论文理解《A-CCNN: ADAPTIVE CCNN FOR DENSITY ESTIMATION AND CROWD COUNTING》
论文《A-CCNN: ADAPTIVE CCNN FOR DENSITY ESTIMATION AND CROWD COUNTING》
创新点:利用
上下文信息提供更精确和适应的密度图用于场景中的人群计数;
解决问题:物体
规模变化较大以及人群之间
严重的闭塞造成人群计数是个较为麻烦的问题;
提出方法:提出A-CCNN网络——Adaptive Counting CNN
背景介绍不过多展开;
A-CCNN:
如下图fig.1显示,可以回归到对应特定部分的密度函数;
模型表现优异的几个原因:(1)处理图像中人群尺寸变动大的能力;(2)在拥塞场景中,产生局部密度图的能力;
与其他工作不同的地方:选择最高效的超参数产生CCNN模型;

CCNN: A regression model.(ref论文【1】),基于图像块外观产生对应的密度图;
ground truth density map:
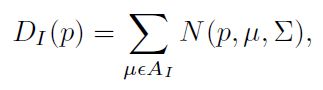
局限处:CCNN将图像整张处理;
产生模型的两个重要的HPs:the patch size和上述高斯函数的加和值;
Hydra CNN: 基于
多规模人群计数的思想based on the idea of multi-scaling crowd counting
ADAPTIVE CCNN
通过Fuzzy Inference System(FIS):它以相同的FIS语言输出值为每个图像部分提供一个合适的CCNN模型,并使用适当的HP来获得每个部分的相应的密度图;
在HPs和人群规模尺度之间存在一个关系:我们使用更小的加和值(更大的)和补丁大小来包含更小(和更大)目标的区域。
与CCNN比较,改进主要在以下几点:(1)根据patch中人规模的大小使用不同的patch size;(2)利用不同的加和值产生训练patches;
ACNN执行过程:
(1)在图片中的每一个patch中使用tiny-face检测(ref论文【2】)估计头的尺寸;
tiny-face检测方法:创建了一个粗糙的输入图像的图像金字塔,然后将缩放的输入反馈到CNN以获得模板响应。
最后的检测结果在原来的分辨率上应用非最大抑制(NMS)产生;
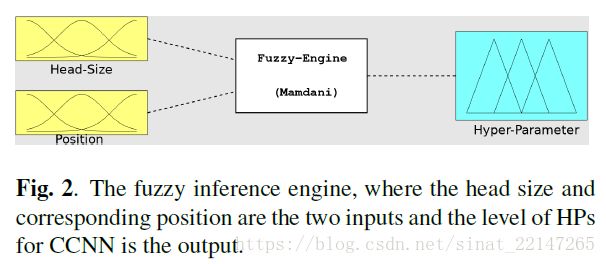
(2)通过将头部大小和相应的头部位置输入到一个模糊推理系统(FIS)中,我们对应patches
生成相应的HPs。最后,这些HPs被用来训练CCNN;
根据头部大小尺寸,小、平均、大是模糊的语言变量,上下、中、下是根据头部位置的模糊语言值。输出语言变量是高pred、中pred和低pred。
基于Mamdani方法(ref论文【3】)的模糊if-then规则用于将输入变量映射到适当的模糊输出变量
一般来说,更高(和更低的)和滑动窗口(补丁大小)的值会产生密度图,并且有更低(更高)的人数。
作为一个例子,如果FIS的输出是高Pred(中Pred,低-Pred),那么相应的CCNN将使用低(中、大)HP值进行训练。

(3)参数选择详见PDF page3;
EXPERIMENTAL RESULTS
evaluation metric:
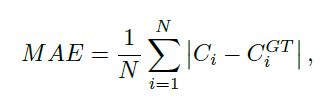
CONCLUSION
利用基于CNN的头部检测和模糊推理引擎(fuzzy inference engine)选择一个适应于输入图片每一块的最优CCNN模型;
Reference
论文【1】:D. Onoro-Rubio and R.J. Lpez-Sastre, “Towards perspective-free object counting with deep learning,” in
Proceedings of the ECCV. Springer, 2016, pp. 615–629.
Proceedings of the ECCV. Springer, 2016, pp. 615–629.
论文【2】:P. Hu and D. Ramanan, “Finding tiny faces,” in Proceedings of the CVPR. IEEE, 2017, pp. 1522–1530.
论文【3】:E.H. Mamdani, “Application of fuzzy logic to approximate reasoning using linguistic synthesis,” in Proceedings of the sixth international symposium on Multiplevalued logic. IEEE Computer Society Press, 1976, pp.
196–202.
196–202.