mysql优化 个人笔记 (explain 执行计划) 非礼勿扰 -m09
执行计划
使用explain+sql模拟优化器执行SQL查询语句
官网地址
-- 2中方式
explain select * from test;
explain extended select * from test;

id
select 查询的序列号 表示查询中执行select字句或者操作表的顺序
1. id大的select先执行
2. 如果id大小相同 那就从上到下 依次执行
select_type
-
SIMPLE 最简单的查询 1.没有union 2.没有子查询
DROP TABLE IF EXISTS `user`; CREATE TABLE `user` ( `ID` int(11) NOT NULL, `U_NAME` varchar(255) DEFAULT NULL, `AGE` int(11) DEFAULT NULL, `ADDRESS` varchar(255) DEFAULT NULL, PRIMARY KEY (`ID`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; -- 给表搞点儿数据 INSERT INTO `user` VALUES ('322', 'test', '12', '北京'); ... ... 我插入了500多条 .. -- 执行 explain select * from user; -
PRIMARY 查询中如果包含了任何复杂的子查询(union也算),最外层查询就叫Primary
explain select * from user where age = (select max(age) from user) -- 第一个select(外层查询)就被称之为 PRIMARY -
UNION 若第二个select出现在union之后 则被标记位union
explain select u_name from user union select u_name from user -- 第二个select(union后的select)就会被标记位union -
DEPENDENT UNION 第一要是union 第二内部union结果依赖外部查询条件
DROP TABLE IF EXISTS `user_2`; CREATE TABLE `user_2` ( `ID` int(11) NOT NULL, `U_NAME` varchar(255) DEFAULT NULL, `AGE` int(11) DEFAULT NULL, `ADDRESS` varchar(255) DEFAULT NULL, PRIMARY KEY (`ID`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; DROP TABLE IF EXISTS `user_3`; CREATE TABLE `user_3` ( `ID` int(11) NOT NULL, `U_NAME` varchar(255) DEFAULT NULL, `AGE` int(11) DEFAULT NULL, `ADDRESS` varchar(255) DEFAULT NULL, PRIMARY KEY (`ID`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; -- user_2 user_3 搞点儿数据 直接把user表数据搞过去也行 explain select * from user a where a.age in( select age from user_2 union select age from user_3 )看似… 内部union结果没有依赖外部的条件
但是…上边语句会被优化select * from user a where EXISTS (select age from user_2 where user_2.age =a.age union select age from user_3 where user_3.age = a.age )
-
UNION RESULT
UNION的结果 就是结果 直接查询到结果了 不需要编号id=NULLexplain select * from user union select * from user_2 -- 一个 PRIMARY 一个UNION 一个UNION RESULT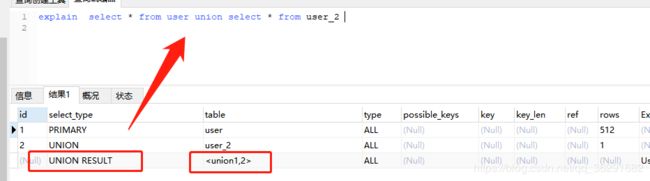
-
SUBQUERY
select或者where列表中包含子查询EXPLAIN SELECT AGE FROM test WHERE AGE > (select age from test);
-
DEPENDENCY SUBQUERY
第一是一个SUBQUERY
第二子查询的结果要受外部的影响
例子中子查询结果受外层a.age影响explain select * from user a where a.age not in (select age from user_2 b where b.age > a.age )
-
DERIVED
派生表
explain select *from (select * from user where age>10) a

- UNCACHEABLE SUBQUERY
不缓存的子查询 子查询用了一个随机函数explain select * from user where age > (select max(age) from user_2 where age >rand() )
- UNCACHEABLE UNION
不能缓存的 union模拟不出来
小知识点
select @@autocommit;
select @@sort_buffer_size;
查询当前系统参数内容
table
对应正在访问哪一个表 ,表名 或者 别名 或者是Union
- 具体表名 别名 直接去物理表中获取数据
- 表名是derivedX 的形式 表示使用了id为X的查询产生的衍生表
- 当Union result的时候,表名是union n1,n2等形式,n1,n2表示参与union的id
apache calcite 解析sql的 开源框架 地址
partitions
分区
type
type显示的是访问类型,访问类型表示是以什么样的方式访问数据
有什么疑问 看官网
https://dev.mysql.com/doc/refman/8.0/en/explain-output.html
最容易想到的是 全表扫描 (直接遍历整个表)
效率最好到最坏:
system->const->eq_ref->ref->fulltext->ref_or_null
->index_merge->unique_subquery->index_subquery
->range->ALL
一般情况下 要保证至少达到range级别 最好能达到ref级别
-- ALL 全表扫描 需要优化
explain select * from user;
-- index
1. 查询覆盖索引,既我们需要的数据 在索引中可以获取
explain select id(主键) from user;
2. 使用了索引进行排序 这样就能避免数据的重排序
explain select * from user order by id(索引列) 快
explain select * from user order by age(非索引列) 慢
-- range
表示利用索引查找时 限制了范围 避免了index全表扫描
适合的操作:
-- <>,>,>=,<,<=,IS NULL,BETWEEN ,LIKE ,IN,NOT IN
-- 给用户表的age 加一个索引
ALTER TABLE `user`
ADD INDEX `idx_age` (`AGE`) USING BTREE ;
explain SELECT * FROM user WHERE age > 18
-- index_subquery 模拟不出来
利用索引来关联子查询 不再全表扫描 aa是 t2表的索引列
有时候会被优化为exists 效果不一定能出来
explain select * from user where `user`.age in (select age from user_2);
-- unique_subquery 与 index_subquery 类似 使用的是唯一索引 模拟不出来
explain select * from user where `user`.id in (select id from user_2);
-- index_merge
将2个条件的结果合并
-- 前提条件是 age=18就几条 不能太多 太多就变成全表扫描了
explain SELECT * FROM user
WHERE id(主键) = 10 or age(索引)=18
-- ref_not_null
对于某个条件 需要关联条件,也需要null值的情况下,查询优化器会选择这种方式访问
-- 先把user表的age字段搞几个位null的
explain select * from user where age=18 or age is null
-- ref
使用了非唯一性索引进行查找
explain select * from user where age(普通索引) = 19
-- eq_ref
使用唯一性索引进行查找
explain select `user`.id from user where `user`.id=31
这个是唯一性索引 查询出来就一条值 所以他就变成了const 不是eq_ref
所以这样:
explain select `user`.id from user ,user_2 where `user`.id = user_2.id
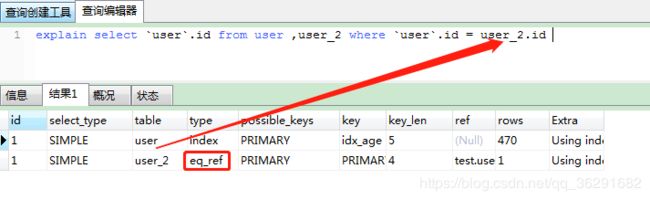
-- const
这个表至多有一个匹配
select * from user where id(主键) = 100
-- system
表只有一行记录 (等于系统表) 是const类型的特例 平时不会出现
--
--
possible_keys
- 显示可能应用在这张表中的索引,一个或多个
- 查询涉及到的字段上若存在索引,则该索引将会被列出
- 但不一定被使用
key
- 实际使用的索引,如果为null 则没有被使用的索引
- 查询中若使用了覆盖索引,则该索引和查询的select字段重叠
key_len
- 表示索引中使用的字节
- 可以通过key_len计算查询中使用的索引长度,不损失精度的情况下长度越短越好
ref
- 显示索引的那一列被使用了
- 如果可能的话 是一个常数const (索引列给定的是一个常数值 id=100)
rows
- 大致估算出 找到记录所要读取的行数
- 直接反应sql找了多少数据 ,当然是越少越好
extra
包含额外信息
- using filesort
说明mysql无法使用索引进行排序 只能利用排序算法进行排序,消耗了额外的资源 - using temporary
建立临时表 存放中间结果 , 查询完成后删除临时表 - using index
表示当前的查询是覆盖索引的,直接从索引中读取数据,而不用访问数据表
如果同时出现using where 说明索引被用来执行索引键值的查找,如果没有说明索引是用来读取数据 ,并没有真的查找 - using where
使用where进行数据过滤 - using join buffer
是否使用了连接缓存 - impossible where
where 语句结果 总是false
有几个模拟不出来的 很遗憾 有人给一个例子就好了.