Spark学习—— (3) 运行模式Local,Standalone,YARN
Spark有多种运行模式,包括——
- local模式,本地运行
- Standalone模式,使用Spark原生的资源调度器
- YARN模式(生产模式中常用),使用Hadoop的YARN作为资源调度器
- Mesos模式,使用Mesos作为资源调度器
本文主要介绍前面三种最常用的运行模式,其中每种模式又可细分为两种模式。在搭建好集群的基础上,使用各个模式分别运行,描述其运行过程。
关于集群搭建,可以参考上一篇笔记。
若有错误的地方,请大佬指正。
文章目录
- 1. 配置Spark历史服务器
- 1.1 配置
- 1.2 启动历史服务器
- 2. local模式
- 2.1 local[N]概念
- 2.2 local[N]运行过程
- 2.3 local-cluster概念
- 2.4 local-cluster运行过程
- 3. Standalone模式
- 3.1 概念定义
- 3.2 Client模式运行过程
- 3.3 Cluster模式运行过程
- 4. YARN模式
- 4.1 概念定义
- 4.2 Client模式运行过程
- 4.3 Cluster模式运行过程
- Reference
1. 配置Spark历史服务器
在运行Spark程序过程中,可以通过http://driver:4040访问web UI,查看运行情况。但是运行结束后,就无法再查看。为了后面查看Spark任务的方便,这里先配置下Spark历史服务器。
1.1 配置
- 查看之前配置HDFS时设置的文件系统的位置,在
hadoop/etc/hadoop/core-site.xml文件中,如下,之前设置端口号为9000
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://master:9000value>
property>
...
configuration>
- 修改
spark/conf/spark-defaults.conf,目录下有对应的template文件,复制一下就好,在后面增加内容如下:
spark.eventLog.enabled true
spark.eventLog.dir hdfs://master:9000/spark/history
- 修改
spark/conf/spark-env.sh,目录下有对应的template文件,复制一下就好,在后面增加内容如下:
#历史服务器
export SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory = hdfs://master:9000/spark/history -Dspark.history.ui.port=18080"
- 把文件发送到另外两个slave节点(不发也可以)
scp -r /opt/spark/conf Node@slave1:/opt/spark
scp -r /opt/spark/conf Node@slave2:/opt/spark
1.2 启动历史服务器
- 启动HDFS,启动相应的namenode和datanode
/opt/hadoop/sbin/start-dfs.sh
- 创建上述目录
hdfs dfs -mkdir /spark
hdfs dfs -mkdir /spark/history
- 启动
spark/sbin/start-history-server.sh
sbin/start-history-server.sh
- 验证是否启动成功,如下,看到HistoryServer,且Web UI可正常访问
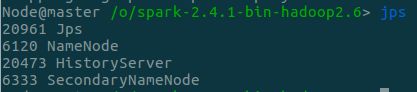 |
 |
2. local模式
local模式包括 local[N] 模式和 local-cluster 模式,都是在单机上运行。
2.1 local[N]概念
本地运行模式,用单机的多个线程(单个进程,区分local-cluster模式)来模拟Spark的分布式计算,通常用于验证程序的逻辑是否有问题。
local[N]的N表示使用N个线程,每个线程有一个core。
若不指定,则N=1;若为*,则N等于机器上拥有的逻辑核的数量。(Run Spark locally with as many worker threads as logical cores on your machine.)
2.2 local[N]运行过程
使用local[N]模式运行时,无需启动Master、Worker守护进程(Standalone模式才需要)。
(这里使用ubuntu默认的python2.7我运行不了,参考Reference.6切换成3.5就可以了)
- 使用如下命令运行,在spark目录下,运行example程序,计算pi值,指定使用4个线程
spark-submit --master local[4] examples/src/main/python/pi.py 1000
- 查看运行时的进程,可以看到除了历史服务器相关的进程,只有一个SparkSubmit进程
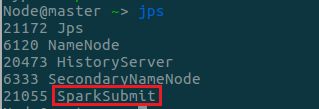
- 在历史服务器查看应用运行情况如下,可以看到按照设定的使用了4个线程
- 整体运行过程大致如下(按照Spark的运行流程来看):
- SparkSubmit充当client角色,提交Spark应用
- SparkSubmit运行Driver程序,启动SparkContext
- SparkSubmit创建一个Eexcutor,创建线程池,大小为4(个人理解为:SparkSubmit本身也是资源管理器,分配给自身)
- Driver创建tasks,然后将这些tasks分配到Executor中执行
2.3 local-cluster概念
本地运行模式,与local[N]的区别在于local-cluster模式使用单机下的多个进程来更大程度地模拟集群的分布式场景,一般也是用于验证程序的逻辑是否有问题。
提交程序需要提供local-cluster[x,y,z]参数,x表示生成的executor数目,y表示每个executor拥有的core数/线程数,z表示每个executor的memory大小。
2.4 local-cluster运行过程
- 使用如下命令运行计算pi值的程序,指定使用2个executor,每个有4个core,memory为1024M
spark-submit --master local-cluster[2,4,1024] examples/src/main/python/pi.py 1000
-
查看运行时的进程,可以看到有一个SparkSubmit进程和两个CoarseGrainedExecutorBackend进程
关于CoarseGrainedExecutorBackend进程,可以参考Reference.3
CoarseGrainedExecutorBackend 是 Executor 运行所在的进程名称,Executor 才是真正处理 Task 的对象,Executor 内部是通过线程池的方式来完成 Task 的计算的。
CoarseGrainedExecutorBackend 是一个消息通信体(其实现了 ThreadSafeRpcEndPoint) ,可以发送信息给 Driver 并可以接受 Driver 中发过来的指令,例如启动 Task 等。

- 在历史服务器查看运行情况如下,可以看到driver和Executor不在同一个进程里,每个Executor有4个核

- 整体运行过程大致如下(按照Spark的运行流程来看):
-
SparkSubmit充当client角色,提交Spark应用
-
SparkSubmit运行Driver程序,启动SparkContext,获取Executor的信息
-
本地启动CoarseGrainedExecutorBackend进程,向Driver进程进行Executor的注册,注册成功后在CoarseGrainedExecutorBackend中创建Executor对象
-
Driver创建tasks,然后将这些tasks发送给 CoarseGrainedExecutorBackend,ExecutorBackend通过调用LaunchTask将任务交给Executors中执行
(此处粗体只是简单地描述了Executor的运行过程,更详细的运行过程可以参考Reference.3)
3. Standalone模式
3.1 概念定义
Standalone模式是指使用Spark原生的资源管理器的集群运行模式。
在Standalone模式下,需要使用Master和Worker节点,其中,Master节点负责资源的调度,即为Cluster Manager,负责控制、管理、监控集群中的worker节点。
Standalone模式分为Client模式和Cluster模式,区别在于——
- Client模式下,Client提交应用后,Driver程序在Client上运行
- Cluster模式下,Client提交应用后,Client通知Master,Master随机选择一个满足Driver资源需求的Worker,在该Worker节点上运行Driver
Client模式适用于测试阶段,不能应用到生产环境中,因此假设提交client提交多个application到集群,则client节点上将会运行多个Driver程序,负载过大。
3.2 Client模式运行过程
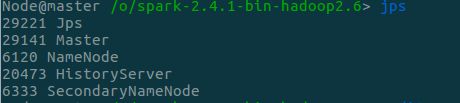
- 使用
start-all.sh启动集群(此处在spark-env.sh中设置SPARK_WORKER_INSTANCES=2),所以每个slave有两个Worker进程,如下:
 |
 |
- 使用如下命令提交任务,指定master节点和class参数
spark-submit --master spark://master:7077 --class org.apache.spark.examples.SparkPi examples/jars/spark-examples_2.11-2.4.1.jar 1000
- 查看各进程如下和历史服务器如下:
 |
 |

- Client模式下运行过程如下:
- Client提交Application,并在客户端启动Driver
- Driver启动SparkContext,与Master通信,通知该Application需要在哪些Worker启动Executor
- Master与对应的Worker通信发送启动Executor的消息
- 本地启动CoarseGrainedExecutorBackend进程,向Driver进程进行Executor的注册,注册成功后在CoarseGrainedExecutorBackend中创建Executor对象
- Driver创建tasks,然后将这些tasks发送给 CoarseGrainedExecutorBackend,ExecutorBackend通过调用LaunchTask将任务交给Executors中执行
3.3 Cluster模式运行过程
- 使用如下命令提交任务,指定master节点、class参数、
deploy-mode
spark-submit --master spark://master:7077 --deploy-mode cluster --class org.apache.spark.examples.SparkPi examples/jars/spark-examples_2.11-2.4.1.jar 1000
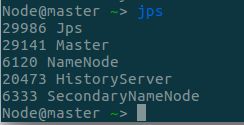
- 查看各进程如下和历史服务器如下,注意到——
- slave2有DriverWrapper进程,即Driver在slave2上运行
- slave2其中一个Worker的core数少了一个,用于运行Driver
 |
 |
 |

- Cluster模式下运行过程如下(与Client模式只有第一步有区别):
- Client提交Application,Client通知Master,Master随机选择一个满足Driver资源需求的Worker,在上面生成一个子进程DriverWrapper来启动driver程序
- Driver启动SparkContext,与Master通信,通知该Application需要在哪些Worker启动Executor
- Master与对应的Worker通信发送启动Executor的消息
- 本地启动CoarseGrainedExecutorBackend进程,向Driver进程进行Executor的注册,注册成功后在CoarseGrainedExecutorBackend中创建Executor对象
- Driver创建tasks,然后将这些tasks发送给 CoarseGrainedExecutorBackend,ExecutorBackend通过调用LaunchTask将任务交给Executors中执行
4. YARN模式
4.1 概念定义
YARN模式是指使用Hadoop的YARN作为资源管理器的集群运行模式。
在YARN模式下,不需要使用Master和Worker节点,而是使用YARN下的RM节点与NM节点,对应Standalone模式下的Master节点和Worker节点。
YARN的运行流程如下(来自之前的笔记,可以先看一下),Spark的YARN模式流程基本相同。

YARN模式同样分为两种,区别在于——
- Client模式下,Client提交应用后,Driver程序在Client上运行
- Cluster模式下,Client提交应用后,Client通知ResourceManager,Resource Manager在集群中的某个NodeManager上运行ApplicationMaster,该AM同时会执行driver程序
4.2 Client模式运行过程
- 使用
start-yarn.sh启动yarn集群,如下:
 |
 |
- 使用如下命令提交应用,指定master为YARN
spark-submit --master yarn --class org.apache.spark.examples.SparkPi examples/jars/spark-examples_2.11-2.4.1.jar 1000
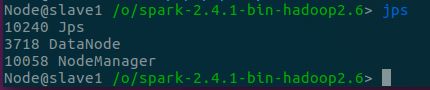
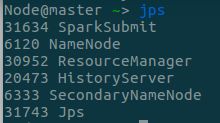
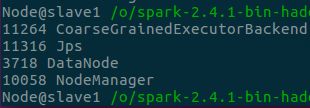
- 查看各节点进程与历史服务器,可以看到——
- Client节点有
SparkSubmit进程,执行Driver程序 - slave2节点有
ExecutorLauncher进程,启动AM - 两个NM节点上都有
CoarseGrainedExecutorBackend来并发执行程序
- Client节点有
 |
 |
 |

- 运行过程如下(前两步相当于YARN中的”用户提交应用“,接下来为YARN的工作流程,而最后两步与Standalone相同,也就是AM分配作业的功能由Driver执行了):
- Client模式下,Client提交应用后,Driver程序在Client上运行
- Driver程序向Resource Manager发送请求,启动ApplicationMaster
- ResourceManager的ASM为该应用程序分配第一个Container,并与对应的NodeManager通信,在Container上启动ApplicationMaster
- ApplicationMaster首先向ResourceManager注册,这样用户可以直接通过ResourceManager查看应用程序的运行状态
- ApplicationMaster采用轮询的方式通过RPC协议向ResourceManager申请资源
- 一旦ApplicationMaster申请到资源,则与对应的NodeManager通信,要求其启动任务
- NodeManager获得container资源后,启动CoarseGrainedExecutorBackend进程,向Driver进程进行Executor的注册,注册成功后在CoarseGrainedExecutorBackend中创建Executor对象
- Driver创建tasks,然后将这些tasks发送给 CoarseGrainedExecutorBackend,ExecutorBackend通过调用LaunchTask将任务交给Executors中执行
4.3 Cluster模式运行过程
- 使用如下命令提交应用,指定master为YARN,deploy-mode为cluster
spark-submit --master yarn --deploy-mode cluster --class org.apache.spark.examples.SparkPi examples/jars/spark-examples_2.11-2.4.1.jar 1000
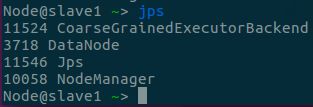
- 查看各节点进程与历史服务器,可以看到——
- Client节点有
SparkSubmit进程 - slave2节点有
ApplicationMaster进程,启动Driver,历史服务器也能看到driver在slave2上 - 两个NM节点上都有
CoarseGrainedExecutorBackend来并发执行程序
- Client节点有
 |
 |
 |

- 运行过程如下(与Client模式的区别在于Driver不在Client上执行,而在AM节点上执行,相当于AM除了申请资源、要求NodeManager启动任务外,还具有任务调度能力):
- Client提交应用后,向ResourceManager请求启动ApplicationMaster
- ResourceManager的ASM为该应用程序分配第一个Container,并与对应的NodeManager通信,在Container上启动ApplicationMaster,该节点同时执行Driver程序
- ApplicationMaster首先向ResourceManager注册,这样用户可以直接通过ResourceManager查看应用程序的运行状态
- ApplicationMaster采用轮询的方式通过RPC协议向ResourceManager申请资源
- 一旦ApplicationMaster申请到资源,则与对应的NodeManager通信,要求其启动任务
- NodeManager获得container资源后,启动CoarseGrainedExecutorBackend进程,向AM节点的Driver进程进行Executor的注册,注册成功后在CoarseGrainedExecutorBackend中创建Executor对象
- Driver创建tasks,然后将这些tasks发送给 CoarseGrainedExecutorBackend,ExecutorBackend通过调用LaunchTask将任务交给Executors中执行
Reference
-
spark学习(基础篇)–(第三节)Spark几种运行模式
-
Spark多种运行模式
-
Spark内核 第33课:Spark Executor内幕彻底解密:Executor工作原理图、ExecutorBackend注册源码解密、Executor实例化内幕、Executor具体工作内幕
-
spark 从spark-submit开始解析整个任务调度流程
-
Spark中Standalone的两种提交模式(Standalone-client模式与Standalone-cluster模式)
-
ubuntu下切换默认的python版本
-
Hadoop学习——(1) 基础知识
-
【Spark篇】—Spark中yarn模式两种提交任务方式