Es Bucket聚合(桶聚合) 第二篇-Terms Aggregation与Significant Terms Aggregation
作者介绍:《RocketMQ技术内幕》作者,中间件兴趣圈微信公众号维护者,文末有对应的二维码,关注后可以与作者更好的互动。
本章将介绍elasticsearch最重要的桶聚合terms aggregation。
1、Terms Aggregation
多值聚合,根据库中的文档动态构建桶。基于词根的聚合,如果聚合字段是text的话,会对一个一个的词根进行聚合,通常不会在text类型的字段上使用聚合,对标关系型数据中的(Group By)。
官方示例如下:
GET /_search
{
"aggs" : {
"genres" : {
"terms" : { "field" : "genre" }
}
}
}
返回结果如下:
{
...
"aggregations" : {
"genres" : {
"doc_count_error_upper_bound": 0, // @1
"sum_other_doc_count": 0, // @2
"buckets" : [ // @3
{
"key" : "electronic",
"doc_count" : 6
},
{
"key" : "rock",
"doc_count" : 3
},
{
"key" : "jazz",
"doc_count" : 2
}
]
}
}
}
返回结果@1:该值表示未进入最终术语列表的术语的最大潜在文档计数,下文还会详细分析。
返回结果@2:当有很多词根时,Elasticsearch只返回最上面的项;这个数字是所有不属于响应的bucket的文档计数之和,其搜索过程在下文会讲到。
返回结果@3:返回的结果,默认情况下,返回doc_count排名最前的10个,受size参数的影响,下面会详细介绍。
1.1 Terms 聚合支持如下常用参数:
- size
可以通过size返回top size的文档,该术语聚合针对顶层术语(不包含嵌套词根),其搜索过程是将请求向所有分片节点发送请求,每个分片节点返回size条数据,然后聚合所有分片的结果(会对各分片返回的同样词根的数数值进行相加),最终从中挑选size条记录返回给客户端。从这个过程也可以看出,其结果并不是准确的,而是一个近似值。 - Shard Size
为了提高该聚合的精确度,可以通过shard_size参数设置协调节点向各个分片请求的词根个数,然后在协调节点进行聚合,最后只返回size个词根给到客户端,shard_size >= size,如果shard_size设置小于size,ES会自动将其设置为size,默认情况下shard_size建议设置为(1.5 * size + 10)。
1.2 Calculating Document Count Error
为了阐述返回结果中的doc_count_error_upper_bound、sum_other_doc_count代表什么意思,我们通过如下例子来说明Term Aggregations的工作机制。
例如在三个分片上关于产品的初始聚合信息如下:

现在统计size=5的term Aggregations,协调节点向Shard A、B、C分别请求前5条聚合信息,如下图所示:

根据这些返回的结果,在协调节点上聚合,最终得出如下响应结果:
{
...
"aggregations" : {
"products" : {
"doc_count_error_upper_bound" : 46,
"sum_other_doc_count" : 79,
"buckets" : [
{
"key" : "Product A",
"doc_count" : 100
},
{
"key" : "Product Z",
"doc_count" : 52
}
{
"key" : "Product C",
"doc_count" : 50
}
{
"key" : "Product G",
"doc_count" : 45
}
...
]
}
}
}
那doc_count_error_upper_bound、sum_other_doc_count又分别代表什么呢?
-
doc_count_error_upper_bound
该值表示未进入最终术语列表的术语的最大潜在文档计数。这是根据从每个碎片返回的上一项的文档计数之和计算的(协调节点根据每个分片节点返回的最后一条数据相加得来的)。这意味着在最坏的情况下,没有返回的词根的最大文档个数为46个,在此次聚合结果中排名第4。 -
sum_other_doc_count
未纳入本次聚合结果中的文档总数量,这个容易理解。

1.3 Per bucket Document Count Error
每个桶的错误文档数量,可以通过参数show_term_doc_count_error=true来展示每个文档未被纳入结果集的数量。
其使用示例如下:
GET /_search
{
"aggs" : {
"products" : {
"terms" : {
"field" : "product",
"size" : 5,
"show_term_doc_count_error": true
}
}
}
}
对应的返回值:
{
...
"aggregations" : {
"products" : {
"doc_count_error_upper_bound" : 46,
"sum_other_doc_count" : 79,
"buckets" : [
{
"key" : "Product A",
"doc_count" : 100,
"doc_count_error_upper_bound" : 0
},
{
"key" : "Product Z",
"doc_count" : 52,
"doc_count_error_upper_bound" : 2
}
...
]
}
}
}
1.4 order
可以设置桶的排序,默认是按照桶的doc_count降序排序的。
order的可选值:
- “order” : { “_count” : “asc” }
- “order” : { “_key” : “asc” }
- 支持子聚合的结果作为排序字段。
GET /_search
{
"aggs" : {
"genres" : {
"terms" : {
"field" : "genre",
"order" : { "max_play_count" : "desc" } // "order" : { "playback_stats.max" : "desc" }
},
"aggs" : {
"max_play_count" : { "max" : { "field" : "play_count" } } // "playback_stats" : { "stats" : { "field" : "play_count" } }
}
}
}
}
“order” : { “playback_stats.max” : “desc” }其中键的书写规则如下:
用 > 分隔聚合名称,用.分开METRIC类型的聚合。
1.5 Minimum document count
通过指定min_doc_count来过滤匹配文档数量小于该值的桶。
1.6 Filtering values(值过滤)
对值使用正则表达式进行过滤,示例如下:
GET /_search
{
"aggs" : {
"tags" : {
"terms" : {
"field" : "tags",
"include" : ".*sport.*", // include 包含
"exclude" : "water_.*" // exclude 排除
}
}
}
}
精确值匹配
"JapaneseCars" : {
"terms" : {
"field" : "make",
"include" : ["mazda", "honda"]
}
}
分区过滤:
GET /_search
{
"size": 0,
"aggs": {
"expired_sessions": {
"terms": {
"field": "account_id",
"include": {
"partition": 0, // @1
"num_partitions": 20 // @2
},
"size": 10000,
"order": {
"last_access": "asc"
}
},
"aggs": {
"last_access": {
"max": {
"field": "access_date"
}
}
}
}
}
}
分区的意思就是将值分成多个组,没一个请求只处理其中一个组,其中参数 @1表示请求的分组ID,num_partitions表示总共的分组数。
1.7 Multi-field terms aggregation
多字段词根聚合。terms aggregation不支持从同一文档中的多个字段收集词根。因为terms aggregation本身并不收集所有的词根,而是使用全局序数来生成字段中所有惟一值的列表。全局序数会带来重要的性能提升,而这在多个字段中是不可能实现的。
有两种方法可以用于跨多个字段执行term aggregation:
- script
使用脚本方式,目前暂不探讨其脚本的使用。 - copy_to field
使用copy_to在映射中聚合多个字段。
1.8 Collect mode
收集模式,ES支持两种收集模式:
- depth_first:深度优先,默认值。
- breadth_first:广度优先。
首先我们先学习一下树的基本知识(深度遍历与广度遍历),例如有如下一颗二叉树:
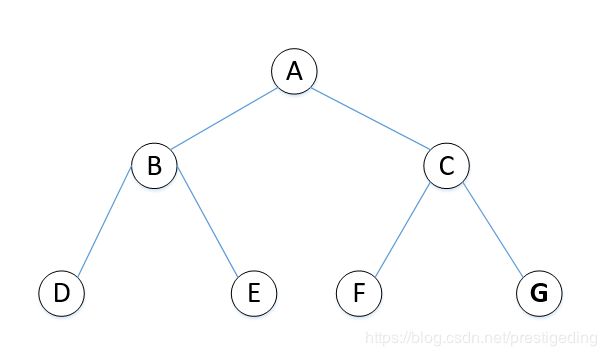
深度遍历:深度遍历是从一个节点开始,先遍历完该节点所有的子节点,然后再返回遍历它的兄弟节点,通常深度遍历分为中序遍历、前序遍历,后序遍历。
- 中序遍历(遍历左子树–>访问根–>遍历右子树):D B E A F C G
- 前序遍历(访问根–>遍历左子树–>遍历右子树):A B D E C F G
- 后序遍历(遍历左子树–>遍历右子树–>访问根):D E B F G C A
- 广度遍历(一层一层遍历):A B C D E F G
广度优先聚合与深度优先聚合的构建流程(聚合流程)与其遍历顺序一致。
下面我们以官方的示例来进一步说明:
例如现在有一个电影的文档,其索引中的数据如下:

现在要统计出演电视剧最多的演员(前3),并且和这些演员合作次数最多的演员。
其聚合语法如下:
GET /_search
{
"aggs" : {
"actors" : {
"terms" : {
"field" : "actors",
"size" : 3,
“shard_size” : 50
"collect_mode" : "breadth_first"
},
"aggs" : {
"costars" : { // 子聚合
"terms" : {
"field" : "actors",
"size" : 5
}
}
}
}
}
}
对应的JAVA示例如下:
public static void test_term_aggregation_collect_mode() {
RestHighLevelClient client = EsClient.getClient();
try {
SearchRequest searchRequest = new SearchRequest();
searchRequest.indices("movies_index");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
AggregationBuilder aggregationBuild = AggregationBuilders.terms("actors_agg")
.field("actors")
.size(3)
.shardSize(50)
.collectMode(SubAggCollectionMode.BREADTH_FIRST)
.subAggregation(AggregationBuilders.terms("costars_agg")
.field("actors")
.size(3))
;
sourceBuilder.aggregation(aggregationBuild);
sourceBuilder.size(0);
searchRequest.source(sourceBuilder);
SearchResponse result = client.search(searchRequest, RequestOptions.DEFAULT);
System.out.println(result);
} catch (Throwable e) {
e.printStackTrace();
} finally {
EsClient.close(client);
}
}
返回结果如下:
{
... // 省略
"aggregations":{
"sterms#actors_agg":{
"doc_count_error_upper_bound":0,
"sum_other_doc_count":30,
"buckets":[
{
"key":"赵丽颖",
"doc_count":3,
"sterms#costars_agg":{
"doc_count_error_upper_bound":0,
"sum_other_doc_count":19,
"buckets":[
{
"key":"赵丽颖",
"doc_count":3
},
{
"key":"俞灏明",
"doc_count":1
},
{
"key":"冯绍峰",
"doc_count":1
}
]
}
},
{
"key":"李亚鹏",
"doc_count":2,
"sterms#costars_agg":{
"doc_count_error_upper_bound":0,
"sum_other_doc_count":8,
"buckets":[
{
"key":"李亚鹏",
"doc_count":2
},
{
"key":"吕丽萍",
"doc_count":1
},
{
"key":"周杰",
"doc_count":1
}
]
}
},
{
"key":"俞灏明",
"doc_count":1,
"sterms#costars_agg":{
"doc_count_error_upper_bound":0,
"sum_other_doc_count":5,
"buckets":[
{
"key":"俞灏明",
"doc_count":1
},
{
"key":"刘凡菲",
"doc_count":1
},
{
"key":"孟瑞",
"doc_count":1
}
]
}
}
]
}
}
}
深度遍历优先的执行路径:
开始对整个电影库进行搜索,从文档中得出第一个影员,例如赵丽颖,然后立马执行子聚合,首先刷选出有赵丽颖参与的文档集中的词根,并聚合其数量,排名前3的组成一个聚合结果,生成类似于:
{
"key":"赵丽颖",
"doc_count":3,
"sterms#costars_agg":{
"doc_count_error_upper_bound":0,
"sum_other_doc_count":19,
"buckets":[
{
"key":"赵丽颖",
"doc_count":3
},
{
"key":"俞灏明",
"doc_count":1
},
{
"key":"冯绍峰",
"doc_count":1
}
]
}
}
然后再返回上一层聚合,再对上一层的下一个词根执行类似的聚合,最后进行排序,在第一层进行裁剪(刷选)前size个文档返回个客户端。
广度遍历优先的执行路径:
首先执行第一层聚合,也就是针对所有文档中的actors字段进行聚合,得到文档集中所有的演员,然后按doc_count排序,进行裁剪,刷选前3个演员,然后只针对这3个演员进行第二层聚合。
看上去广度遍历优先会非常高效,其实这里掩藏了一个实现细节,就是广度优先,会缓存裁剪后剩余的所有文档,也就是本例中与这3个演员的所有文档集在内存中,然后基于这些内存执行第二层聚合,故如果第一层每个桶如果包含的文档数量巨大,则会耗费很大的内存,容易触发OOM异常,故广度优先的使用场景是子聚合所需要处理的数据很少的情况下会非常高效。
参考知识:http://www.cnblogs.com/bonelee/p/7832738.html
1.9 execution hint
执行提示,类似于MySQL数据库的hint功能。
Term Aggregation聚合通常基于如下两种实现方式:
- 通过直接使用字段值来聚合每个桶的数据(map)
只有当很少的文档匹配查询时,才应该考虑映射。否则,基于序号的执行模式会快得多。默认情况下,map只在脚本上运行聚合时使用,因为它们没有序号。 - 通过使用字段的全局序号并为每个全局序号分配一个bucket (global_ordinals)
keyword类型的字段默认使用global_ordinals机制,它使用全局序号动态分配bucket,因此内存使用与属于聚合范围的文档的值的数量是线性的。
默认情况下,ES会自动选择,但也可以通过参数execution_hint进行人工干预,可选值:global_ordinals、map。
1.10 Missing value
missing定义了应该如何处理缺少值的文档。默认情况下,它们将被忽略,但也可以将它们视为具有一个值。
Terms Aggregation聚合就介绍到这里了。
2、 Significant Terms Aggregation
返回集合中出现的有趣或不寻常的项的聚合。
首先从官方示例开始学习。
官方示例的索引结构大概如下(类似一个全国犯罪事件索引库)
核心字段:
force:接案警局名称。
crime_type:犯罪类型。
2.1 Single-Set analysis
单一结果集分析,通常前台集合(foreground set)通常通过一组查询条件指定。请看示例:
GET /_search
{
"query" : { // @1
"terms" : {"force" : "上海交通警局"
},
"aggregations" : {
"significant_crime_types" : {
"significant_terms" : { "field" : "crime_type" } // @2
}
}
}
代码@1:定义一个查询,该例中查询警局为“ShangHai Transport Police”所有犯罪记录,当成我们关注(感兴趣的集合,也就是Significant Terms Aggregation中的(foreground set)。
代码@2:对crime_type犯罪类型进行significant_terms.
返回结果如下:
{
...
"aggregations" : {
"significant_crime_types" : {
"doc_count": 47347, // @1
"bg_count": 5064554, // @2
"buckets" : [ // @3
{
"key": "自行车盗窃案",
"doc_count": 3640, // @4
"score": 0.371235374214817,
"bg_count": 66799 // @5
}
,
{
"key": "小汽车盗窃案",
"doc_count": 6640,
"score": 0.371235374214815,
"bg_count": 66799
}
...
]
}
}
}
代码@1:doc_count:符合查询条件的总文档数量,此例表示上海交通警局总共的犯罪记录数。
代码@2:bg_count:这是Significant Terms中的background set,应该是该索引当前总共的文档个数。
代码@3:是significant_terms针对犯罪类型的聚合结果。
代码@4:表示上海交通警局总共发生的自行车盗窃案的总记录数。
代码@5:表示整个索引库中所有警局发生的自行车盗窃案的总记录数。
从这里的结果,我们可以得出如下结论:
整体自行车犯罪率= 66799/5064554,约等于1%。
上海交通警局自行车盗窃犯罪率(上海交通警局自行车犯罪总记录数除以上海交通警局的总犯罪记录)=3640/47347约等于7%。
使用这种查询来找出异常数据,但它只给了我们一个用于比较的子集。要发现所有其他警察部队的异常情况,我们必须对每个不同的警察部队重复查询。
如何解决该问题呢?请看下文。
2.2 Multi-set analysis
多结果集对比分析,其思路是通过term aggregation产生多个桶(多个数据集合),然后再使用子聚合针对这些分组再进行一次聚合。
跨多个类别执行分析的一种更简单的方法是使用父级聚合来分割准备分析的数据。使用父聚合进行分割的示例:
GET /_search
{
"aggregations": {
"forces": {
"terms": {"field": "force"}, // @1
"aggregations": {
"significant_crime_types": { // @2
"significant_terms": {"field": "crime_type"}
}
}
}
}
}
代码@1:首先对字段force进行term聚合,统计各个警局的犯罪记录总数。
代码@2:然后子聚合是对犯罪类型进行significant_terms聚合。
我们先来看一下返回结果:
{
...
"aggregations": {
"forces": {
"doc_count_error_upper_bound": 1375,
"sum_other_doc_count": 7879845,
"buckets": [
{
"key": "广州交通警局",
"doc_count": 894038,
"significant_crime_types": {
"doc_count": 894038, // @1
"bg_count": 5064554, // @2
"buckets": [ // @3
{
"key": "抢劫", // @4
"doc_count": 27617, // @5
"score": 0.0599,
"bg_count": 53182 // @6
}
...
}
}// 省略其他警局的数据。
]
}
}
}
主要针对significant_crime_types的结果集做一次解释:
结果@1:"广州交通警局"总处理犯案记录总数为894038。
结果@2:索引库总处理犯案记录总数为5064554。
结果@3:"广州交通警局"各个犯案类型的聚合数据。
结果@4:犯罪类型(crime_type)为“抢劫”类型的聚合数据。
结果@5:“广州交通警局” “抢劫”类案的处理条数为27617。
结果@6:索引库总处理犯罪类型为“抢劫”的总数为53182 。
2.3 Significant聚合的分数如何计算
如果术语在子集中(foreground set)出现的频率和在背景中(background sets)出现的频率有显著差异,则认为该术语是重要的。
2.4 Custom background sets
定制background sets集合。通常情况下,ES的Significant聚合使用整个索引库的内容当成background sets(背景集合),可以通过background_filter参数来指定,其使用示例如下:
2.5 Significant Terms Aggregation限制
- 聚合字段必须是索引的
- 不支持浮点类型字段聚合。
- 由于Significant Terms Aggregation聚合的background sets是整个索引文档,故如果用作foreground set的查询返回结果也是整个文档集合(match_all)的话,该聚合则失去意义。
- 如果有相当于match_all查询没有查询条件提供索引的一个子集significant_terms聚合不应该被用作最顶部的聚合——在这个场景中前景是完全一样的背景设定,所以没有文档频率的差异来的观察和合理建议。
与Terms Aggregation一样,其结果是近似值,可以通过size、shard_size来控制其精度。
另一个需要考虑的问题是,significant_terms聚合在切分级别上生成许多候选结果,只有在合并所有切分的统计信息之后,才会在reduce节点上对这些结果进行修剪。因此,就RAM而言,将大型子聚合嵌入到一个重要的_terms聚合(稍后将丢弃许多候选项)下是低效且昂贵的。在这种情况下,最好执行两个搜索——第一个搜索提供一个合理的重要术语列表,然后将这个术语短列表添加到第二个查询中,以返回并获取所需的子聚合。
Significant Terms Aggregation支持Terms Aggregation定义的参数,诸如size、sharding_size、missing、collect_mode、execution_hint、min_doc_count等参数。
欢迎加笔者微信号(dingwpmz),加群探讨,笔者优质专栏目录:
1、源码分析RocketMQ专栏(40篇+)
2、源码分析Sentinel专栏(12篇+)
3、源码分析Dubbo专栏(28篇+)
4、源码分析Mybatis专栏
5、源码分析Netty专栏(18篇+)
6、源码分析JUC专栏
7、源码分析Elasticjob专栏
8、Elasticsearch专栏(20篇+)
9、源码分析MyCat专栏