走近InnoDB内存结构
文章目录
- 摘要
- 整体结构
- 内存结构
- Buffer Pool
- LRU
- Buffer Pool List
- Buffer Pool配置
- flush
- Change Buffer
- Log Buffer
- Adaptive Hash Index
- 参考
摘要
本文基于MySQL5.7为基础,讨论InnoDB内存结构的相关内容。其中涉及到Buffer Pool、Change Buffer、Adaptive Hash Index和Log Buffer等内容。适合有一定MySQL基础的人阅读。
整体结构
我们先来看看MySQL官方给出的InnoDB的整体结构,如下图,从图中可以看出,大致可以分为左右两个部分,左边描述的是内存结构,就是本文讨论的主要内容,右边描述的是磁盘结构,会在之后的文章里讲述。
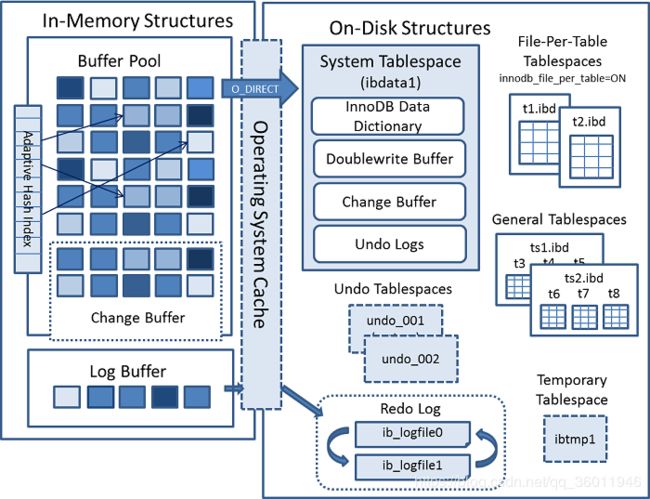
内存结构
从上图可以看出,内容结构又可以细分为三个部分,分别为Buffer Pool、Adaptive Hash Index和Log Buffer,接下来我们就来看看他们分别是什么,又有什么用呢。
Buffer Pool
Buffer Pool(缓冲池)是主内存中的一个区域,InnoDB在访问表和索引数据时将缓存在其中,来加速数据访问。大家都知道,MySQL读取数据的最小单位是Page(页),就算你一次查询的结果只有一行数据,但是MySQL会把这行数据所在的Page加载到Buffer Pool,所以Buffer Pool中的结构也是Page,每一个Page可能包含多行数据。
LRU
为了提高缓存的命中率,每一种缓存都会有适合自己的缓存淘汰算法,Buffer Pool也不例外。Buffer Pool使用的是LRU(最近最少使用)的变体,这种算法被广泛应用,例如操作系统、Redis等等。这种算法能最大化页面命中率。关于这种算法的更多信息,可自行Google。
Buffer Pool List
当需要空间将新页添加到缓冲池时,将收回最近使用最少的页,并将新页添加到列表的中间。这个中点将列表分为两个子列表:
- New Sublist:最近访问的新页子列表。
- Old Sublist:最近访问次数较少的旧页子列表。
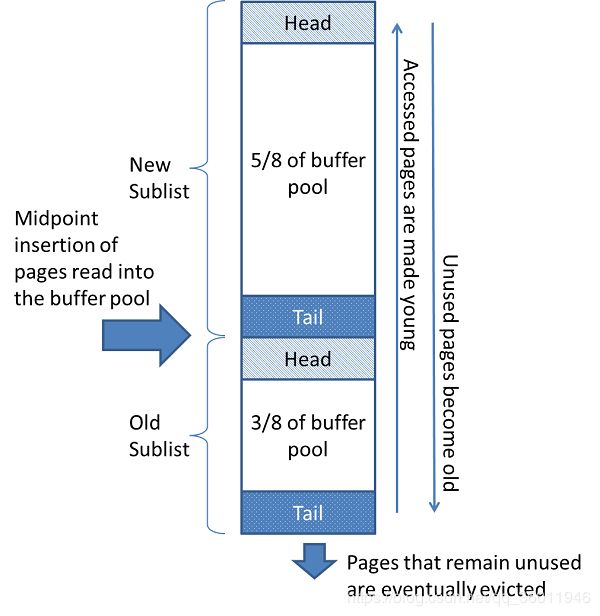
这里说一下这个变体算法的过程:
- 5/8分配给新子列表,3/8的容量分配给旧子列表。
- 列表的“中点”是新子列表的尾部与旧子列表的头部相交的边界。
- 当
InnoDB将页面读入缓冲池时,它首先将其插入中点(旧子列表的头部)。 - 访问旧子列表中的页面使其变为“ 年轻 ”,将其移至新子列表的头部(头插法)。
- 当数据库运行时,缓冲池中不被访问的页面会“老化”到列表的尾部。新的和旧的子列表中的页面随着其他页面的更新而老化。旧子列表中的页面也会随着页面插入到中点而老化。最终,一个页面到达旧子列表的尾部并被逐出。
你可能会觉得疑惑,为什么要在列表的“中点”(也就是旧子列表的头部)插入,再通过访问旧子列表使其插入列表的头部(也就是新子列表的头部),而不是直接插入列表的头部呢?这不是多此一举么?
其实并不是多次一举,你试想一下,新子列表中存放的是我们大量的热点数据,这个时候有一个大表的全表查询或者mysqldump(逻辑备份),如果是直接插入列表的头部会有什么结果,我们新子列表中的所有热点数据全部被“老化”到旧子列表中,甚至直接被淘汰,其实我们并不希望如此。因为才会选择通过再次访问旧子列表的页使其变为“年轻”。
Buffer Pool配置
你可以通过Buffer Pool的相关配置提高性能:
-
Buffer Pool分配的内存越大,查询性能越高;
-
在64位的系统上,可以配置多个Buffer Pool实例,以最大程度减少并发操作之间内存结构的竞争。
-
您可以控制何时进行flush(刷脏页),以及是否根据工作负荷动态调整刷脏页速率。
…
flush
当内存数据页跟磁盘数据页内容不一致的时候,我们称这个内存页为“脏页”。
正常运行中的实例,数据写入后的最终落盘,是从redo log更新过来的还是从buffer pool更新过来的呢?
实际上,redo log并没有记录数据页的完整数据,所以它并没有能力自己去更新磁盘数据页。
-
如果是正常运行的实例的话,数据页被修改以后,跟磁盘的数据页不一致,称为脏页。最终数据落盘,就是把内存中的数据页写盘。这个过程,甚至与redo log毫无关系。
-
在崩溃恢复场景中,InnoDB如果判断到一个数据页可能在崩溃恢复的时候丢失了更新,就会将它读到内存,然后让redo log更新内存内容。更新完成后,内存页变成脏页,就回到了第一种情况的状态。
所以说,redo log只是用来恢复内存中的数据,更新数据是从内存页更新到磁盘的。
刷脏页虽然是常态,但是出现以下这两种情况,都是会明显影响性能的:
-
查询导致buffer pool要淘汰的脏页个数太多,会导致查询的响应时间明显变长;
-
日志写满,更新全部堵住,写性能跌为0,这种情况对敏感业务来说,是不能接受的。
所以,InnoDB需要有控制脏页比例的机制,来尽量避免上面的这两种情况。
Change Buffer
Change Buffer(更改缓存区),是一种特殊的数据结构,当辅助索引页不在Buffer Pool中时,它会将 更改 缓存到辅助索引页。由插入、更新或删除操作(DML)引起的缓冲 更改 将在稍后由其他读取操作将页加载到 Buffer Pool 中时合并。
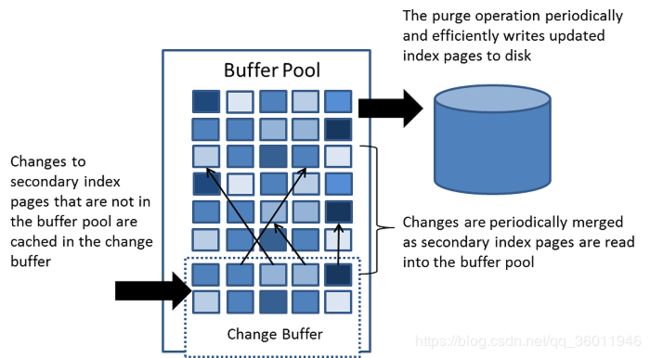
与聚集索引不同,二级索引通常是非唯一的,插入二级索引的顺序相对随机。类似地,删除和更新可能会影响索引树中不相邻的辅助索引页。当受影响的页被其他操作读取到Buffer Pool中时,合并缓存的更改可以避免从磁盘将辅助索引页读取到缓冲池中所需的大量随机I/O访问。
所以,Change Buffer中存储的是更改了的辅助索引页。
如果索引包含降序索引列或主键包含降序索引列,则不支持对辅助索引进行更改缓冲。
Log Buffer
Log Buffer(日志缓冲区),用于保存要写入磁盘上的日志文件的数据。日志缓冲区大小由innodb_Log_buffer_size变量定义。默认大小为16MB。日志缓冲区的内容定期刷新到磁盘(写入重做日志文件)。大型日志缓冲区使大型事务能够运行,而无需在事务提交之前将重做日志数据写入磁盘。因此,如果您有更新、插入或删除许多行的事务,增加日志缓冲区的大小可以节省磁盘I/O。
该 innodb_flush_log_at_trx_commit 变量控制如何将日志缓冲区的内容写入并刷新到磁盘。该 innodb_flush_log_at_timeout 变量控制日志刷新频率。
Adaptive Hash Index
Adaptive Hash Index(自适应哈希索引),使InnoDB 可以在不牺牲事务功能或可靠性的情况下,在工作负载和缓冲池有足够内存的适当组合的系统上执行更像是内存数据库。
使用索引关键字的前缀构建哈希索引。前缀可以是任意长度,并且可能只有B树中的某些值出现在哈希索引中。哈希索引是根据需要为经常访问的索引页构建的。
就像上面整体结构图中描述的一样,自适应哈希索引可以加快对Buffer Pool中索引页的访问。
参考
[1] MySQL 5.7 Reference Manual.
[2] MySQL实战45讲.