mysql优化 个人笔记 (mysql锁机制 ) 非礼勿扰 -m10
锁机制
A : undolog 实现
C :
I :锁实现
D :redolog实现
1. mysql锁基本介绍
锁是计算机协调多个进程或线程并发访问某一资源的机制
在数据库中 除了传统的计算机资源(CPU RAM I/O等)的的争用外,
数据也是一种共享资源,如何保证数据访问的一致性,有效性?
是所有数据库必须要解决的问题。
锁冲突也是影响数据库访问的一个重要因素。
从这个角度看,锁机制很重要。
相对其他数据库而言,mysql的锁机制比较简单,不同的存储引擎支持不同的锁机制,
MyISAM 和 memory 存储引擎采用的表级锁(table-level locking)
Innodb 存储引擎支持行级别锁(row-level locking)也支持表级锁哦
表级锁:
1. 开销小,加锁快,不会死锁,
2. 锁粒度大,发生冲突概率高,并发度低
行级锁:
1. 开销大 加锁慢 锁定力度小 发生冲突概率低 并发高
2. 会出现死锁
从上述特点可见,很难笼统的说那种锁更好,只能具体场景具体分析
从锁的角度来说:
1 . 表级锁更适合查询 ,只有少量按索引条件更新数据的应用 web应用
2 . 行级锁,适合有大量按索引条件并发更新不同数据,同时又有并发查询的应用
OLTP系统
OLTP : Online Transaction Processing 在线事物处理 (增删改的多)
OLAP:Online Analytical Processing 在线分析处理 历史数据的分析( 查询 )
2.MyISAM
串行:
mysql 的表级锁有两种模式: 表共享读锁(Table Read Lock) 和 表独占写锁(Table Write Lock)
- 对于MyISAM表的读操作,不会阻塞其他用户对同一表的读请求,但会阻塞对同一表的写请求
- 对于MyISAM表的写操作,会同时阻止其他用户对同一个表的读和写
- 读 写 串 行 !
-- 创建表
CREATE TABLE `test` (
`id` bigint NOT NULL ,
`name` varchar(255) NULL ,
PRIMARY KEY (`id`)
) engine =MyISAM DEFAULT CHARSET=UTF8;
CREATE TABLE `person` (
`id` bigint NOT NULL ,
`age` int NULL ,
PRIMARY KEY (`id`)
) engine =MyISAM DEFAULT CHARSET=UTF8;
--
造数据
INSERT INTO `test`.`test` (`id`, `name`) VALUES ('1', 'a');
INSERT INTO `test`.`test` (`id`, `name`) VALUES ('2', 'b');
INSERT INTO `test`.`test` (`id`, `name`) VALUES ('3', 'c');
INSERT INTO `test`.`test` (`id`, `name`) VALUES ('4', 'd');
Mysql安装目录下 喽一眼 是MyISAN存储引擎的格式
1. 打开2个客户端窗口 (我用的开俩navicate )
2. 演示一个 写锁阻塞读的案例
当一个线程获取一个表的写锁之后,只有持有这个锁的线程可以对表进行更新操作,其他线程的操作会等待 直到获取锁的线程释放锁
以下称Navicat第一个窗口为N1 Navicat第二个窗口为N2
1. N1: lock table test write;
2. N2:select * from test; -- 卡住了 等锁呢
3. N1:select * from test; -- 能查询
4.N1:insert into test values(5,'e'); -- 能插入数据
update test set name = 'ee' where id = 5; -- 能更新数据
5.N2 还卡着呢(可能会超时)
6. N1:unlock tables;
7. N2:不卡了 有执行结果了(结果里有ee了)

-- 读阻塞写的案例 还是N1 和 N2
1. N1 : lock table test read;
2. N1:select * from test; -- 有数据
3. N2:select * from test; -- 有数据
4. N1:select * from person ; -- N1不能查询其他表
5. N2:select * from person ; -- N2 可以查询其他表
6. N1:insert into test values(5,'e'); --N1不能插入 报错
-- Table 'test' was locked with a READ lock and can't be updated
7. N2:insert into test values(6,'f'); -- N2插入不报错,但是会卡住 阻塞
8. N1:update test set name = 'qqq' where id = 5; -- N1 更新也会报错
-- 1099 - Table 'test' was locked with a READ lock and can't be updated
9. N1: unlock tables; -- 释放锁
10.N2 : 刚才的更新成功
总结: 也就是N1获取一个表的锁之后 不能操作其他表 不能对本表新增(报错)+修改(报错)
N1获取一个表的锁后,N2可以操作其他表,不能对N1获取锁的表进行修改(等待)
注意:
MyISAM 在执行查询语句之前,会自动给涉及的表加读锁,在执行更新操作前,会自动给涉及的表加写锁,这个过程不需要用户干预,因此用户一般不需要使用命令来显示的加锁,一般只有自己在测试这个过程加锁过程的时候,才会手动加锁,来模拟各种场景
并行:
MyISAM 表的读和写是串行的,这是就总体而言的,
在一定条件下MyISAM也支持查询和插入操作的并发执行!
MyISAM存储引擎有一个系统变量concurrent_insert 专门用来控制并发行为,
值分别是 0(NEVER) 1(AUTO) 2(ALWAYS )
- 当值为0(NEVER) 时 不允许并发插入
- 当值为1(AUTO)时,如果表中没有被删除的行(空洞),允许一个进程读的同时,另一个进程写操作
- 当值为2(ALWAYS) 无论表中有没有空洞,都允许表尾并发插入记录
实验:
show VARIABLES like '%concurrent_insert%'
-- 显示AUTO 也就是1
-- 还用上边的N1 N2
N1:lock table test read local;
N1:SELECT * FROM test; -- 可以查询结果
N1:INSERT INTO TEST VALUES(7,'G');
-- 失败 Table 'TEST' was locked with a READ lock and can't be updated
N2:INSERT INTO TEST VALUES(7,'G'); -- 成功
N1:SELECT * FROM test; -- 可以查询结果 但没有 7,G 这条记录
N2:SELECT * FROM test; -- 可以查询结果 有新增的7,G 这条记录
N2:UPDATE TEST SET NAME='CC' WHERE ID=3; -- 阻塞
N1:UNLOCK tables; --解锁
N2:上一步update成功
N1:SELECT * FROM test; -- N2的新增 和 update 的行 都可以看到
--说明 在N1 lock read locl 的时候 N1 可以查询 插入 但是不能更新 删除
可以通过检查table_locks_waited 和 table_locks_immidiate 的状态变量来分析系统上的表锁争夺:
show status like '%table_locks%'
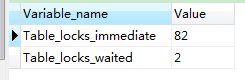
– 如果table_locks_waited 的值比较大,则说明存在严重的表锁争用情况
3.InnoDB
1、事物及其ACID属性
事物是由一组SQL语句组成的逻辑处理单元,事物具有4个属性,通常称之为ACID
- 原子性(Actomicity):事物的原子性,对数据的修改,要么全成功 ,要么全失败 (undolog)
- 一致性(Consistent):在事物开始和完成时,数据都必须保持一致状态(最终结果)
- 隔离性(Isolation):数据库系统提供一定的隔离机制,保证事物在不受外部并发操作影响的“独立”环境执行(锁)
- 持久性(Durable):事物完成之后,它对于数据的修改是永久的,即使出现系统故障也能够保持(redolog )
2、并发事物带来的问题
相对于串行来说呢,并发事物处理能力大大增加了数据库资源的利用率,提高数据库系统的事物吞吐量,从而可以支持更多用户的并发操作,但与此同时,会带来一些问题
- 脏读:
记录yy=1 A事务修改yy=2 未提交 , B事物读取yy=2 ,A事务回滚 yy=1 ,这时B事务读取的数据 就是脏数据
示例:
1. 创建表
DROP TABLE IF EXISTS `test_innodb`;
CREATE TABLE `test_innodb` (
`id` bigint(20) NOT NULL,
`name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
2. 插入数据
insert into test_innodb values (1,'小智障');
3. 开启两个navicat窗口 与上边示例一样 N1 和 N2
4. N1 设置事务级别
set session transaction isolation level read uncommitted;
SELECT @@tx_isolation; -- READ-UNCOMMITTED
5. N2设置事务级别
set session transaction isolation level read uncommitted;
SELECT @@tx_isolation; -- READ-UNCOMMITTED
6. N1 开启事务 更新数据 但不提交
-- 开启事务
start TRANSACTION;
-- 更新数据
update test_innodb set name = '小可爱' where id=1;
7. N2 开启事务 查询数据 拿着结果去做了一些其他业务
-- 开启事务
start TRANSACTION;
-- 读取数据
select name from test_innodb where id=1; -- 小可爱
if (name == "小可爱") {
sout("请她吃根雪糕");
}
8. N2 提交
commit;
9. N1 回滚
ROLLBACK;
10. N1 查询
select name from test_innodb where id=1; -- 小智障
11. 结果就是N2拿着自以为对的N1得事务过程中的数据 来进行了自己的业务操作
结果N1 事务没有成功 而是回滚了 出现了N2 读取前 后 数据不一致
- 不可重复读:
事务A 读取一条记录yy=1 , 事务B 修改yy=2 提交,
事务A 又读取一次yy=2 事务A两次读取的结果不一致
示例:
-- 接着上边示例的表结构来
1. N1 开启事务 读取数据
-- 开启事务
start TRANSACTION;
-- 读取数据
select name from test_innodb where id=1;
-- 结果是 name=小智障
2. N2 开启事务 修改数据 提交事务
-- 开启事务
start TRANSACTION;
-- 更新数据
update test_innodb set name = '小可爱' where id=1;
-- 提交事务
commit ;
3. N1 又一次读取数据
select name from test_innodb where id=1;
-- 结果是 name=小可爱
4. N1 两次读取数据不一致 这就是不可重复读
5. N1 提交事务 commit;
- 幻读:
事务A 查询范围r的数据 结果为10条
事务B 在这个范围R内加了几条数据 提交
事务A 又一次读取这个范围R内的数据 结果不是10
两次读取的记录数不一致,这就是幻读
示例:
-- 接着上边表结构
1. N1 开启事务 查询数据
-- 开启事务
start TRANSACTION;
-- 查询数据
select * from test_innodb where name like '%小%'
-- 只有一条数据
2. N2 开启事务 新增数据 提交事务
-- 开启事务
start TRANSACTION;
-- 新增数据
insert into test_innodb values (1,'小智障');
insert into test_innodb values (1,'小傻瓜');
insert into test_innodb values (1,'小小鸟');
-- 提交事务
commit;
3. N1 查询数据
-- 查询数据
select * from test_innodb where name like '%小%'
-- 有4条数据 出现幻读 跟幻觉一样 刚刚是1 现在是4
| 脏读 | 不可重复读 | 幻读 | |
|---|---|---|---|
| read uncommitted 读取未提交内容 | √ | √ | √ |
| read committed 读提交内容 | √ | √ | |
| repeatable read可重复读 | √ | ||
| serializable 可串行化 |
Mysql Innodb默认是 repeatable read
- read uncommitted 读取未提交内容
所有事务都可以看到其他事务未提交的执行结果 - read committed 读提交内容
一个事务只能看到已提交的事务的执行结果 - repeatable read可重复读
Mysql默认事务隔离级别,事务A读取一条数据后,事务B对这条数据进行了修改,并提交,事务A再次读取这条数据还是原来的内容(解决了不可重复读) - serializable 可串行化
事务 串行执行
可以通过检查Innodb_row_lock状态变量来分析系统上的行锁的争夺情况
show status like 'innodb_row_lock%';
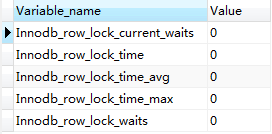
如果Innodb_row_lock_waits 和 Innodb_row_lock_time_avg 的值比较大就是锁争用比较严重
3、InnoDB的行锁模式 及 加锁方式
共享锁(s):
又叫读锁
允许一个事务去读一行,阻止其他事务获取相同数据集的排它锁,
若事务T1对数据对象O上加了S锁,则事务T1可以读取O,但是不能修改O
其他事务只能对O加S锁,不能加排它锁 ,这保证了其他事务可以读O 但是不能修改O
排它锁(x):
又叫写锁
允许获取排它锁的事务更新数据,阻止其他事务获取相同数据对象的排它锁和共享锁,
若事务T1 对对象O 加上排它锁,则事务T1可以读取对象&修改对象,其他事务不能对O 加任何锁
Mysql的InnoDB引擎默认的修改数据语句:
update delete insert 都会自动给涉及到的数据加上排它锁
select语句不会加任何类型的锁,
如果select加排它锁可以用select * from table_name for update
如果select加共享锁 可以用 select * from table_name lock in share mode
所以:加了排它锁的数据行,在其他事务是不能修改数据的,也不能通过for update和 lock in share mode 锁的方式查询数据
,但是可以直接通过select * from table_name 查询数据,因为普通的sleect没有任何锁限制
Innodb行锁是通过给索引 上的索引项来实现的,
这点mysql与oracle不同,oracle是通过数据块中对应数据行加锁来实现的。
innodb这种行锁实现特点意味着:只有通过索引条件检索数据,innodb才会使用行级锁,否则,innodb将使用表锁
- 不用索引条件查询时 innodb使用的是表锁 不是行锁
DROP TABLE IF EXISTS `test_no_index`;
CREATE TABLE `test_no_index` (
`id` bigint(20) NOT NULL,
`name` varchar(255) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
插入数据:
insert into test_no_index
values (1,'a'),(2,'b'),(3,'c')
还是老朋友 用N1 N2
1. N1 set @@autocommit=0;
2. N2 set @@autocommit=0;
3. N1 select * from test_no_index where id=1 for update
4. N2 select * from test_no_index where id=2 for update -- 阻塞了
5. N1 commit;
6. N2 不阻塞了 查询出结果了
7. N1 select * from test_no_index where id=1 for update -- 阻塞
8. N2 commit
9. N1 阻塞结束 获取锁了
- 带索引的查询条件 innodb使用行锁
DROP TABLE IF EXISTS `test_use_index`;
CREATE TABLE `test_use_index` (
`id` bigint(20) NOT NULL,
`name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
insert into test_use_index
values (1,'a'),(2,'b'),(3,'c')
1. N1 set @@autocommit=0;
2. N2 set @@autocommit=0;
3. N1 select * from test_use_index where id=1 for update
4. N2 select * from test_use_index where id=2 for update --不阻塞了
- 因为mysql行锁是锁的索引 所以虽然访问的是不同行的记录 如果使用相同的索引,还是会冲突
接着上边的表结构:
ALTER TABLE `test_use_index`
ADD INDEX `index_name` (`name`) USING BTREE ;
ALTER TABLE `test_use_index`
DROP PRIMARY KEY;
insert into test_use_index values('6','a');
select * from test_use_index

1. N1 select * from test_use_index where name='a' and id=1 for update
2. N2 select * from test_use_index where name='a' and id=6 for update -- 锁住了
3. 虽然两条for update 不是同一条记录 但是还是使用的是一个索引name:a