先上一个物体检测算法时间轴:
!()[https://upload-images.jianshu.io/upload_images/4987072-d56f272622ecc495?imageMogr2/auto-orient/strip%7CimageView2/2/w/720/format/webp]
从时间轴上看,SSD的发布是在Faster rcnn和YOLO-v1之后,YOLO-v1是one-stage检测算法开山之作,速度上碾压Faster rcnn。SSD沿用了YOLO-v1 one-stage的思想,融合了Faster rcnn的anchor-box,又提出了多尺度检测思想,最终达到了效果和速度都相对比较理想的程度,如下:
!()[https://upload-images.jianshu.io/upload_images/4987072-1e56279546be1398?imageMogr2/auto-orient/strip%7CimageView2/2/w/838/format/webp]
SSD:Single Shot MultiBox Detector 论文下载地址:https://arxiv.org/pdf/1512.02325.pdf
设计理念
SSD和YOLO一样都是采用端到端的方法,采用一个CNN网络进行检测,但采用了不同尺度的Feature Map,核心设计理念总结如下:
!(基本框架)[https://img-blog.csdn.net/20180406150216329?watermark/2/text/aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3hpYW9odTIwMjI=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70]
(1)采用多尺度特征图用于检测
CNN一般前面的feature map比较大,每个单位视野比较小,适合检测小的物体;后面的feature map相对较小,但每个单位的视野大,适合检测大的物体。
!()[https://img-blog.csdn.net/20180406150249491?watermark/2/text/aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3hpYW9odTIwMjI=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70]
(2)采用全卷积进行检测
与YOLO-v1后面接全连接层不同,SSD直接采用卷积对提取不同大小的feature map,主要采用3*3的卷积核进行特征提取。
(3)设置先验框
在Yolo中,每个单元预测多个边界框,但是其都是相对这个单元本身(正方块),但是真实目标的形状是多变的,Yolo需要在训练过程中自适应目标的形状。
而SSD借鉴了Faster R-CNN中anchor的理念,每个单元设置尺度或者长宽比不同的先验框,预测的边界框(bounding boxes)是以这些先验框为基准的,在一定程度上减少训练难度。一般情况下,每个单元会设置多个先验框,其尺度和长宽比存在差异,如图下图所示,可以看到每个单元使用了4个不同的先验框,图片中猫和狗分别采用最适合它们形状的先验框来进行训练,后面会详细讲解训练过程中的先验框匹配原则。
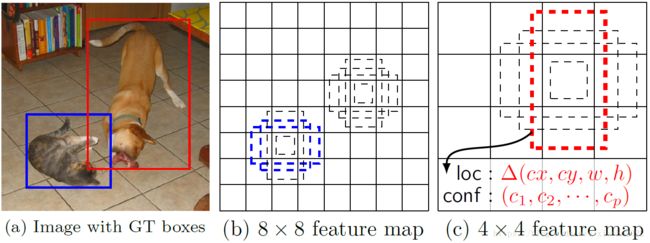
1.https://blog.csdn.net/xiaohu2022/article/details/79833786
SSD的检测值也与Yolo-v1有一些差异,但是都包括confidence和location,Yolo-v1中confidence指所预测的 box 中含有 object 的置信度和这个 box 预测的有多准两重信息,SSD中confidence指预测的各个类别的置信度。具体说一下,检测值第一部分confidence是各个类别的置信度,SSD也将背景作为了一个特殊类,若检测目标共有c个类,则SSD需要预测c+1个类别置信度。在预测过程中,置信度最高的那个类别就是单签边界框所属的类别,若对应的背景类别置信度最高,则该边界框中不包含目标。第二部分就是边框的location(cx,cy,w,h),但是边框预测值是相对于设置的先验框的offset。,其对应边界框,边界框的预测值jiushi 相对于的转换:
,,,
习惯上,我们称上面这个过程为边界框的编码(encode),预测时,你需要反向这个过程,即进行解码(decode),从预测值中得到边界框的真实位置:
,,,
综上所述,对于一个大小的特征图,共有mn个单元,每个单元设置的先验框数目记为,那么每个单元共需要个预测值,所有的单元共需要个预测值,由于SSD采用卷积做检测,所以就需要个卷积核完成这个特征图的检测过程。
网络结构
SSD采用VGG16作为基础模型,然后在VGG16的基础上新增了卷积层来获得更多的特征图以用于检测。如下图所示,上面是SSD模型,下面是Yolo-v1模型,可以明显看到SSD利用了多尺度的特征图做检测。模型的输入图片是300300(还可以是512512,其余前者网络结构没有差别,只是最后新增一个卷积层)
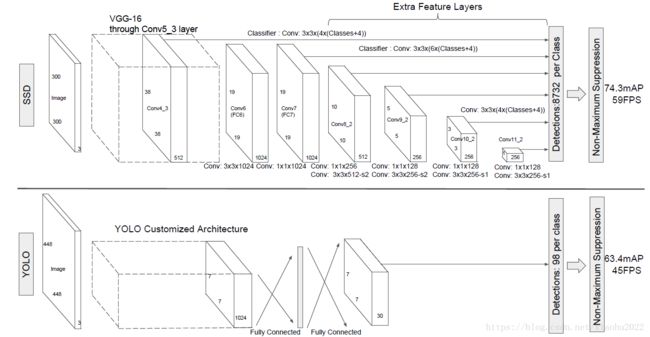
采用VGG16做基础模型,首先VGG16是在ILSVRC CLS-LOC数据集预训练。分别将VGG16的全连接层fc6和fc7转换成3×3卷积层conv6和1×1卷积层conv7,同时将池化层pool5由原来的2×2−s2变成3×3−s1(reduce特征图大小)
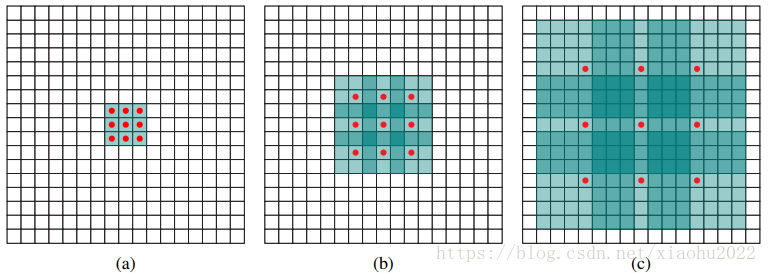
为了配合这种变化,采用了一种Atrous Algorithm,其实就是conv6采用扩展卷积或带孔卷积(Dilation Conv),其在不增加参数与模型复杂度的条件下指数级扩大卷积的视野,其使用扩张率(dilation rate)参数,来表示扩张的大小,如下图所示,(a)是普通的3×3卷积,其视野就是3×3,(b)是扩张率为2,此时视野变成7×7,(c)扩张率为4时,视野扩大为15×15,但是视野的特征更稀疏了。Conv6采用3×3大小但dilation rate=6的扩展卷积。
然后移除dropout层和fc8层,并新增一系列卷积层,在检测数据集上做finetuing。
其中VGG16中的Conv4_3层将作为用于检测的第一个特征图。conv4_3层特征图大小是38×38,但是该层比较靠前,其norm较大,所以在其后面增加了一个L2 Normalization层,以保证和后面的检测层差异不是很大,这个和Batch Normalization层不太一样,其仅仅是对每个像素点在channle维度做归一化,而Batch Normalization层是在[batch_size, width, height]三个维度上做归一化。归一化后一般设置一个可训练的放缩变量gamma,使用TF可以这样简单实现:
从后面新增的卷积层中提取Conv7,Conv8_2,Conv9_2,Conv10_2,Conv11_2作为检测所用的特征图,加上Conv4_3层,共提取了6个特征图,其大小分别是(38,38),(19,19),(10,10),(5,5),(3,3),(1,1),但是不同特征图设置的先验框数目不同(同一个特征图上每个单元设置的先验框是相同的,这里的数目指的是一个单元的先验框数目)。先验框的设置,包括尺度(或者说大小)和长宽比两个方面。对于先验框的尺度,其遵守一个线性递增规则:随着特征图大小降低,先验框尺度线性增加:
其中指的特征图个数,但却是5,因为第一层(Conv4_3层)是单独设置的,表示先验框大小相对于图片的比例,而和表示比例的最小值和最大值,paper里面取0.2和0.9,。对于第一个特征图,其先验框的尺度比例一般设置为,那么尺度为300*0.1=30。对于后面的特征图,先验框尺度按照上面公式线性增加,但是先将尺度比例先扩大100倍,此时增长步长为,这样各个特征图的为20,37,54,71,88,将这些比例除以100,然后再乘以图片大小,可以得到各个特征图的尺度为60,111,162,213,264,对于长宽比,一般选取,对于特定的长宽比,按照如下公式计算先验框的宽度和高度(后面的均指的是先验框实际尺寸,而不是尺度比例):
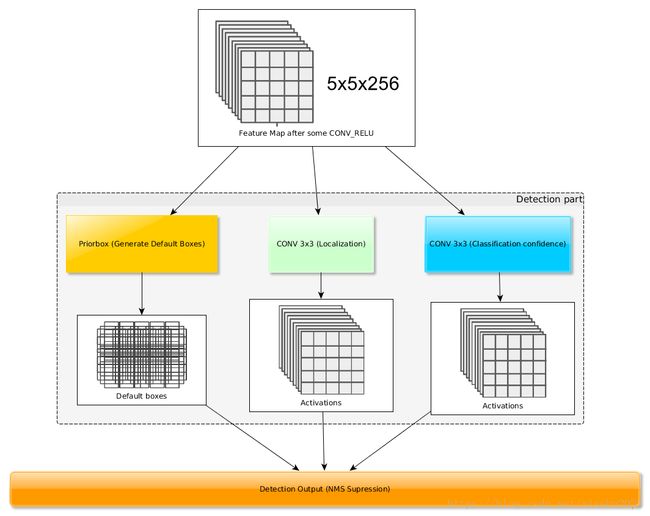
得到了特征图之后,需要对特征图进行卷积得到检测结果,下图给出了一个5×5大小的特征图的检测过程。其中Priorbox是得到先验框,前面已经介绍了生成规则。检测值包含两个部分:类别置信度和边界框位置,各采用一次3×3卷积来进行完成。令为该特征图所采用的先验框数目,那么类别置信度需要的卷积核数量为,而边界框位置需要的卷积核数量为。由于每个先验框都会预测一个边界框,所以SSD300一共可以预测38×38×4+19×19×6+10×10×6+5×5×6+3×3×4+1×1×4=8732个边界框,这是一个相当庞大的数字,所以说SSD本质上是密集采样。
训练过程
(1)先验框匹配
在训练过程中,首先要确定训练图片中的ground truth(真实目标)与哪个先验框来进行匹配,与之匹配的先验框所对应的边界框将负责预测它。在Yolo-v1中,ground truth的中心落在哪个单元格,该单元格中与其IOU最大的边界框负责预测它。但是在SSD中却完全不一样,SSD的先验框与ground truth的匹配原则主要有两点。首先,对于图片中每个ground truth,找到与其IOU最大的先验框,该先验框与其匹配,这样,可以保证每个ground truth一定与某个先验框匹配。通常称与ground truth匹配的先验框为正样本,反之,若一个先验框没有与任何ground truth进行匹配,那么该先验框只能与背景匹配,就是负样本。一个图片中ground truth是非常少的, 而先验框却很多,如果仅按第一个原则匹配,很多先验框会是负样本,正负样本极其不平衡,所以需要第二个原则。第二个原则是:对于剩余的未匹配先验框,若某个ground truth的IOU大于某个阈值(一般是0.5),那么该先验框也与这个ground truth进行匹配。这意味着某个ground truth可能与多个先验框匹配,这是可以的。但是反过来却不可以,因为一个先验框只能匹配一个ground truth,如果多个ground truth与某个先验框IOU大于阈值,那么先验框只与IOU最大的那个先验框进行匹配。第二个原则一定在第一个原则之后进行,仔细考虑一下这种情况,如果某个ground truth所对应最大IOU小于阈值,并且所匹配的先验框却与另外一个ground truth的IOU大于阈值,那么该先验框应该匹配谁,答案应该是前者,首先要确保某个ground truth一定有一个先验框与之匹配。但是,这种情况我觉得基本上是不存在的。下图为一个匹配示意图,其中绿色的GT是ground truth,红色为先验框,FP表示负样本,TP表示正样本。

尽管一个ground truth可以与多个先验框匹配,但是ground truth相对先验框还是太少了,所以负样本相对正样本会很多。为了保证正负样本尽量平衡,SSD采用了hard negative mining,就是对负样本进行抽样,抽样时按照置信度误差(预测背景的置信度越小,误差越大)进行降序排列,选取误差的较大的top-k作为训练的负样本,以保证正负样本比例接近1:3。
(2)损失函数
训练样本确定了,然后就是损失函数了。损失函数定义为位置误差(locatization loss, loc)与置信度误差(confidence loss, conf)的加权和:
其中是先验框的正样本数量,为一个指示参数,当时表示第个先验框与第个ground truth匹配,并且ground truth的类别为。为类别置信度预测值。为先验框的所对应边界框的位置预测值,而是ground truth的位置参数。对于位置误差,其采用Smooth L1 loss,定义如下:
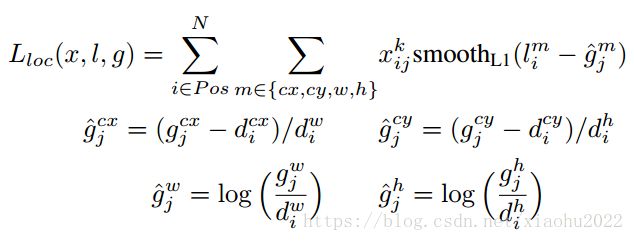
![]https://img-blog.csdn.net/20180406150937425?watermark/2/text/aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3hpYW9odTIwMjI=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70()
由于的存在,所以位置误差仅针对正样本进行计算。值得注意的是,要先对ground truth的gg进行编码得到g^,因为预测值ll也是编码值。
对于置信度误差,其采用softmax loss:

权重系数αα通过交叉验证设置为1。
(3)数据扩增
采用数据扩增(Data Augmentation)可以提升SSD的性能,主要采用的技术有水平翻转(horizontal flip),随机裁剪加颜色扭曲(random crop & color distortion),随机采集块域(Randomly sample a patch)(获取小目标训练样本),如下图所示:

预测过程
预测过程比较简单,对于每个预测框,首先根据类别置信度确定其类别(置信度最大者)与置信度值,并过滤掉属于背景的预测框。然后根据置信度阈值(如0.5)过滤掉阈值较低的预测框。对于留下的预测框进行解码,根据先验框得到其真实的位置参数(解码后一般还需要做clip,防止预测框位置超出图片)。解码之后,一般需要根据置信度进行降序排列,然后仅保留top-k(如400)个预测框。最后就是进行NMS算法,过滤掉那些重叠度较大的预测框。最后剩余的预测框就是检测结果了。
性能评估
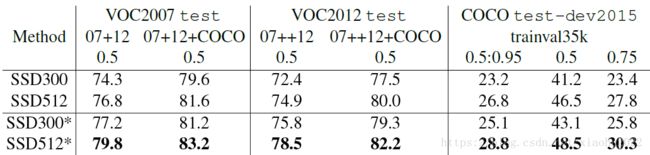
首先整体看一下SSD在VOC2007,VOC2012及COCO数据集上的性能,如下表所示。相比之下,SSD512的性能会更好一些。加*的表示使用了image expansion data augmentation(通过zoom out来创造小的训练样本)技巧来提升SSD在小目标上的检测效果,所以性能会有所提升。
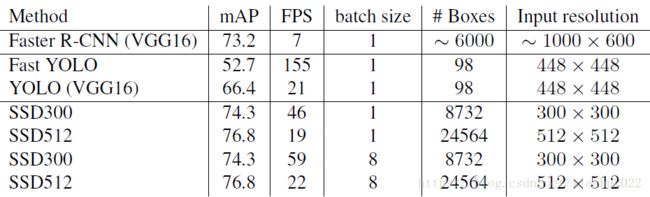
SSD与其它检测算法的对比结果(在VOC2007数据集)如下表所示,基本可以看到,SSD与Faster R-CNN有同样的准确度,并且与Yolo具有同样较快地检测速度。
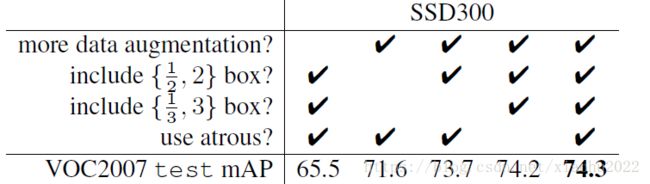
文章还对SSD的各个trick做了更为细致的分析,表3为不同的trick组合对SSD的性能影响,从表中可以得出如下结论:
- 数据扩增技术很重要,对于mAP的提升很大;
- 使用不同长宽比的先验框可以得到更好的结果;
同样的,采用多尺度的特征图用于检测也是至关重要的,这可以从下表看出:

总结
SSD在Yolo的基础上主要改进了三点:多尺度特征图,利用卷积进行检测,设置先验框。这使得SSD在准确度上比Yolo更好,而且对于小目标检测效果也相对好一点。由于很多实现细节都包含在源码里面,文中有描述不准或者错误的地方在所难免,欢迎交流指正。
参考
1.https://blog.csdn.net/xiaohu2022/article/details/79833786