See More, Know More: Unsupervised Video Object Segmentation with Co-Attention Siamese Networks论文解读
这是我看的第一篇无监督视频目标分割的方法(UVOS),是一篇CVPR2019,之前一直看的是半监督VOS,因为思路卡壳,在无监督VOS方法中寻求一下灵感。相较于半监督已经开始在保持精度的情况重视推理速度,无监督还是看重精度,不过毕竟UVOS没有给要分割哪一个目标。
官方代码
idea
作者提出一种co-attention,基于一个视频序列全局角度,来提升UVOS的精度。(确实领先目前的很多模型,davis官网的数据)。以往的一些方法,有通过显著性检测得到所要分割的目标,或者通过有限帧之间计算出的光流信息。COSNet则从整个视频序列中考虑哪个目标是需要分割的。在测试阶段,COSNet会综合所有前面的帧得到的信息,推理出当前帧中哪个目标是显著的同时还是经常出现的。Co-attention模块挖掘了视频帧之间丰富的上下文信息。基于co-attention,作者提出了COSNet(co attention Siamese)来从一个全局视角建模UVOS 。现在可能读者还是不能理解这个全局视角是什么,在method部分会解释。
main contribution
- COSNet采用的训练方式是考虑一个pair,包含相同视频中的任意两帧,所以说极大的增加了数据量,不需要考虑时序关系,依次送入数据,而是可以打乱数据,随机组合。
- 显示建模帧和帧的联系,不依赖光流
- 统一的,端到端、可训练的高效网络
Method
这个section,将分为两个部分,一个是training stage的网络是如何工作的。另一部分是模型在test stage的行为。
training stage

overview of training model
两个帧 F a , F b F_a, F_b Fa,Fb经过backbone得到两个特征 V a , V b V_a, V_b Va,Vb,这两个特征经过Co-attention模块,得到两个新的特征 X a , X b X_a, X_b Xa,Xb,新的特征带有两帧的联系性,这两个特征用于计算loss。从结构框图中,我们可以看出,关键的地方就是在于Co-attention模块。
co-attention
作者提出三种co-attention 变体(variants) 前文提到的 V a , V b V_a, V_b Va,Vb默认被reshap为 R C × H W R^{C \times HW} RC×HW
Vanilla co-attention
记仿射矩阵S,
S = V b T W V a ∈ R W H × W H S = V_b^T W V_a \in R^{WH \times WH} S=VbTWVa∈RWH×WH
W ∈ R C × C W \in R^{C \times C} W∈RC×C是需要学习的权重矩阵,S的每一个元素代表了两个特征中的两列的相似程度(向量乘积是一个标量)。把W对角化:
W = P − 1 D P W = P^{-1}D P W=P−1DP
P是可逆矩阵,S可以写成
S = V b T P − 1 D P V a S = V_b^TP^{-1}DPV_a S=VbTP−1DPVa
Symmetric co-attention (对称)
如果W是一个对称矩阵,那么W一定可以正定对角化,
S = V b T P T D P V a S = V_b^TP^TDPV_a S=VbTPTDPVa
S = ( P V b ) T D P V a S = (PV_b)^TDPV_a S=(PVb)TDPVa$
P是正定矩阵,先将两个特征投影到正交空间中,然后在计算相似距离,这样子可以消除通道之间的联系,使得特征不是冗余的。
Channel-wise co-attention
如果P是一个单位矩阵I,那么D可以被分解为两个对角矩阵。
S = V b T I − 1 D I V a = ( D a V b ) T D b V a S = V_b^T I^{-1}DIV_a = (D_a V_b)^T D_b V_a S=VbTI−1DIVa=(DaVb)TDbVa
其中 D = D a T D b D = D_a^T D_b D=DaTDb,D_a,D_b$都是对角矩阵。那么一个对角矩阵和一个矩阵相乘,得到的结果其实是对角矩阵对角线的值乘以对应的列。可以视作增强了某一个通道。和SENet有异曲同工之效果。也是减小了冗余度。
介绍完获得S的三种方式,接下来就介绍作者的co-attention.

得到S,对应第二行中间的部分,之后就分成两条路。左边得到 S c S^c Sc,往右边走得到 S r S^r Sr。这两个S分别反映了两个特征图Va,Vb之间的联系。想想它们的计算方式。接下来计算 Z a , Z b Z_a,Z_b Za,Zb
Z a = V b S c Z_a = V_b S^c Za=VbSc
Z b = V a S r Z_b = V_aS^r Zb=VaSr
Gated co-attention
作者引入Gated(门限),给学到的Z用同样大小的map reweights,算是空间注意力吧。


之后concat 从backbone得到的特征X

得到的两个重构的X,这个X是带有帧与帧之间的联系这个信息的, 送到各自的seg Head中。

整个训练方式如上图:
- 随机从一个视频中选出两帧,经过backbone,经过co-attention,最后concat上backbone的特征,送到一个分割模块中,得到的预测结果用于计算损失函数。
- 作者提到使用在显著性数据集上预训练一个DeeplabV3,在deeplabV3后面加一个2通道的1x1的卷积作为输出。
test stage
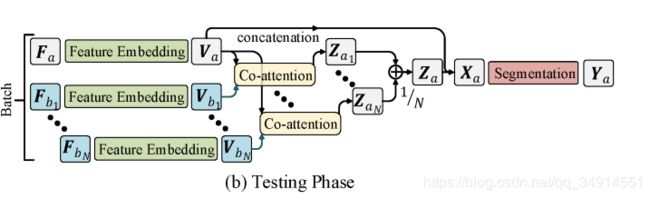
首先选出N张参考帧集合 F b = { F b 1 . . . , F b n } F_b = \left\{F_{b1}...,F_{bn}\right\} Fb={Fb1...,Fbn}
和当前帧 F a F_a Fa, F a F_a Fa和 F b F_b Fb中的所有参考帧都做成pair,得到一系列的 Z a Z_a Za,然后按照

得到 携 带 所 有 参 考 帧 和 当 前 帧 联 系 的 特 征 Z a 携带所有参考帧和当前帧联系的特征Z_a 携带所有参考帧和当前帧联系的特征Za,然后concat Va,送到分割网络中。
后处理使用了CRF