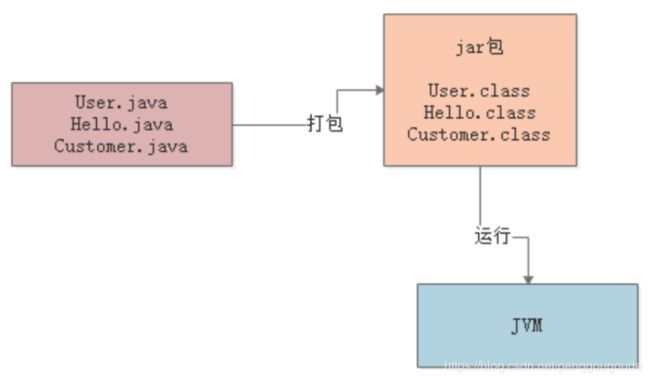
接着下一步,JVM进程要运行这些“.class”字节码文件中的代码,是不是首先得把这些“.class”文件中包含的各种类给加载进去?这些“.class”文件不就是我们写好的一个一个的类吗?此时就会有一个“类加载器”的概念,此时会采用类加载器把编译好的那些“.class”字节码文件给加载到JVM中,然后供后续代码运行来使用。如下图:
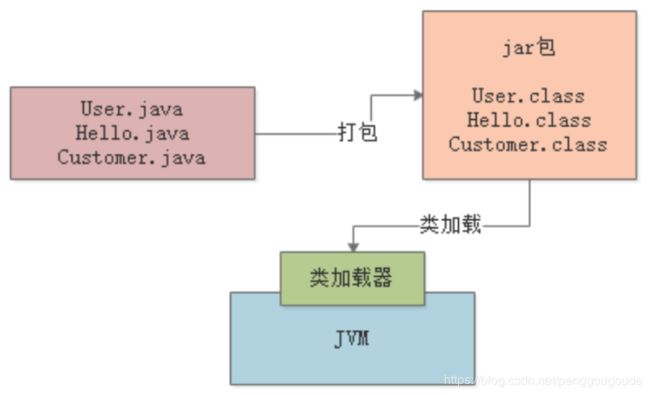
接着,最后一步,JVM就会基于自己的字节码执行引擎,来执行加载到内存里的我们写好的那些类了,比如代码中有一个“main()”方法,那么JVM就会从这个“main()”方法开始执行里面的代码。它需要哪个类的时候,就会使用类加载器来加载对应的类,反正对应的类就在“.class”文件中。如下图:
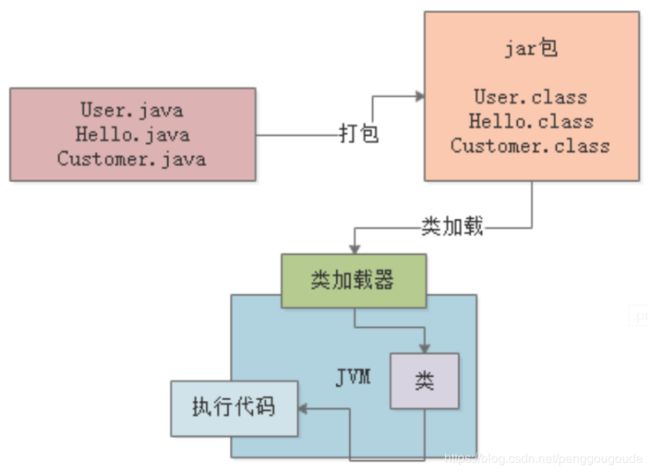
2、Java类加载机制是怎样的?
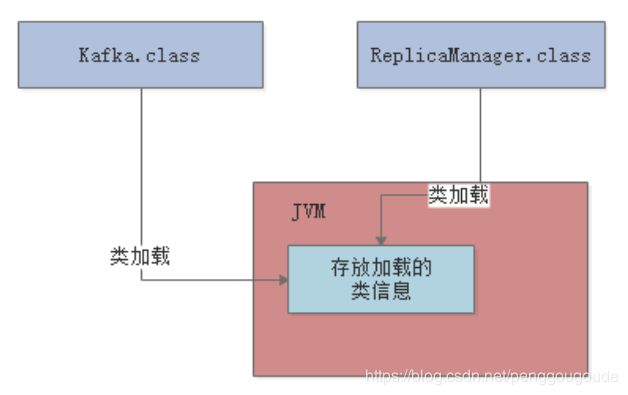
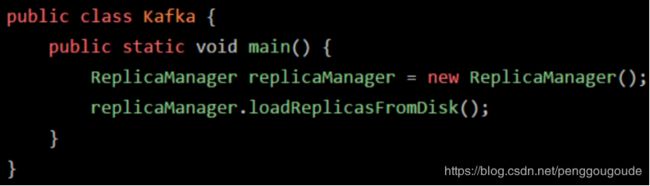
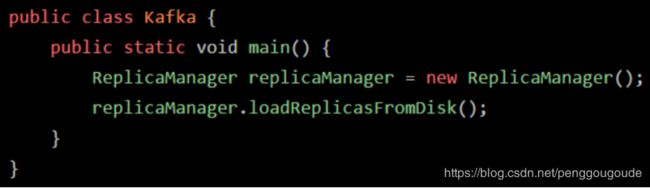
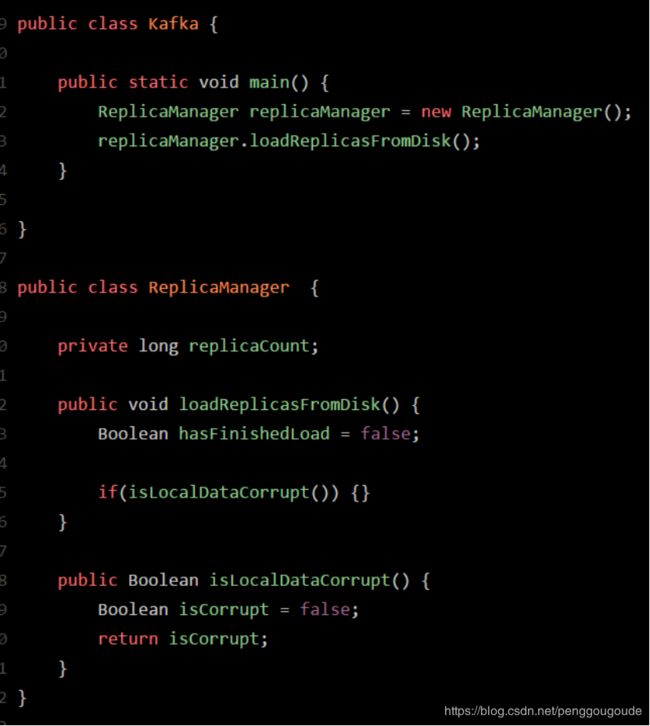
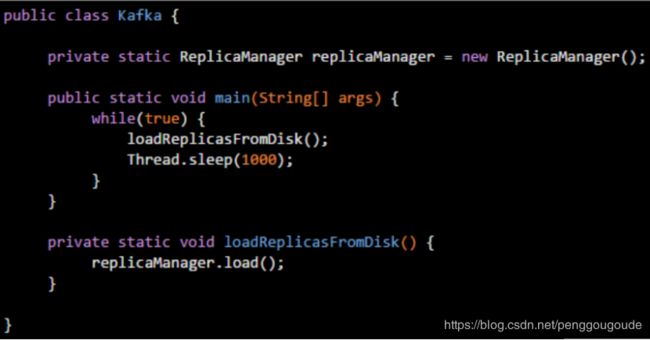
JVM会在什么情况下去加载一个类呢?其实,类加载过程非常的琐碎复杂,但是对于我们平时从工作中实用的角度来说,主要把握它的核心工作原理就可以。一个类从加载到使用,一般会经历下面的这个过程:加载 -> 验证 -> 准备 -> 解析 -> 初始化 -> 使用 -> 卸载。所以,首先要搞明白的第一个问题,就是JVM在执行我们写好的代码的过程中,一般在什么情况下会去加载一个类呢?也就是说,啥时候会从“.class”字节码文件中加载这个类到JVM内存里来。其实答案非常简单,就是在代码中用到这个类的时候。举个简单的例子,比如下面有一个类(Kafka.class),里面有一个“main()”方法作为主入口。那么一旦JVM进程启动之后,它一定会先把这个类(Kafka.cass)加载到内存里,然后从“main()”方法的入口代码开始执行。

假设main方法中有这么一行代码,如下图:
这时可能大家就想了,代码中明显需要使用“ReplicaManager”这个类去实例化一个对象,此时必须得把“ReplicaManager.class”字节码文件中的这个类加载到内存里来啊!所以这个时候就会触发JVM通过类加载器,从“ReplicaManager.class”字节码文件中加载对应的类到内存里来使用,这样代码才能跑起来。如下图:
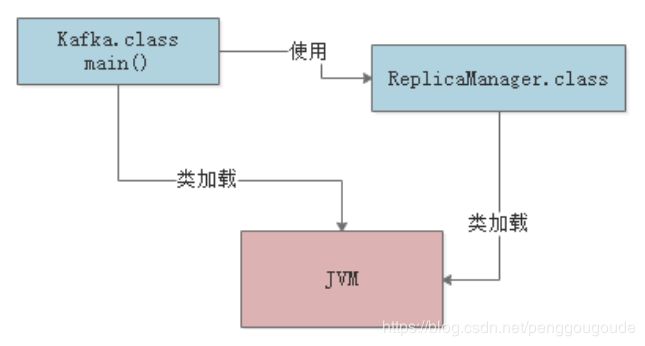
简单概括一下:首先代码中包含“main()”方法的主类一定会在JVM进程启动之后被加载到内存,开始执行“main()”方法中的代码。接着遇到使用了别的类,比如“ReplicaManager”,此时就会从对应的“.class”字节码文件加载对应的类到内存里来。下面从使用角度出发,来看看验证、准备和初始化的过程。
其实对于这三个概念,没太大的必要去深究里面的细节,这里面的细节很多很繁琐,对于大部分Java开发者而言,只要脑子里有下面的几个概念就可以了:
(1)验证阶段
简单来说,这一步就是根据Java虚拟机规范,来校验加载进来的“.class”文件中的内容,是否符合指定的规范。这个相信很好理解,假如说,“.class”文件被人篡改了,里面的字节码压根儿不符合规范,那么JVM是没法去执行这个字节码的!所以把“.class”字节码文件加载到内存里之后,必须先验证一下,校验它必须完全符合JVM规范,后续才能交给JVM来运行。如下图:
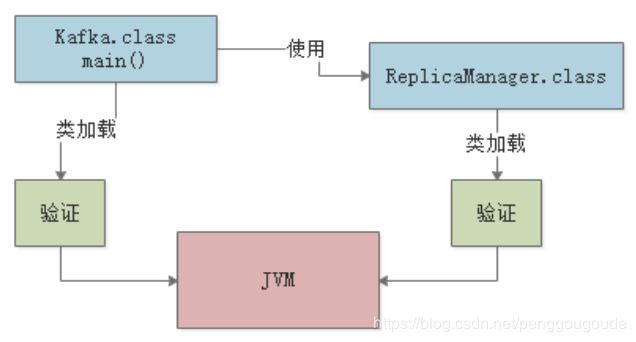
(2)准备阶段
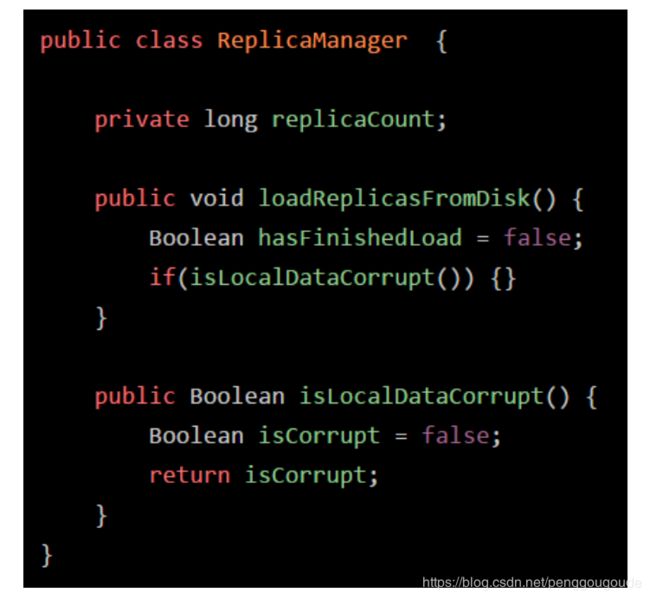
假设有这么一个“ReplicaManager”类,它的“ReplicaManager.class”文件内容刚刚被加载到内存之后,会进行验证,确认这个字节码文件的内容是规范的。接着就会进行准备工作,这个准备工作,其实就是给这个“ReplicaManager”类分配一定的内存空间,然后给它里面的类变量(也就是static修饰的变量)分配内存空间,来一个默认的初始值。比如上面的示例里,就会给“flushInterval”这个类变量分配内存空间,给一个“0”的初始值。如下图:

(3)解析阶段
这个阶段干的事儿,实际上是把符号引用替换为直接引用的过程,其实这个部分的内容很复杂,涉及到JVM的底层。针对这部分内容,没必要去深究,因为从实用角度而言,对很多Java开发者在工作中实践JVM技术其实也用不到,所以这里暂时知道有这么一个阶段就可以了。如下图:
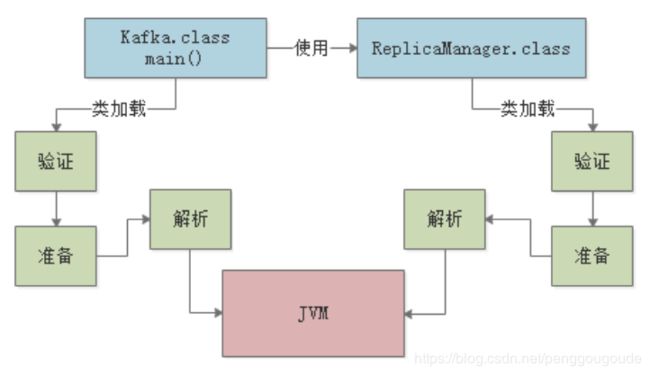
核心阶段:初始化
前面说过,在准备阶段时,就会把“ReplicaManager”类给分配好内存空间,另外它的一个类变量“flushInterval”也会给一个默认的初始值“0”,那么接下来,在初始化阶段,就会正式执行类初始化代码了。那么,什么是类初始化代码呢?如下图:
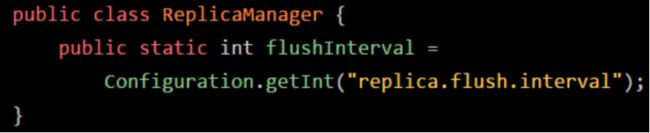
可以看到,对于“flushInterval”这个类变量,通过Configuration. getInt(“replica.flush.interval”)这段代码来获取一个值,并且赋值给它。但是在准备阶段会执行这个赋值逻辑吗?答案是NO!在准备阶段,仅仅是给“flushInterval”类变量开辟一个内存空间,然后给个初始值“0”罢了。那么这段赋值的代码什么时候执行呢?答案是在“初始化”阶段来执行。
在初始化这个阶段,就会执行类的初始化代码,比如上面的 Configuration.getInt(“replica.flush.interval”) 代码就会在这里执行,完成一个配置项的读取,然后赋值给这个类变量“flushInterval”。另外比如下图的static静态代码块,也会在这个阶段来执行。类似下面的代码语义,可以理解为类初始化的时候,调用“loadReplicaFromDish()”方法从磁盘中加载数据副本,并且放在静态变量“replicas”中:
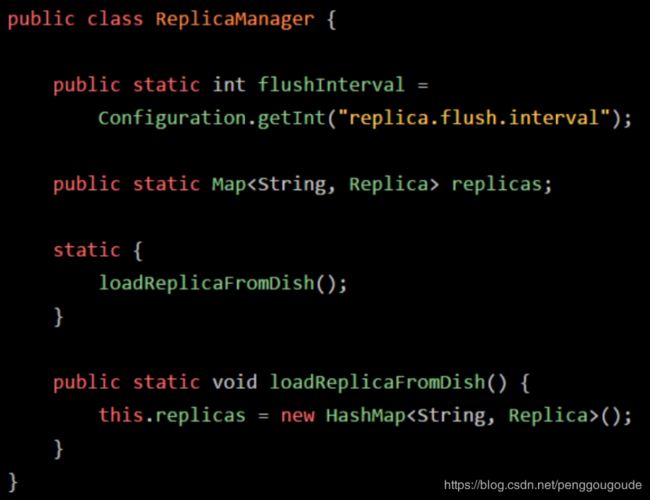
搞明白了类的初始化是什么,再来看看类的初始化规则。什么时候会初始化一个类?一般来说有以下一些时机:比如“new ReplicaManager()”来实例化类的对象了,此时就会触发类的加载到初始化的全过程,把这个类准备好,然后再实例化一个对象出来;或者是包含“main()”方法的主类,必须是立马初始化的。此外,这里还有一个非常重要的规则,就是如果初始化一个类的时候,发现他的父类还没初始化,那么必须先初始化他的父类,比如下面的代码:

如果要“new ReplicaManager()”初始化这个类的实例,那么会加载这个类,然后初始化这个类,但是初始化这个类之前,发现AbstractDataManager作为父类还没加载和初始化,那么必须先加载这个父类,并且初始化这个父类。这个规则,必须得牢记,如下图:

类加载器和双亲委派机制
现在搞明白了整个类加载从触发时机到初始化的过程,接着再阐述一下类加载器的概念。因为实现上述过程,那必须是依靠类加载器来实现的,那么Java里有哪些类加载器呢?简单来说有下面几种:
(1)启动类加载器
Bootstrap ClassLoader,它主要是负责加载在机器上安装的Java目录下的核心类的。相信大家都知道,如果要在一个机器上运行自己写好的Java系统,无论是Windows笔记本,还是Linux服务器,是不是都得装一个JDK?那么在Java安装目录下,就有一个“lib”目录,大家可以自己去找找看,这里就有Java最核心的一些类库,支撑Java系统的运行。所以一旦JVM启动,那么首先就会依托启动类加载器,去加载Java安装目录下的“lib”目录中的核心类库。
(2)扩展类加载器
Extension ClassLoader,这个类加载器其实也是类似的,就是Java安装目录下,有一个“lib\ext”目录,这里面有一些类,就是需要使用这个类加载器来加载的,支撑Java系统的运行。那么JVM一旦启动,是不是也得从Java安装目录下,加载这个“lib\ext”目录中的类。
(3)应用程序类加载器
Application ClassLoader,这类加载器就负责去加载“ClassPath”环境变量所指定的路径中的类,其实大致就理解为去加载写好的Java代码,这个类加载器就负责加载写好的那些类到内存里。
(4)自定义类加载器
除了上面那几种类加载器之外,还可以自定义类加载器,去根据自己的需求加载Java类。
JVM的类加载器是有亲子层级结构的,就是说启动类加载器是最上层的,扩展类加载器在第二层,第三层是应用程序类加载器,最后一层是自定义类加载器。如下图:

基于这个亲子层级结构,有一个双亲委派的机制,什么意思呢?就是假设应用程序类加载器需要加载一个类,它首先会委派给自己的父类加载器去加载,最终传导到顶层的类加载器去加载。但是如果父类加载器在自己负责加载的范围内,没找到这个类,那么就会下推加载权利给自己的子类加载器。
比如JVM现在需要加载“ReplicaManager”类,此时应用程序类加载器会问问自己的爸爸,也就是扩展类加载器,你能加载到这个类吗?然后扩展类加载器直接问自己的爸爸,启动类加载器,你能加载到这个类吗?启动类加载器心想,我在Java安装目录下,没找到这个类啊,自己找去!然后,就下推加载权利给扩展类加载器这个儿子,结果扩展类加载器找了半天,也没找到自己负责的目录中有这个类,这时它又会下推加载权利给应用程序类加载器这个儿子。然后应用程序类加载器在自己负责的范围内,比如就是写好的那个系统打包成的jar包,一下子发现,就在这里!然后就自己把这个类加载到内存里去了。这就是所谓的双亲委派模型:先找父亲去加载,不行的话再由儿子来加载,这样的话,可以避免多层级的加载器结构重复加载某些类。如下图:

3、JVM中有哪些内存区域,分别用来干嘛?
到底什么是JVM的内存区域划分?其实这个问题非常简单,JVM在运行我们写好的代码时,它是必须使用多块内存空间的,不同的内存空间用来放不同的数据,然后配合我们写的代码流程,才能让我们的系统运行起来。举个简单的例子,比如咱们现在知道了JVM会加载类到内存里来供后续运行,那么这些类加载到内存以后,放到哪儿去了呢?所以JVM里就必须有一块内存区域,用来存放我们写的那些类。如下图:
继续来看,我们的代码运行起来时,是不是需要执行写的一个一个的方法?那么运行方法的时候,方法里面有很多变量之类的东西,是不是需要放在某个内存区域里?接着如果我们写的代码里创建了一些对象,这些对象是不是也需要内存空间来存放?如下图:

这就是为什么JVM中必须划分出来不同的内存区域,它是为了我们写好的代码在运行过程中根据需要来使用的。接下来,就依次看看JVM中有哪些内存区域。
(1)存放类的方法区
这个方法区是在JDK 1.8以前的版本里,代表JVM中的一块区域,主要是放从“.class”文件里加载进来的类,还会有一些类似常量池的东西放在这个区域里。但是在JDK 1.8以后,这块区域的名字改了,叫做“Metaspace”,可以认为是“元数据空间”这样的意思。当然这里主要还是存放我们自己写的各种类相关的信息。举个例子,假设有一个“Kafka.class”类和“ReplicaManager.class”类,如下图:

这两个类加载到JVM后,就会放在这个方法区中,如下图:

(2)执行代码指令用的程序计数器
假设代码如下图:
前面讲过,实际上上面这段代码首先会存在于“.java”后缀的文件里,这个文件就是java源代码文件。但是这个文件是面向我们程序员的,计算机它是看不懂这段代码的。所以此时就得通过编译器,把“.java”后缀的源代码文件编译为“.class”后缀的字节码文件。这个“.class”后缀的字节码文件里,存放的就是对写出来的代码编译好的字节码了。字节码才是计算器可以理解的一种语言,而不是我们写出来的那一堆代码。字节码看起来大概是下面这样的,跟上面的代码无关,就是一个示例而已。
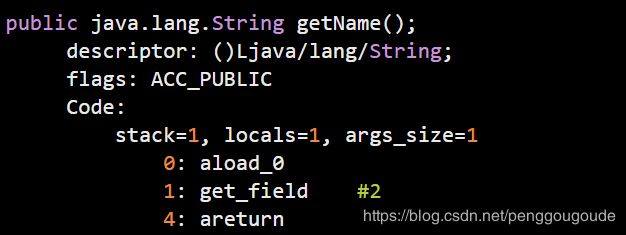
比如“0: aload_0”这样的,就是“字节码指令”,它对应了一条一条的机器指令,计算机只有读到这种机器码指令,才知道具体应该要干什么。比如字节码指令可能会让计算机从内存里读取某个数据,或者把某个数据写入到内存里去,都有可能,各种各样的指令就会指示计算机去干各种各样的事情。现在Java代码通过JVM跑起来的第一件事情就明确了, 首先Java代码被编译成字节码指令,然后字节码指令一定会被一条一条执行,这样才能实现我们写好的代码执行的效果。所以当JVM加载类信息到内存之后,实际就会使用自己的字节码执行引擎,去执行我们写的代码编译出来的代码指令。如下图:
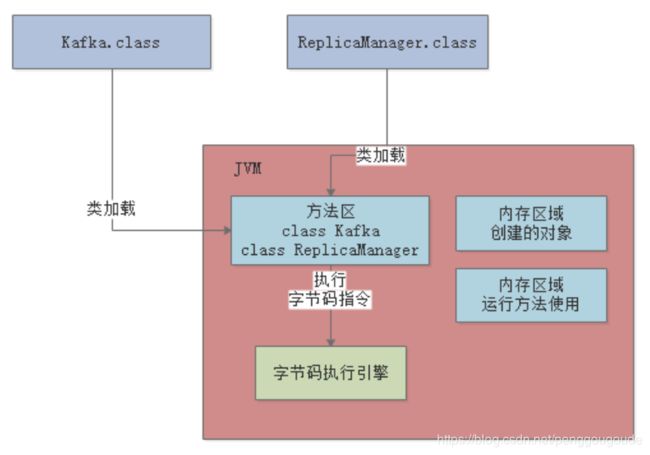
那么在执行字节码指令的时候,JVM里就需要一个特殊的内存区域,那就是“程序计数器”,这个程序计数器就是用来记录当前执行的字节码指令的位置的,也就是记录目前执行到了哪一条字节码指令。如下图:
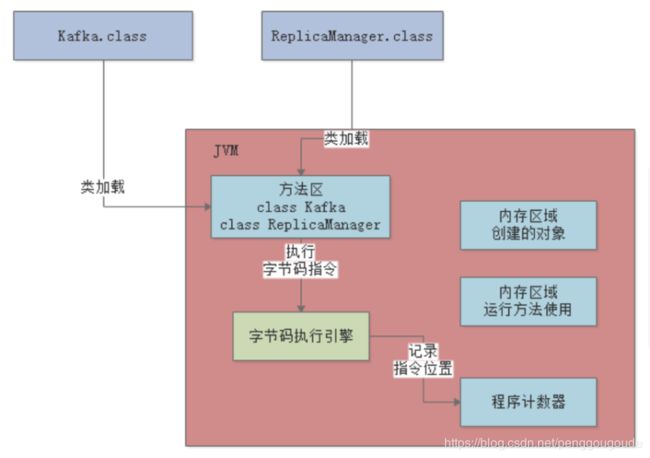
大家都知道JVM是支持多线程的,所以其实写好的代码可能会开启多个线程并发执行不同的代码,所以就会有多个线程来并发的执行不同的代码指令。因此每个线程都会有自己的一个程序计数器,专门记录当前这个线程目前执行到了哪一条字节码指令了。如下图:
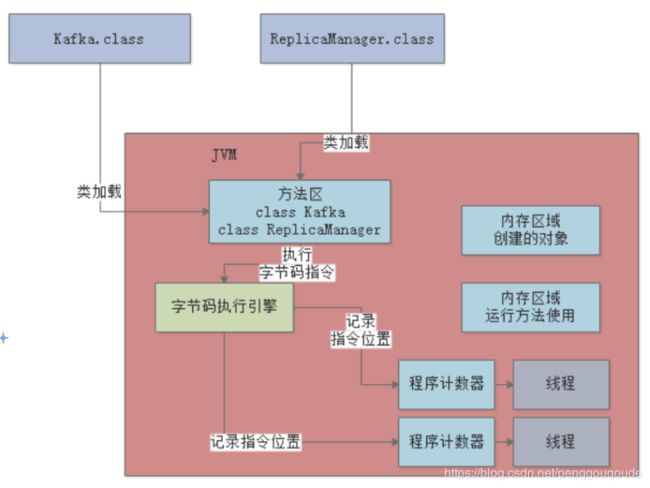
(3)Java虚拟机栈
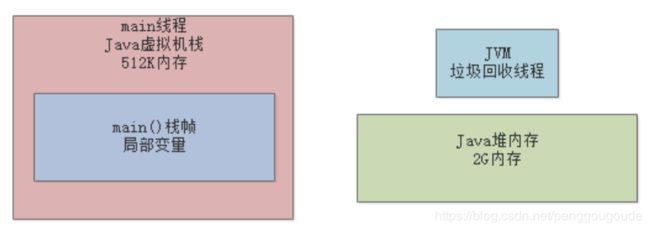
Java代码在执行的时候,一定是线程来执行某个方法中的代码,哪怕就是下面的代码,也会有一个main线程来执行main()方法里的代码。在main线程执行main()方法的代码指令的时候,就会通过main线程对应的程序计数器记录自己执行的指令位置。如下图:

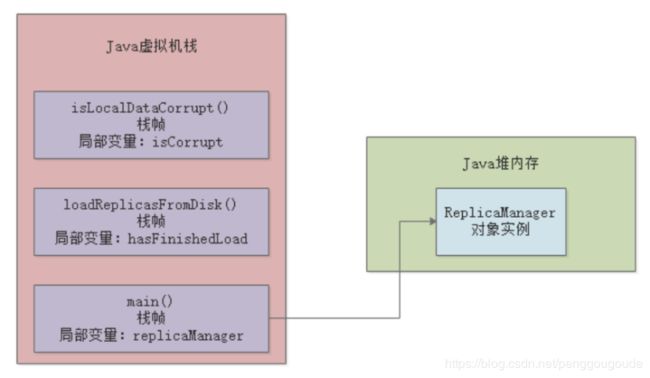
但是在方法里,我们经常会定义一些方法内的局部变量,比如在上面的main()方法里,其实就有一个“replicaManager”局部变量,它是引用一个ReplicaManager实例对象的,关于这个对象我们先不管它,先来看方法和局部变量。因此,JVM必须有一块区域是来保存每个方法内的局部变量等数据的,这个区域就是Java虚拟机栈。每个线程都有自己的Java虚拟机栈,比如这里的main线程就会有自己的一个Java虚拟机栈,用来存放自己执行的那些方法的局部变量。如果线程执行了一个方法,就会对这个方法调用创建对应的一个栈帧,栈帧里就有这个方法的局部变量表 、操作数栈、动态链接、方法出口等东西。比如main线程执行了main()方法,那么就会给这个main()方法创建一个栈帧,压入main线程的Java虚拟机栈,同时在main()方法的栈帧里,会存放对应的“replicaManager”局部变量。如下图:
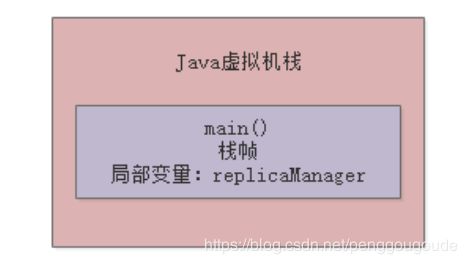
然后,假设main线程继续执行ReplicaManager对象里的方法,比如下面这样,在“loadReplicasFromDisk”方法里定义了一个局部变量:“hasFinishedLoad”。如下图:
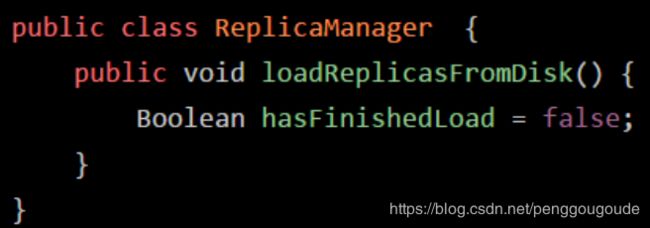
那么main线程在执行上面的“loadReplicasFromDisk”方法时,就会为“loadReplicasFromDisk”方法创建一个栈帧压入线程自己的Java虚拟机栈里面去。然后在栈帧的局部变量表里就会有“hasFinishedLoad”这个局部变量。如下图:
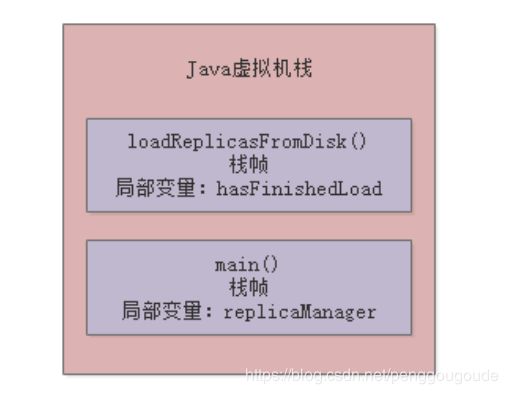
接着,如果“loadReplicasFromDisk”方法调用了另外一个“isLocalDataCorrupt()”方法 ,这个方法里也有自己的局部变量,比如下面这样的代码。如下图:

那么这个时候会给“isLocalDataCorrupt”方法又创建一个栈帧,压入线程的Java虚拟机栈里。而且“isLocalDataCorrupt”方法的栈帧的局部变量表里会有一个“isCorrupt”变量,这是“isLocalDataCorrupt”方法的局部变量,整个过程,如下图:

接着,如果“isLocalDataCorrupt”方法执行完毕了,就会把“isLocalDataCorrupt”方法对应的栈帧从Java虚拟机栈里给出栈。然后,如果“loadReplicasFromDisk”方法也执行完毕了,就会把“loadReplicasFromDisk”方法也从Java虚拟机栈里出栈。
上述就是JVM中的“Java虚拟机栈”这个组件的作用:调用执行任何方法时,都会给方法创建栈帧然后入栈,在栈帧里存放了这个方法对应的局部变量之类的数据,包括这个方法执行的其他相关的信息,方法执行完毕之后就出栈。如下图:
(4)Java堆内存
接下来,看看JVM中的另外一个非常关键的区域,就是Java堆内存,这里就是存放在代码中创建的各种对象的,比如下面的代码。如下图:
上面的“new ReplicaManager()”这个代码就是创建了一个ReplicaManager类的对象实例,这个对象实例里面会包含一些数据,如下面的代码所示。这个“ReplicaManager”类里的“replicaCount”就是属于这个对象实例的一个数据。类似ReplicaManager这样的对象实例,就会存放在Java堆内存里。如下图:
Java堆内存区域里会放入类似ReplicaManager的对象,然后因为在main方法里创建了ReplicaManager对象,那么在线程执行main方法代码的时候,就会在main方法对应的栈帧的局部变量表里,让一个引用类型的“replicaManager”局部变量来存放ReplicaManager对象的地址。相当于局部变量表里的“replicaManager”指向了Java堆内存里的ReplicaManager对象。如下图:
把上面这个图和下面这个总的大图一起串起来看,再配合整体的代码,捋一下整体的流程,看起来就会更加清晰。如下图:
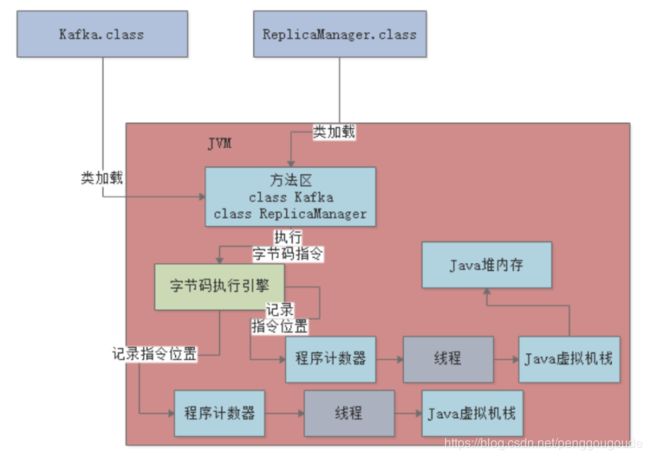
整体流程:
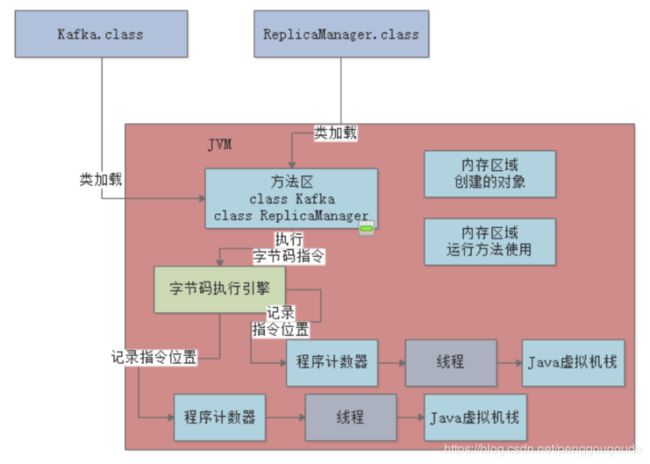
(1首先,JVM进程会启动,就会先加载Kafka类到内存里,然后有一个main线程,开始执行Kafka类中的main()方法;
(2main线程是关联了一个程序计数器的,那么它执行到哪一行指令,就会记录在这里。其次,就是main线程在执行main()方法的时候,会在main线程关联的Java虚拟机栈里,压入一个main()方法的栈帧;
(3接着会发现需要创建一个ReplicaManager类的实例对象,此时会加载ReplicaManager类到内存里来。然后会创建一个ReplicaManager的对象实例分配在Java堆内存里,并且在main()方法的栈帧里的局部变量表引入一个“replicaManager”变量,让他引用ReplicaManager对象在Java堆内存中的地址;
(4接着,main线程开始执行ReplicaManager对象中的方法,会依次把自己执行到的方法对应的栈帧压入自己的Java虚拟机栈,执行完方法之后再把方法对应的栈帧从Java虚拟机栈里出栈。
(5)其它内存区域
其实在JDK很多底层API里,比如IO相关的,NIO相关的,网络Socket相关的,如果去看它内部的源码,会发现很多地方都不是Java代码了,而是走的native方法去调用本地操作系统里面的一些方法,可能调用的都是c语言写的方法,或者一些底层类库,比如下面这样的:public native int hashCode()。在调用这种native方法的时候,就会有线程对应的本地方法栈,这个里面也是跟Java虚拟机栈类似的,也是存放各种native方法的局部变量表之类的信息。
还有一个区域,是不属于JVM的,通过NIO中的allocateDirect这种API,可以在Java堆外分配内存空间。然后,通过Java虚拟机里的DirectByteBuffer来引用和操作堆外内存空间。其实很多技术都会用这种方式,因为有一些场景,堆外内存分配可以大大提升性能,这里不做过多叙述。
4、JVM的垃圾回收机制用来干嘛的?
在Java代码中,一个方法执行完毕之后会怎么样?示例代码如下图:
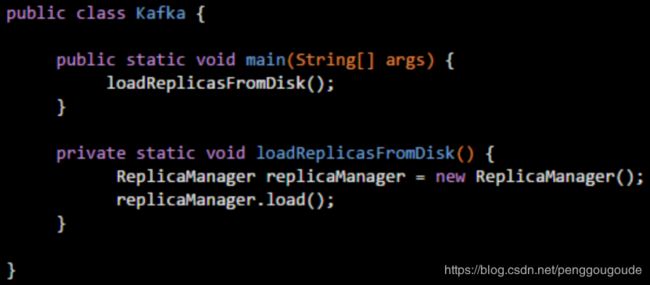
现在有个问题,如果“replicaManager.load()”这行代码执行结束了,此时会怎么样?前面说过,一旦方法里的代码执行完毕,那么方法就执行完毕了,也就是说loadReplicasFromDisk()方法就执行完毕了。一旦loadReplicasFromDisk()方法执行完毕,此时就会把loadReplicasFromDisk()方法对应的栈帧从main线程的Java虚拟机栈里出栈。如下图:

此时,一旦loadReplicasFromDisk()方法的栈帧出栈,那么会发现那个栈帧里的局部变量,“replicaManager”,也就没有了。也就是说,没有任何一个变量指向Java堆内存里的“ReplicaManager”实例对象了。核心点来了,此时发现了,Java堆内存里的那个“ReplicaManager”实例对象已经没有人引用它了。这个对象实际上已经没用了,该干的事儿都干完了,现在还让它留在内存里干啥呢?
一般来说,我们在一台机器上启动一个Java系统,机器的内存资源是有限的,比如就8个G的内存,然后我们启动的Java系统本质就是一个JVM进程,它负责运行我们的系统的代码。那么这个JVM进程本身也是会占用机器上的部分内存资源,比如占用2G的内存资源。那么,我们在JVM的Java堆内存中创建的对象,其实本质也是会占用JVM的内存资源的,比如“ReplicaManager”实例对象,会占用500字节的内存。如下图:
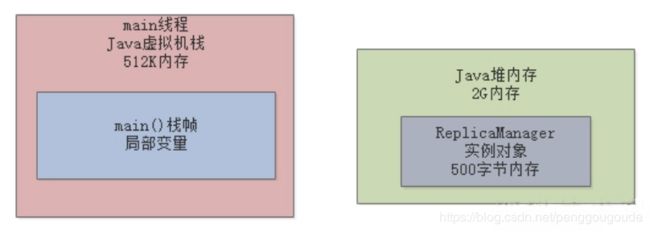
继续看上面这张图,既然“ReplicaManager”对象实例是不需要继续使用的,已经没有任何方法的局部变量在引用这个实例对象了,而且它还空占着内存资源,那么应该怎么处理呢?答案呼之欲出:JVM的垃圾回收机制。JVM本身是有垃圾回收机制的,它是一个后台自动运行的线程。只要启动一个JVM进程,它就会自带这么一个垃圾回收的后台线程。这个线程会在后台不断检查JVM堆内存中的各个实例对象。如下图:

如果某个实例对象没有任何一个方法的局部变量指向它,也没有任何一个类的静态变量,包括常量等在指向它,那么这个垃圾回收线程,就会把这个没人指向的“ReplicaManager”实例对象给回收掉,从内存里清除掉,让它不再占用任何内存资源。这样的话,这些不再被人指向的对象实例,即JVM中的“垃圾”,就会定期的被后台垃圾回收线程清理掉,不断释放内存资源。如下图:

到此为止,相信大家就很清晰明了了,到底什么是JVM中的“垃圾”?什么又是JVM的“垃圾回收”?
5、JVM分代模型:年轻代、老年代、永久代
大家应该都知道一点,那就是我们在代码里创建的对象,都会进入到Java堆内存中,如下图:
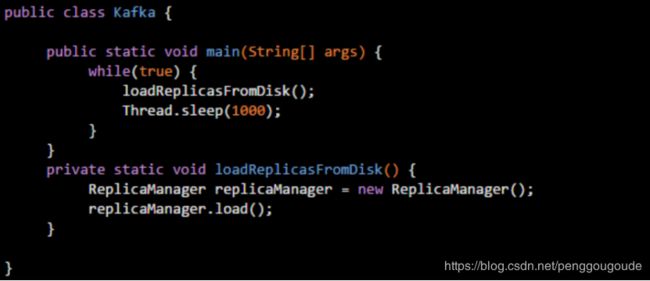 这段代码,稍微做了点改动,在main()方法里,会周期性的执行loadReplicasFromDisk()方法,加载副本数据。首先,一旦执行main()方法,那么就会把main()方法的栈帧压入main线程的Java虚拟机栈,如下图:
这段代码,稍微做了点改动,在main()方法里,会周期性的执行loadReplicasFromDisk()方法,加载副本数据。首先,一旦执行main()方法,那么就会把main()方法的栈帧压入main线程的Java虚拟机栈,如下图:
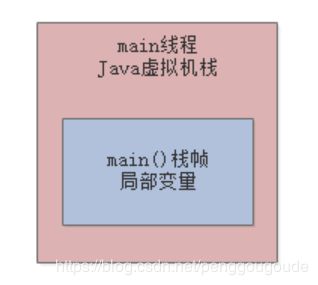
然后每次在while循环里,调用loadReplicasFromDisk()方法,就会把loadReplicasFromDisk()方法的栈帧压入自己的Java虚拟机栈,如下图:
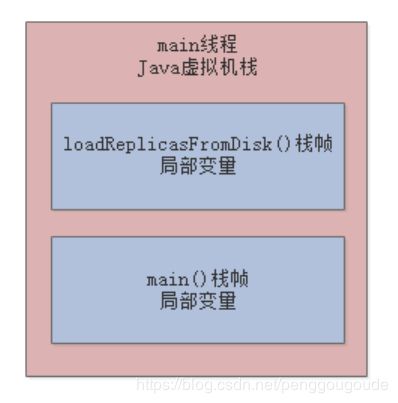
接着在执行loadReplicasFromDisk()方法的时候,会在Java堆内存里创建一个ReplicaManager对象实例,而且loadReplicasFromDisk()方法的栈帧里会有“replicaManager”局部变量去引用Java堆内存里的ReplicaManager对象实例,如下图:
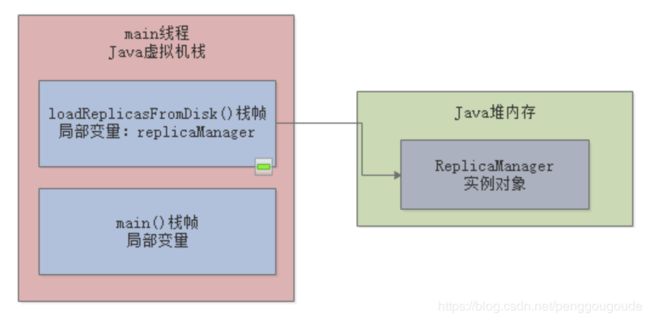
然后就会执行ReplicaManager对象的load()方法。
大部分对象都是存活周期极短的
现在有一个问题,在上面代码中,那个ReplicaManager对象,实际上属于短暂存活的这么一个对象,在loadReplicasFromDisk()方法中创建这个对象,然后执行ReplicaManager对象的load()方法,然后执行完毕之后,loadReplicasFromDisk()方法就会结束。一旦方法结束,那么loadReplicasFromDisk()方法的栈帧就会出栈,如下图:
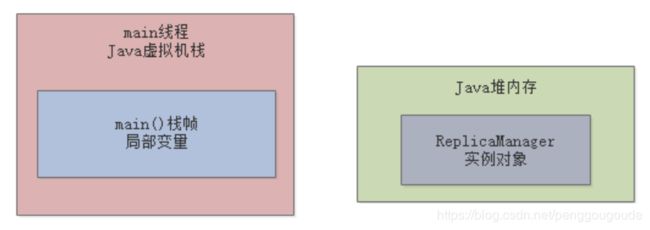
此时一旦没人引用这个ReplicaManager对象了,就将会被JVM的垃圾回收线程给回收,释放内存空间,如下图:
然后在main()方法的while循环里,下一次循环再次执行loadReplicasFromDisk()方法的时候,又会走一遍上面那个过程,把loadReplicasFromDisk()方法的栈帧压入Java虚拟机栈,然后构造一个ReplicaManager实例对象放在Java堆里。一旦执行完ReplicaManager对象的load()方法之后,loadReplicasFromDisk()方法又会结束,再次出栈,然后垃圾回收释放掉Java堆内存里的ReplicaManager对象。
所以其实这个ReplicaManager对象,在上面的代码中,是一个存活周期极为短暂的对象,每次执行loadReplicasFromDisk()方法的时候,被创建出来,然后执行他的load()方法,接着可能1毫秒之后,就被垃圾回收掉了。从这段代码就可以明显看出来,大部分在代码里创建的对象,其实都是存活周期很短的。这种对象,其实在我们写的Java代码中,占到绝大部分的比例。
少数对象是长期存活的
下面来看另外一段代码,假如说用下面这种方式来实现同样的功能,如下图:
上面这段代码的意思,就是给Kafka这个类定义一个静态变量,也就是“replicaManager”,这个Kafka类是在JVM的方法区里的。然后让“replicaManager”引用了一个在Java堆内存里创建的ReplicaManager实例对象,如下图:
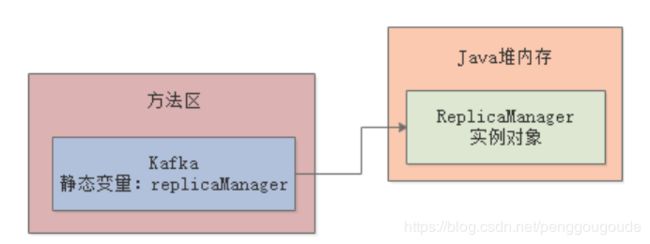
接着在main()方法中,就会在一个while循环里,不停的调用ReplicaManager对象的load()方法,做成一个周期性运行的模式。这个时候,就要来思考一下,这个ReplicaManager实例对象,它是会一直被Kafka的静态变量引用的,然后会一直驻留在Java堆内存里,是不会被垃圾回收掉的。因为这个实例对象它需要长期被使用,周期性的被调用load()方法,所以它就成为了一个长时间存在的对象。
那么类似这种被类的静态变量长期引用的对象,它需要长期停留在Java堆内存里,这种对象就是生存周期很长的对象,它是轻易不会被垃圾回收的,它需要长期存在,不停的去使用它。
JVM分代模型:年轻代和老年代
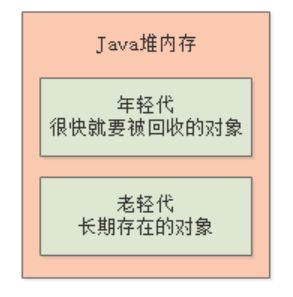
可以看到,根据写代码方式的不同,采用不同的方式来创建和使用对象,其实对象的生存周期是不同的。所以JVM将Java堆内存划分为了两个区域,一个是年轻代,一个是老年代。其中年轻代,顾名思义,就是把第一种代码示例中的那种,创建和使用完之后立马就要回收的对象放在里面;然后老年代呢,就是把第二种代码示例中的那种,创建之后需要一直长期存在的对象放在里面,如下图:
比如下面的代码,再次改造一下,再结合图,能够看得更加明确一些,如下图:
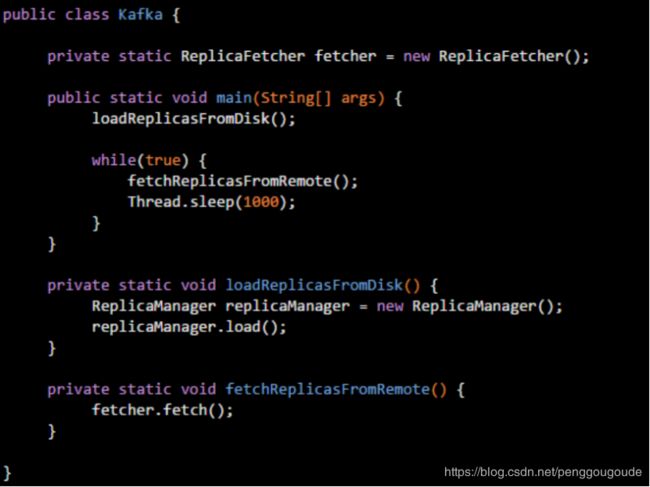
上面这段代码稍微复杂了点,稍微解释一下,Kafka的静态变量“fetcher”引用了ReplicaFetcher对象,这是长期需要驻留在内存里使用的,这个对象会在年轻代里驻留一段时间,但是最终会进入老年代,如下图:
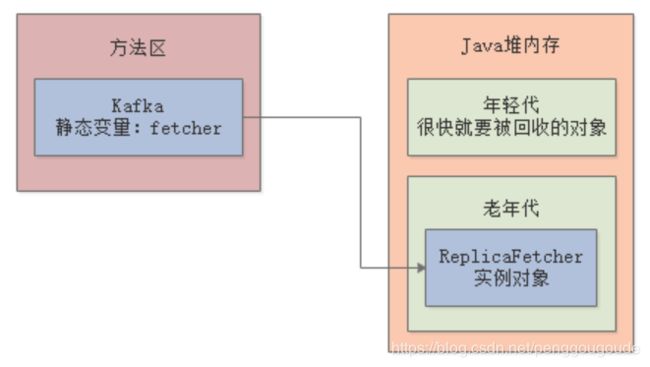
进入main()方法之后,会先调用loadReplicasFromDisk()方法,业务含义是系统启动就从磁盘加载一次副本数据,这个方法的栈帧会入栈;然后在这个方法里面创建了一个ReplicaManager对象,这个对象它是用完就会回收,所以是会放在年轻代里,由栈帧里的局部变量来引用,如下图:

然后一旦loadReplicasFromDisk()方法执行完毕了,方法的栈帧就会出栈,对应的年轻代里的ReplicaManager对象也会被回收掉,如下图:
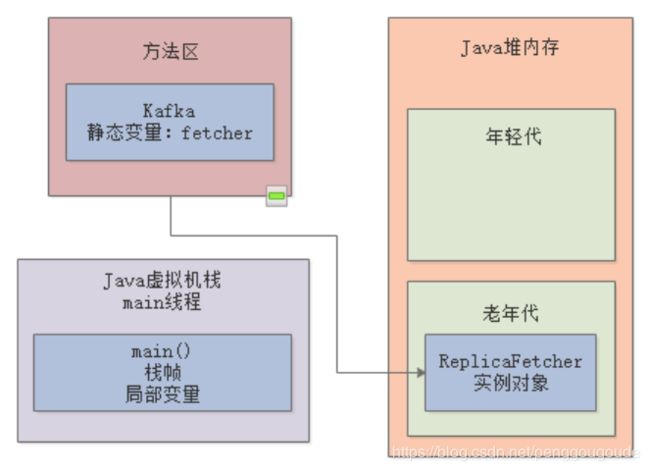
但是接着会执行一段while循环代码,它会周期性地调用ReplicaFetcher的fetch()方法,去从远程加载副本数据。所以ReplicaFetcher这个对象因为被Kafka类的静态变量fetcher给引用了,所以它会长期存在于老年代里,持续被使用。
为什么要分成年轻代和老年代?
相信看到这里,大家就一定看明白了,什么样的对象是短期存活的对象,什么样的对象是长期存在的对象,然后如何分别存在于年轻代和老年代里。那么为什么需要这么区分呢?因为这跟JVM的垃圾回收有关,对于年轻代里的对象,它们的特点是创建之后很快就会被回收,所以需要用一种垃圾回收算法;对于老年代里的对象,他们的特点是需要长期存在,所以需要另外一种垃圾回收算法,所以需要分成两个区域来放不同的对象。
什么是永久代?
很简单,JVM里的永久代简单说就是方法区,上面那个图里的方法区,其实就是所谓的永久代,可以认为永久代就是放一些类信息的。
文章主要内容摘自:
《从零开始带你成为JVM实战高手》 ————阿里大神*救火队队长
花一包烟的钱,看到不一样的技术世界:

共同学习,共同进步!